Large Language Model for Multi-Domain Translation: Benchmarking and Domain CoT Fine-tuning

0

Sign in to get full access
Overview
- This paper explores the use of large language models for multi-domain translation tasks.
- It presents a benchmarking framework and a novel fine-tuning technique called Domain CoT (Continuum of Tasks) to improve model performance.
- The research aims to address the challenge of adapting language models to perform well across diverse translation domains.
Plain English Explanation
Large language models have shown impressive capabilities in natural language processing tasks, but they can struggle to perform well across a wide range of specialized domains, such as legal, medical, or technical translation. This is because the training data for these models is often broad and general, and may not capture the nuances and terminology specific to certain domains.
The researchers in this paper propose a solution to this problem. They develop a benchmarking framework to evaluate the performance of large language models on multi-domain translation tasks. This allows them to identify the strengths and weaknesses of different models across various domains.
They then introduce a novel fine-tuning technique called Domain CoT (Continuum of Tasks). The idea behind this approach is to gradually expose the language model to a sequence of related translation tasks, gradually increasing the model's understanding of the specific domain. This helps the model adapt more effectively to the nuances of each domain, without completely forgetting its initial, more general language understanding capabilities.
By using this Domain CoT fine-tuning approach, the researchers are able to improve the performance of large language models on multi-domain translation tasks, making them more versatile and useful for a wider range of real-world applications.
Technical Explanation
The paper begins by presenting a benchmarking framework for evaluating the performance of large language models on multi-domain translation tasks. This framework includes a diverse set of translation datasets spanning various domains, such as legal, medical, and technical content.
The researchers then introduce a novel fine-tuning technique called Domain CoT (Continuum of Tasks). This approach involves gradually exposing the language model to a sequence of related translation tasks, starting with a general domain and progressively moving towards more specialized, domain-specific tasks. This gradual adaptation helps the model learn the nuances of each domain without completely forgetting its initial, more general language understanding capabilities.
The researchers evaluate the effectiveness of their Domain CoT fine-tuning approach by comparing it to other fine-tuning strategies, such as standard fine-tuning and multi-task learning. The results show that the Domain CoT approach outperforms these other methods, leading to significant improvements in the model's performance on multi-domain translation tasks.
Critical Analysis
The paper presents a well-designed and thorough evaluation of large language models for multi-domain translation tasks. The benchmarking framework is comprehensive, covering a diverse set of domains, which is crucial for assessing the real-world applicability of these models.
The Domain CoT fine-tuning approach is a novel and promising solution to the challenge of adapting language models to specialized domains. The gradual exposure to related tasks seems to be an effective way of helping the model learn domain-specific nuances without forgetting its general language understanding.
However, the paper does not address potential limitations or caveats of this approach. For example, it would be valuable to understand how the Domain CoT fine-tuning scales to an even larger number of domains, or how it performs on completely novel domains that were not part of the original training or fine-tuning process.
Additionally, the paper does not explore the interpretability or explainability of the fine-tuned models. Understanding the internal mechanisms and decision-making processes of these models could provide valuable insights for further improving their performance and robustness.
Conclusion
This paper presents a significant contribution to the field of multi-domain translation using large language models. The benchmarking framework and the Domain CoT fine-tuning approach demonstrate the potential for these models to be adapted to a wide range of specialized domains, improving their practical utility in real-world applications.
The research highlights the importance of tailoring language models to specific tasks and domains, rather than relying on a one-size-fits-all approach. By continuing to refine and expand these techniques, researchers can unlock the full potential of large language models for diverse translation and language understanding challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Large Language Model for Multi-Domain Translation: Benchmarking and Domain CoT Fine-tuning
Tianxiang Hu, Pei Zhang, Baosong Yang, Jun Xie, Derek F. Wong, Rui Wang
Achieving consistent high-quality machine translation (MT) across diverse domains remains a significant challenge, primarily due to the limited and imbalanced parallel training data available in various domains. While large language models (LLMs) have demonstrated impressive general understanding and generation abilities, their potential in multi-domain MT is under-explored. We establish a comprehensive benchmark for multi-domain translation, featuring 25 German$Leftrightarrow$English and 22 Chinese$Leftrightarrow$English test sets respectively covering 15 domains. Our evaluation of prominent LLMs reveals a discernible performance gap against traditional MT systems, highlighting domain overfitting and catastrophic forgetting issues after fine-tuning on domain-limited corpora. To mitigate this, we propose a domain Chain of Thought (CoT) fine-tuning technique that utilizes the intrinsic multi-domain intelligence of LLMs to improve translation performance. This method inspires the LLM to perceive domain information from the source text, which then serves as a helpful hint to guide the translation process. Despite being trained on a small dataset of four domains, our CoT fine-tune approach achieves notable enhancements in translation accuracy and domain robustness than traditional fine-tuning, as evidenced by an average 1.53 BLEU score increase in over 20 German$rightarrow$English distinct out-of-domain tests.
Read more10/4/2024
0
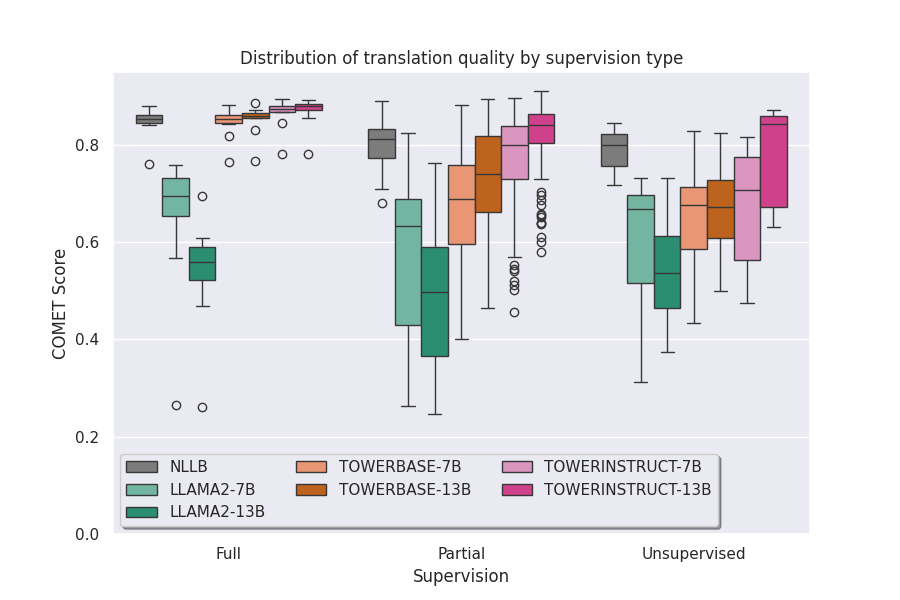
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
Read more6/3/2024

