LangSuitE: Planning, Controlling and Interacting with Large Language Models in Embodied Text Environments

0

Sign in to get full access
Overview
- This paper introduces LangSuit·E, a system that allows users to plan, control, and interact with large language models (LLMs) in embodied text environments.
- LangSuit·E combines language models with interactive virtual environments, enabling users to complete tasks and explore digital worlds through natural language interactions.
- The system aims to enhance the capabilities of LLMs by grounding them in rich, interactive environments, and to enable more natural, intuitive interactions between humans and AI systems.
Plain English Explanation
LangSuit·E is a new technology that lets people use language to control and interact with large language models (LLMs) in virtual, text-based environments. Instead of just typing commands, users can have natural conversations with the AI system and complete tasks or explore digital worlds.
The key idea is to combine the power of LLMs, which can understand and generate human-like language, with interactive virtual environments. This allows the language models to be grounded in a rich, dynamic context, rather than just operating on isolated text. Users can then use everyday language to direct the AI, make plans, and explore the virtual world.
This approach aims to make interactions with AI systems more natural and intuitive, bridging the gap between human and machine intelligence. By coupling language models with embodied environments, the researchers hope to enhance the capabilities of LLMs and enable more seamless collaborations between people and AI.
Technical Explanation
The LangSuit·E system combines large language models (LLMs) with interactive, text-based virtual environments. The user can issue natural language commands and queries, which the LLM interprets and uses to navigate, manipulate, and explore the virtual world.
The system architecture includes several key components:
- Language Model: A large, pre-trained language model that can understand and generate human-like text.
- Environment Model: A model that represents the interactive, text-based virtual environment, including objects, characters, and spatial relationships.
- Planning and Control Module: This module translates the user's natural language input into actionable plans and controls for navigating and interacting with the virtual environment.
- Interaction Interface: A user-friendly interface that allows the human to communicate with the system using natural language and receive feedback and responses from the AI.
The researchers conducted experiments to evaluate the performance of LangSuit·E on a range of tasks, including navigation, object manipulation, and open-ended exploration. The results demonstrate the system's ability to effectively ground language models in embodied, interactive environments, enabling more natural and intuitive interactions between humans and AI.
Critical Analysis
The LangSuit·E approach represents an important step forward in the field of embodied AI, as it seeks to address some of the limitations of traditional language models by grounding them in rich, interactive contexts.
One potential limitation of the system is the reliance on pre-defined virtual environments, which may limit the flexibility and generalizability of the approach. The researchers mention the need to explore more open-ended, dynamic environments that can better capture the complexity of the real world.
Additionally, the paper does not delve deeply into the specific techniques used for planning and control within the embodied environment, nor does it address potential challenges related to safety, robustness, and ethical considerations when deploying such systems in real-world settings.
Further research is needed to explore the scalability of the LangSuit·E approach, its performance on more challenging tasks, and its broader implications for the field of human-AI interaction and collaboration.
Conclusion
The LangSuit·E system represents a promising step towards more natural and intuitive interactions between humans and large language models. By grounding LLMs in interactive, text-based virtual environments, the researchers have demonstrated the potential to enhance the capabilities of these models and enable more seamless collaboration between people and AI.
As the field of embodied AI continues to evolve, the insights and approaches introduced in this paper could have significant implications for the development of more intelligent, responsive, and user-friendly AI systems that can better assist and collaborate with humans in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LangSuitE: Planning, Controlling and Interacting with Large Language Models in Embodied Text Environments
Zixia Jia, Mengmeng Wang, Baichen Tong, Song-Chun Zhu, Zilong Zheng
Recent advances in Large Language Models (LLMs) have shown inspiring achievements in constructing autonomous agents that rely on language descriptions as inputs. However, it remains unclear how well LLMs can function as few-shot or zero-shot embodied agents in dynamic interactive environments. To address this gap, we introduce LangSuitE, a versatile and simulation-free testbed featuring 6 representative embodied tasks in textual embodied worlds. Compared with previous LLM-based testbeds, LangSuitE (i) offers adaptability to diverse environments without multiple simulation engines, (ii) evaluates agents' capacity to develop ``internalized world knowledge'' with embodied observations, and (iii) allows easy customization of communication and action strategies. To address the embodiment challenge, we devise a novel chain-of-thought (CoT) schema, EmMem, which summarizes embodied states w.r.t. history information. Comprehensive benchmark results illustrate challenges and insights of embodied planning. LangSuitE represents a significant step toward building embodied generalists in the context of language models.
Read more6/26/2024

