L3Cube-MahaNews: News-based Short Text and Long Document Classification Datasets in Marathi

0

Sign in to get full access
Overview
- This paper L3Cube-MahaNews: News-based Short Text and Long Document Classification Datasets in Marathi describes the creation of two new datasets for Marathi language text classification - one for short news articles and one for long-form documents.
- The datasets, called L3Cube-MahaNews, were constructed from a large collection of Marathi news articles and cover a range of topics including politics, sports, entertainment, and more.
- The paper also presents baseline results for several machine learning models trained on these datasets, providing a benchmark for future research and development in Marathi natural language processing.
Plain English Explanation
The researchers behind this study recognized the need for high-quality datasets to support the development of Marathi language AI models. Marathi is a widely spoken language in India, but there has been limited progress in building natural language processing (NLP) capabilities for it compared to other major Indian languages.
To address this gap, the researchers created two new Marathi text classification datasets - one focused on short news articles, the other on longer-form documents. They gathered a large collection of real Marathi news articles spanning diverse topics like politics, sports, and entertainment, then carefully annotated and organized the data into training, validation, and test sets.
By making these L3Cube-MahaNews datasets publicly available, the researchers hope to spur further advancements in Marathi NLP. The baseline machine learning model results they report provide a starting point for other researchers and developers to build upon.
Technical Explanation
The L3Cube-MahaNews dataset consists of two parts - a short text corpus and a long document corpus, both sourced from Marathi news articles.
The short text corpus contains over 50,000 news headlines and short article summaries, categorized into 10 topic classes such as politics, sports, and entertainment. The long document corpus has over 20,000 full-length news articles across the same 10 categories.
The researchers evaluated several baseline machine learning models on these datasets, including traditional approaches like support vector machines and logistic regression, as well as more advanced transformer-based models like mT5. They report classification accuracy, F1-scores, and other performance metrics, providing a benchmark for future research.
Critical Analysis
The creation of the L3Cube-MahaNews datasets represents an important step forward for Marathi NLP research. By providing high-quality, annotated text data covering a range of topics, the researchers have lowered a key barrier to entry for other groups looking to develop Marathi language models and applications.
However, the paper acknowledges several limitations of the current datasets. The data was sourced entirely from news articles, so the language and content may not be representative of other Marathi text domains like social media, books, or academic writing. Additionally, the topic categories, while broad, may not capture all the nuances and complexities of real-world news coverage.
Future work could explore expanding the dataset scope, incorporating more diverse text sources, and investigating more fine-grained topic taxonomies or other annotation schemes. There is also room to explore more advanced modeling techniques beyond the baseline results reported here, such as multilingual or transfer learning approaches.
Conclusion
The L3Cube-MahaNews datasets and baseline results presented in this paper represent an important contribution to the field of Marathi natural language processing. By providing high-quality, annotated text data and establishing performance benchmarks, the researchers have laid the groundwork for further advancements in areas like question answering, text summarization, and other Marathi language AI applications. As the Marathi NLP community continues to grow, these resources will undoubtedly prove invaluable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
L3Cube-MahaNews: News-based Short Text and Long Document Classification Datasets in Marathi
Saloni Mittal, Vidula Magdum, Omkar Dhekane, Sharayu Hiwarkhedkar, Raviraj Joshi
The availability of text or topic classification datasets in the low-resource Marathi language is limited, typically consisting of fewer than 4 target labels, with some achieving nearly perfect accuracy. In this work, we introduce L3Cube-MahaNews, a Marathi text classification corpus that focuses on News headlines and articles. This corpus stands out as the largest supervised Marathi Corpus, containing over 1.05L records classified into a diverse range of 12 categories. To accommodate different document lengths, MahaNews comprises three supervised datasets specifically designed for short text, long documents, and medium paragraphs. The consistent labeling across these datasets facilitates document length-based analysis. We provide detailed data statistics and baseline results on these datasets using state-of-the-art pre-trained BERT models. We conduct a comparative analysis between monolingual and multilingual BERT models, including MahaBERT, IndicBERT, and MuRIL. The monolingual MahaBERT model outperforms all others on every dataset. These resources also serve as Marathi topic classification datasets or models and are publicly available at https://github.com/l3cube-pune/MarathiNLP .
Read more4/30/2024

