A Language Modeling Approach to Diacritic-Free Hebrew TTS

0

Sign in to get full access
Overview
- This paper presents a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) synthesis.
- Diacritics are small marks added to letters to indicate pronunciation, which are often omitted in modern Hebrew writing.
- The researchers developed a model that can accurately predict diacritics for Hebrew text, enabling more natural-sounding TTS without the need for diacritic information.
- The proposed approach leverages large language models and outperforms previous methods for diacritic restoration, improving the quality of Hebrew TTS.
Plain English Explanation
When you read or write in Hebrew, you'll often see small marks above or below the letters, called diacritics. These diacritics provide information about how the letters should be pronounced. However, in modern Hebrew, these diacritics are frequently left out, which can make it challenging to generate natural-sounding speech from text.
The researchers in this paper tackled this problem by developing a language modeling approach to predict the missing diacritics. Their model is trained on a large amount of Hebrew text, allowing it to learn the patterns and rules that govern how diacritics are typically used. When given a piece of Hebrew text without diacritics, the model can then make an educated guess about where the diacritics should be placed, enabling more accurate and natural-sounding text-to-speech (TTS) output.
This approach builds on previous work on automatic restoration of diacritics and zero-shot TTS for Arabic, showing how language modeling techniques can be applied to improve the quality of TTS for languages like Hebrew that often omit diacritic information.
Technical Explanation
The researchers developed a diacritic prediction model based on a large pre-trained language model. They fine-tuned the language model on a dataset of Hebrew text with diacritics, allowing the model to learn the patterns and rules governing diacritic usage. When presented with a piece of Hebrew text without diacritics, the model can then predict where the diacritics should be placed, enabling more natural-sounding TTS.
The researchers evaluated their approach on several datasets, including the LDC HAVOC corpus and a dataset of modern Hebrew text. They found that their diacritic prediction model outperformed previous methods, achieving state-of-the-art performance on diacritic restoration. This, in turn, led to significant improvements in the quality of high-fidelity Hebrew TTS compared to systems that do not account for missing diacritics.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the performance of the diacritic prediction model is still not perfect, and there is room for further improvement. Additionally, the model was trained on a finite dataset of Hebrew text, which may not capture all the nuances and variations in diacritic usage across different genres and contexts.
Another potential issue is that the researchers did not directly evaluate the impact of their diacritic prediction model on the end-to-end TTS system. While they demonstrate improvements in diacritic restoration, the ultimate test would be to assess the perceptual quality and intelligibility of the generated speech.
Future research could explore ways to further enhance the diacritic prediction model, such as by incorporating additional linguistic features or leveraging cross-lingual transfer learning. Additionally, it would be valuable to conduct more comprehensive evaluations of the TTS system, including user studies, to better understand the practical benefits of this approach.
Conclusion
This paper presents a novel language modeling approach to address the challenge of diacritic-free Hebrew text-to-speech synthesis. By developing a model that can accurately predict missing diacritics, the researchers have made significant strides in improving the quality and naturalness of Hebrew TTS, which is an important step towards more accessible and engaging spoken language technologies for Hebrew speakers.