0
Embodied AI in Mobile Robots: Coverage Path Planning with Large Language Models
Xiangrui Kong, Wenxiao Zhang, Jin Hong, Thomas Braunl
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and solving mathematical problems, leading to advancements in various fields. We propose an LLM-embodied path planning framework for mobile agents, focusing on solving high-level coverage path planning issues and low-level control. Our proposed multi-layer architecture uses prompted LLMs in the path planning phase and integrates them with the mobile agents' low-level actuators. To evaluate the performance of various LLMs, we propose a coverage-weighted path planning metric to assess the performance of the embodied models. Our experiments show that the proposed framework improves LLMs' spatial inference abilities. We demonstrate that the proposed multi-layer framework significantly enhances the efficiency and accuracy of these tasks by leveraging the natural language understanding and generative capabilities of LLMs. Our experiments show that this framework can improve LLMs' 2D plane reasoning abilities and complete coverage path planning tasks. We also tested three LLM kernels: gpt-4o, gemini-1.5-flash, and claude-3.5-sonnet. The experimental results show that claude-3.5 can complete the coverage planning task in different scenarios, and its indicators are better than those of the other models.
Read more7/8/2024
💬
0
Advances in Embodied Navigation Using Large Language Models: A Survey
Jinzhou Lin, Han Gao, Xuxiang Feng, Rongtao Xu, Changwei Wang, Man Zhang, Li Guo, Shibiao Xu
In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN.
Read more6/10/2024
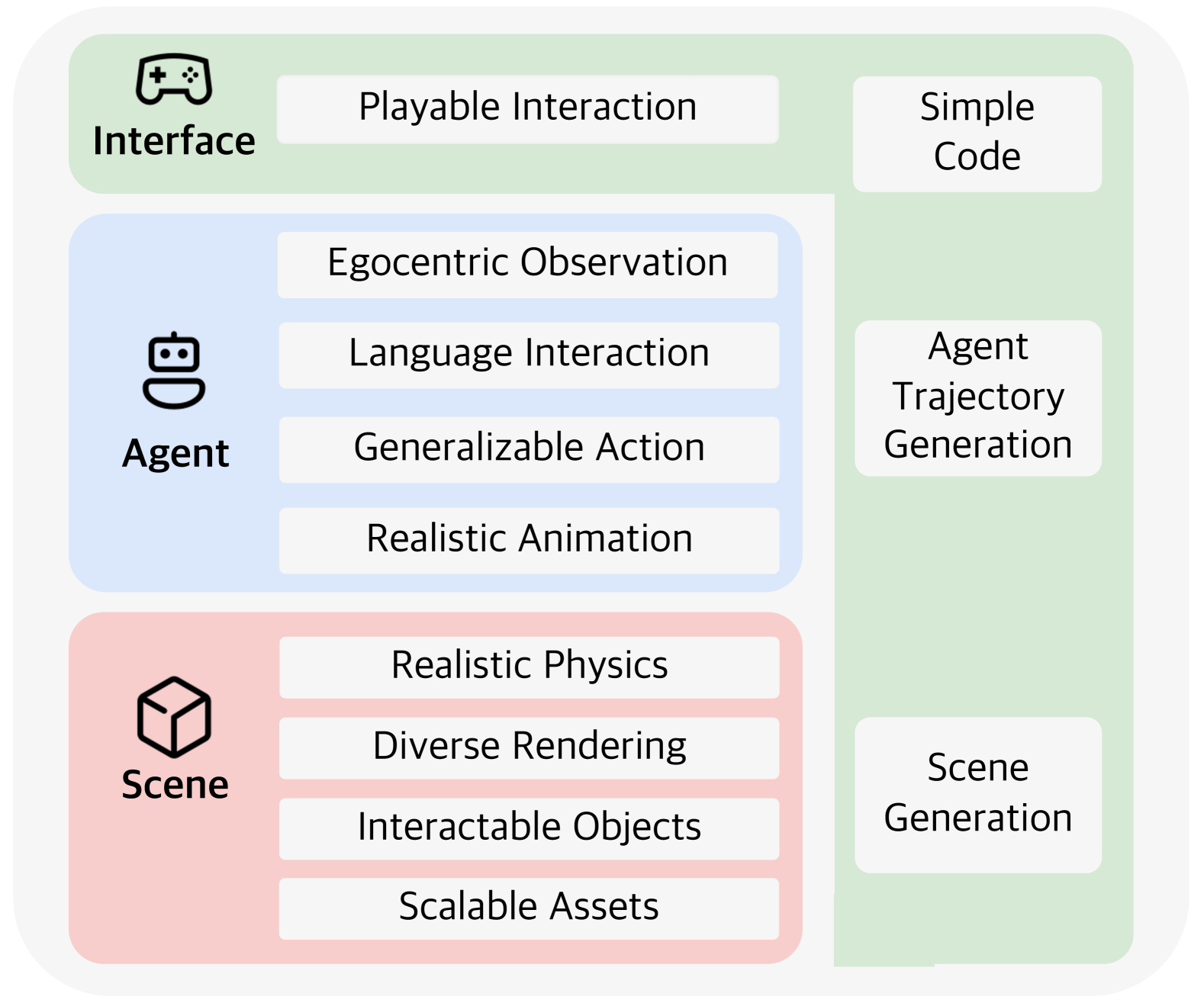
0
LEGENT: Open Platform for Embodied Agents
Zhili Cheng, Zhitong Wang, Jinyi Hu, Shengding Hu, An Liu, Yuge Tu, Pengkai Li, Lei Shi, Zhiyuan Liu, Maosong Sun
Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
Read more8/20/2024