0
L3Cube-IndicNews: News-based Short Text and Long Document Classification Datasets in Indic Languages
Aishwarya Mirashi, Srushti Sonavane, Purva Lingayat, Tejas Padhiyar, Raviraj Joshi
In this work, we introduce L3Cube-IndicNews, a multilingual text classification corpus aimed at curating a high-quality dataset for Indian regional languages, with a specific focus on news headlines and articles. We have centered our work on 10 prominent Indic languages, including Hindi, Bengali, Marathi, Telugu, Tamil, Gujarati, Kannada, Odia, Malayalam, and Punjabi. Each of these news datasets comprises 10 or more classes of news articles. L3Cube-IndicNews offers 3 distinct datasets tailored to handle different document lengths that are classified as: Short Headlines Classification (SHC) dataset containing the news headline and news category, Long Document Classification (LDC) dataset containing the whole news article and the news category, and Long Paragraph Classification (LPC) containing sub-articles of the news and the news category. We maintain consistent labeling across all 3 datasets for in-depth length-based analysis. We evaluate each of these Indic language datasets using 4 different models including monolingual BERT, multilingual Indic Sentence BERT (IndicSBERT), and IndicBERT. This research contributes significantly to expanding the pool of available text classification datasets and also makes it possible to develop topic classification models for Indian regional languages. This also serves as an excellent resource for cross-lingual analysis owing to the high overlap of labels among languages. The datasets and models are shared publicly at https://github.com/l3cube-pune/indic-nlp
Read more4/30/2024
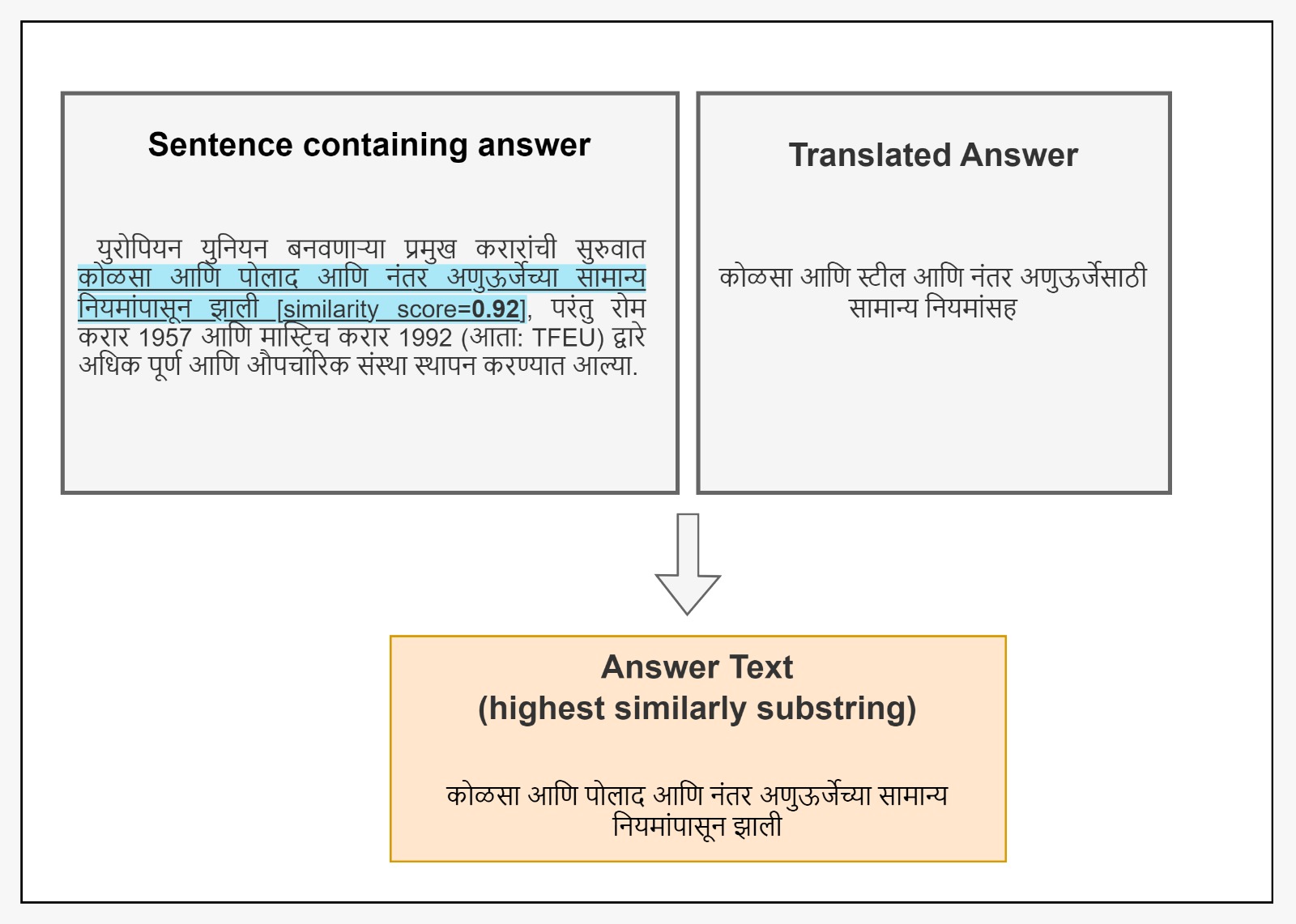
0
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
Read more4/23/2024

0
Building pre-train LLM Dataset for the INDIC Languages: a case study on Hindi
Shantipriya Parida, Shakshi Panwar, Kusum Lata, Sanskruti Mishra, Sambit Sekhar
Large language models (LLMs) demonstrated transformative capabilities in many applications that require automatically generating responses based on human instruction. However, the major challenge for building LLMs, particularly in Indic languages, is the availability of high-quality data for building foundation LLMs. In this paper, we are proposing a large pre-train dataset in Hindi useful for the Indic language Hindi. We have collected the data span across several domains including major dialects in Hindi. The dataset contains 1.28 billion Hindi tokens. We have explained our pipeline including data collection, pre-processing, and availability for LLM pre-training. The proposed approach can be easily extended to other Indic and low-resource languages and will be available freely for LLM pre-training and LLM research purposes.
Read more7/16/2024