Global Data Constraints: Ethical and Effectiveness Challenges in Large Language Model

0

Sign in to get full access
Overview
- This paper explores the ethical and effectiveness challenges in deploying large language models (LLMs) like GPT-4 at a global scale.
- It examines the impact of data quality and bias on the performance and safety of these models.
- The paper highlights the need for careful data curation and model development to mitigate potential harms.
Plain English Explanation
Large language models like GPT-4 have become incredibly powerful tools for generating human-like text. However, these models are only as good as the data they are trained on. The paper explores how the quality and diversity of the training data can significantly impact the model's performance and introduce biases.
For example, if the training data contains more content from certain regions or demographic groups, the model may perform better for those groups but struggle with others. This can lead to unfair or discriminatory outputs, which is a major ethical concern. The paper also examines how the model's understanding of ethics and morals can be shaped by the data it is trained on, potentially leading to undesirable behaviors.
To address these challenges, the researchers suggest that careful data curation and model development processes are needed. This includes modeling emotions and ethics in the training data, as well as evaluating the effectiveness of LLMs as tools for tasks like healthcare data annotation. By addressing these issues, the goal is to create LLMs that are more ethical, accurate, and beneficial to society.
Technical Explanation
The paper examines the challenges of deploying large language models (LLMs) like GPT-4 at a global scale, focusing on the impact of data quality and bias on the performance and safety of these models.
The researchers analyzed the training data used for LLMs and found that it often lacks diversity and representation, leading to biases in the models' outputs. For example, the data may be skewed towards certain regions, demographics, or topics, causing the models to perform better for those areas but struggle with others.
These biases can result in unfair or discriminatory outputs, which is a significant ethical concern. The paper also explores how the models' understanding of ethics and morals can be shaped by the training data, potentially leading to undesirable behaviors.
To address these challenges, the researchers suggest that a more rigorous data curation and model development process is needed. This includes carefully selecting and curating the training data to ensure diversity and representation, as well as modeling emotions and ethics in the training process.
The paper also evaluates the effectiveness of LLMs as tools for tasks like healthcare data annotation, highlighting the importance of understanding the models' limitations and potential biases.
Critical Analysis
The paper raises important concerns about the ethical and effectiveness challenges in deploying large language models at a global scale. The researchers' analysis of the impact of data quality and bias on model performance and safety is well-grounded and convincing.
However, the paper could have delved deeper into some of the specific limitations and potential issues with the proposed solutions. For example, it does not address the challenges of obtaining truly diverse and representative training data, or the complexities of modeling emotions and ethics in a way that ensures ethical and unbiased outputs.
Additionally, while the evaluation of LLMs as annotators is valuable, the paper could have explored more potential use cases and the broader implications for the deployment of these models in various domains, such as healthcare.
Overall, the paper provides a strong foundation for understanding the critical issues surrounding the global deployment of large language models, and the need for rigorous data curation and model development processes to mitigate potential harms. However, further research and discussion are needed to fully address the complexities and challenges in this field.
Conclusion
This paper highlights the important ethical and effectiveness challenges in deploying large language models like GPT-4 on a global scale. It emphasizes the need for careful data curation and model development to address issues of bias, fairness, and safety.
By addressing these concerns, the research aims to create LLMs that are more accurate, ethical, and beneficial to society. The insights and recommendations provided in this paper can help guide the responsible development and deployment of these powerful language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Global Data Constraints: Ethical and Effectiveness Challenges in Large Language Model
Jin Yang, Zhiqiang Wang, Yanbin Lin, Zunduo Zhao
Recent advancements in large language models (LLMs), such as GPT-4 and GPT-4o, have shown exceptional performance, especially in languages with abundant resources like English, thanks to extensive datasets that ensure robust training. Conversely, these models exhibit limitations when processing under-resourced languages such as Chinese and Korean, where issues including hallucinatory responses remain prevalent. This paper traces the roots of these disparities to the tokenization process inherent to these models. Specifically, it explores how the tokenizer vocabulary, often used to speed up the tokenization process and reduce tokens but constructed independently of the actual model training data, inadequately represents non-English languages. This misrepresentation results in the propagation of 'under-trained' or 'untrained' tokens, which perpetuate biases and pose serious concerns related to data security and ethical standards. We aim to dissect the tokenization mechanics of GPT-4o, illustrating how its simplified token-handling methods amplify these risks and offer strategic solutions to mitigate associated security and ethical issues. Through this study, we emphasize the critical need to rethink tokenization frameworks to foster more equitable and secure AI technologies.