The techniques and insights from this research could also be applicable to other language communities that face similar challenges with missing diacritic information, highlighting the potential for language modeling to enhance a wide range of speech technology applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Language Modeling Approach to Diacritic-Free Hebrew TTS
Amit Roth, Arnon Turetzky, Yossi Adi
We tackle the task of text-to-speech (TTS) in Hebrew. Traditional Hebrew contains Diacritics, which dictate the way individuals should pronounce given words, however, modern Hebrew rarely uses them. The lack of diacritics in modern Hebrew results in readers expected to conclude the correct pronunciation and understand which phonemes to use based on the context. This imposes a fundamental challenge on TTS systems to accurately map between text-to-speech. In this work, we propose to adopt a language modeling Diacritics-Free approach, for the task of Hebrew TTS. The model operates on discrete speech representations and is conditioned on a word-piece tokenizer. We optimize the proposed method using in-the-wild weakly supervised data and compare it to several diacritic-based TTS systems. Results suggest the proposed method is superior to the evaluated baselines considering both content preservation and naturalness of the generated speech. Samples can be found under the following link: pages.cs.huji.ac.il/adiyoss-lab/HebTTS/
Read more7/18/2024
0
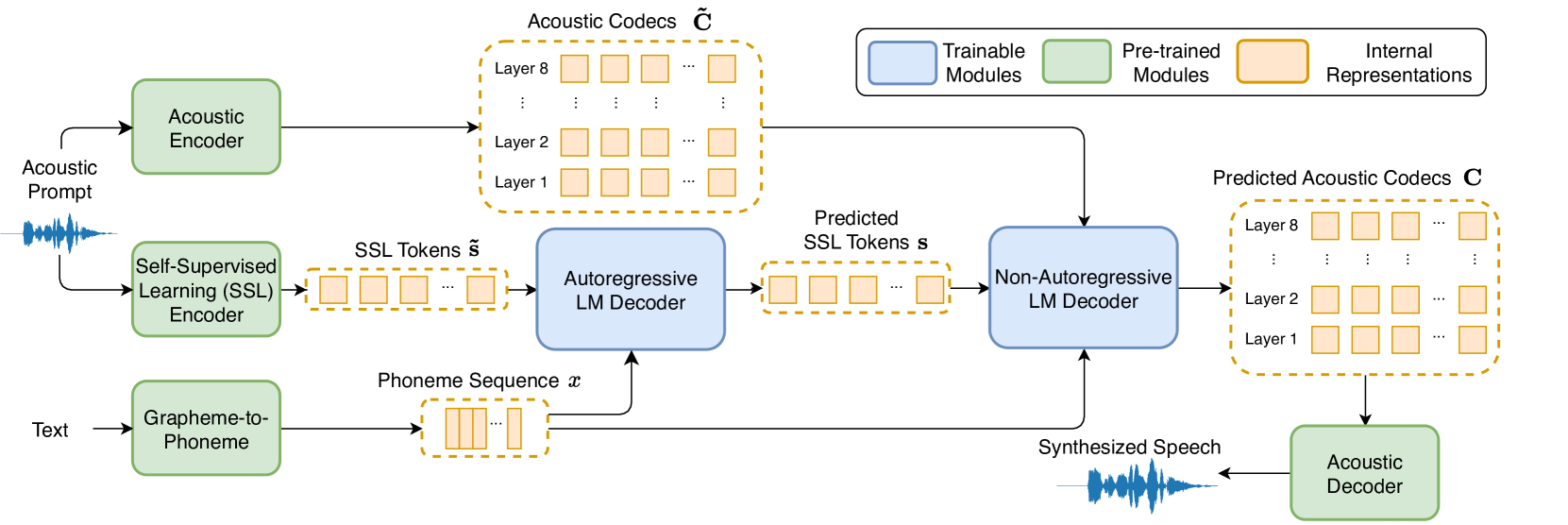
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024
🗣️
0
Automatic Restoration of Diacritics for Speech Data Sets
Sara Shatnawi, Sawsan Alqahtani, Hanan Aldarmaki
Automatic text-based diacritic restoration models generally have high diacritic error rates when applied to speech transcripts as a result of domain and style shifts in spoken language. In this work, we explore the possibility of improving the performance of automatic diacritic restoration when applied to speech data by utilizing parallel spoken utterances. In particular, we use the pre-trained Whisper ASR model fine-tuned on relatively small amounts of diacritized Arabic speech data to produce rough diacritized transcripts for the speech utterances, which we then use as an additional input for diacritic restoration models. The proposed framework consistently improves diacritic restoration performance compared to text-only baselines. Our results highlight the inadequacy of current text-based diacritic restoration models for speech data sets and provide a new baseline for speech-based diacritic restoration.
Read more4/9/2024

0
Towards Zero-Shot Text-To-Speech for Arabic Dialects
Khai Duy Doan, Abdul Waheed, Muhammad Abdul-Mageed
Zero-shot multi-speaker text-to-speech (ZS-TTS) systems have advanced for English, however, it still lags behind due to insufficient resources. We address this gap for Arabic, a language of more than 450 million native speakers, by first adapting a sizeable existing dataset to suit the needs of speech synthesis. Additionally, we employ a set of Arabic dialect identification models to explore the impact of pre-defined dialect labels on improving the ZS-TTS model in a multi-dialect setting. Subsequently, we fine-tune the XTTSfootnote{https://docs.coqui.ai/en/latest/models/xtts.html}footnote{https://medium.com/machine-learns/xtts-v2-new-version-of-the-open-source-text-to-speech-model-af73914db81f}footnote{https://medium.com/@erogol/xtts-v1-techincal-notes-eb83ff05bdc} model, an open-source architecture. We then evaluate our models on a dataset comprising 31 unseen speakers and an in-house dialectal dataset. Our automated and human evaluation results show convincing performance while capable of generating dialectal speech. Our study highlights significant potential for improvements in this emerging area of research in Arabic.
Read more7/9/2024