0
mCoT: Multilingual Instruction Tuning for Reasoning Consistency in Language Models
Huiyuan Lai, Malvina Nissim
Large language models (LLMs) with Chain-of-thought (CoT) have recently emerged as a powerful technique for eliciting reasoning to improve various downstream tasks. As most research mainly focuses on English, with few explorations in a multilingual context, the question of how reliable this reasoning capability is in different languages is still open. To address it directly, we study multilingual reasoning consistency across multiple languages, using popular open-source LLMs. First, we compile the first large-scale multilingual math reasoning dataset, mCoT-MATH, covering eleven diverse languages. Then, we introduce multilingual CoT instruction tuning to boost reasoning capability across languages, thereby improving model consistency. While existing LLMs show substantial variation across the languages we consider, and especially low performance for lesser resourced languages, our 7B parameter model mCoT achieves impressive consistency across languages, and superior or comparable performance to close- and open-source models even of much larger sizes.
Read more7/11/2024
📊
0
How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes
Inacio Vieira, Will Allred, S'eamus Lankford, Sheila Castilho, Andy Way
Decoder-only LLMs have shown impressive performance in MT due to their ability to learn from extensive datasets and generate high-quality translations. However, LLMs often struggle with the nuances and style required for organisation-specific translation. In this study, we explore the effectiveness of fine-tuning Large Language Models (LLMs), particularly Llama 3 8B Instruct, leveraging translation memories (TMs), as a valuable resource to enhance accuracy and efficiency. We investigate the impact of fine-tuning the Llama 3 model using TMs from a specific organisation in the software sector. Our experiments cover five translation directions across languages of varying resource levels (English to Brazilian Portuguese, Czech, German, Finnish, and Korean). We analyse diverse sizes of training datasets (1k to 207k segments) to evaluate their influence on translation quality. We fine-tune separate models for each training set and evaluate their performance based on automatic metrics, BLEU, chrF++, TER, and COMET. Our findings reveal improvement in translation performance with larger datasets across all metrics. On average, BLEU and COMET scores increase by 13 and 25 points, respectively, on the largest training set against the baseline model. Notably, there is a performance deterioration in comparison with the baseline model when fine-tuning on only 1k and 2k examples; however, we observe a substantial improvement as the training dataset size increases. The study highlights the potential of integrating TMs with LLMs to create bespoke translation models tailored to the specific needs of businesses, thus enhancing translation quality and reducing turn-around times. This approach offers a valuable insight for organisations seeking to leverage TMs and LLMs for optimal translation outcomes, especially in narrower domains.
Read more9/11/2024