Read more8/13/2024
0
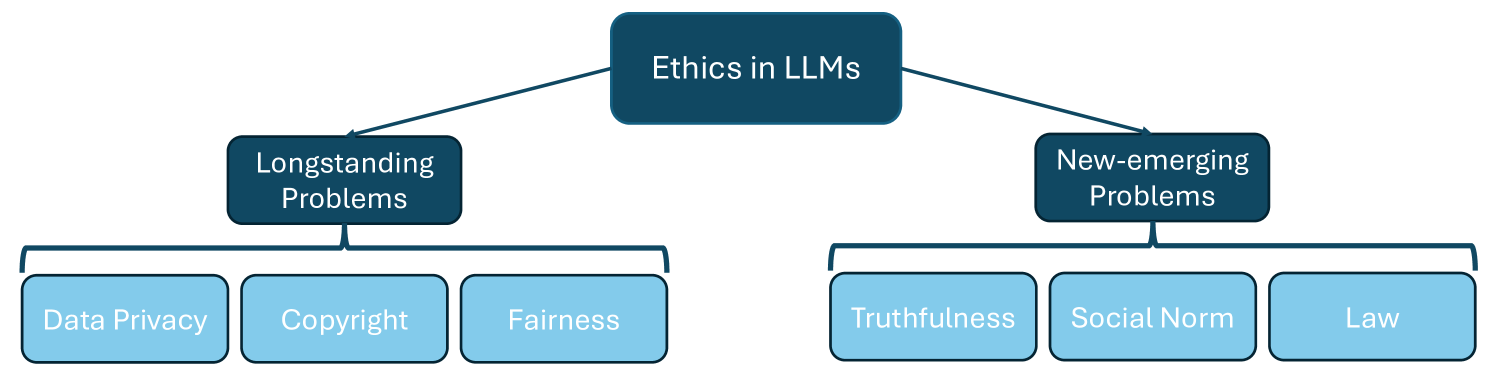
Deconstructing The Ethics of Large Language Models from Long-standing Issues to New-emerging Dilemmas
Chengyuan Deng, Yiqun Duan, Xin Jin, Heng Chang, Yijun Tian, Han Liu, Henry Peng Zou, Yiqiao Jin, Yijia Xiao, Yichen Wang, Shenghao Wu, Zongxing Xie, Kuofeng Gao, Sihong He, Jun Zhuang, Lu Cheng, Haohan Wang
Large Language Models (LLMs) have achieved unparalleled success across diverse language modeling tasks in recent years. However, this progress has also intensified ethical concerns, impacting the deployment of LLMs in everyday contexts. This paper provides a comprehensive survey of ethical challenges associated with LLMs, from longstanding issues such as copyright infringement, systematic bias, and data privacy, to emerging problems like truthfulness and social norms. We critically analyze existing research aimed at understanding, examining, and mitigating these ethical risks. Our survey underscores integrating ethical standards and societal values into the development of LLMs, thereby guiding the development of responsible and ethically aligned language models.
Read more6/11/2024
🤖
0
The global landscape of academic guidelines for generative AI and Large Language Models
Junfeng Jiao, Saleh Afroogh, Kevin Chen, David Atkinson, Amit Dhurandhar
The integration of Generative Artificial Intelligence (GAI) and Large Language Models (LLMs) in academia has spurred a global discourse on their potential pedagogical benefits and ethical considerations. Positive reactions highlight some potential, such as collaborative creativity, increased access to education, and empowerment of trainers and trainees. However, negative reactions raise concerns about ethical complexities, balancing innovation and academic integrity, unequal access, and misinformation risks. Through a systematic survey and text-mining-based analysis of global and national directives, insights from independent research, and eighty university-level guidelines, this study provides a nuanced understanding of the opportunities and challenges posed by GAI and LLMs in education. It emphasizes the importance of balanced approaches that harness the benefits of these technologies while addressing ethical considerations and ensuring equitable access and educational outcomes. The paper concludes with recommendations for fostering responsible innovation and ethical practices to guide the integration of GAI and LLMs in academia.
Read more7/1/2024
0
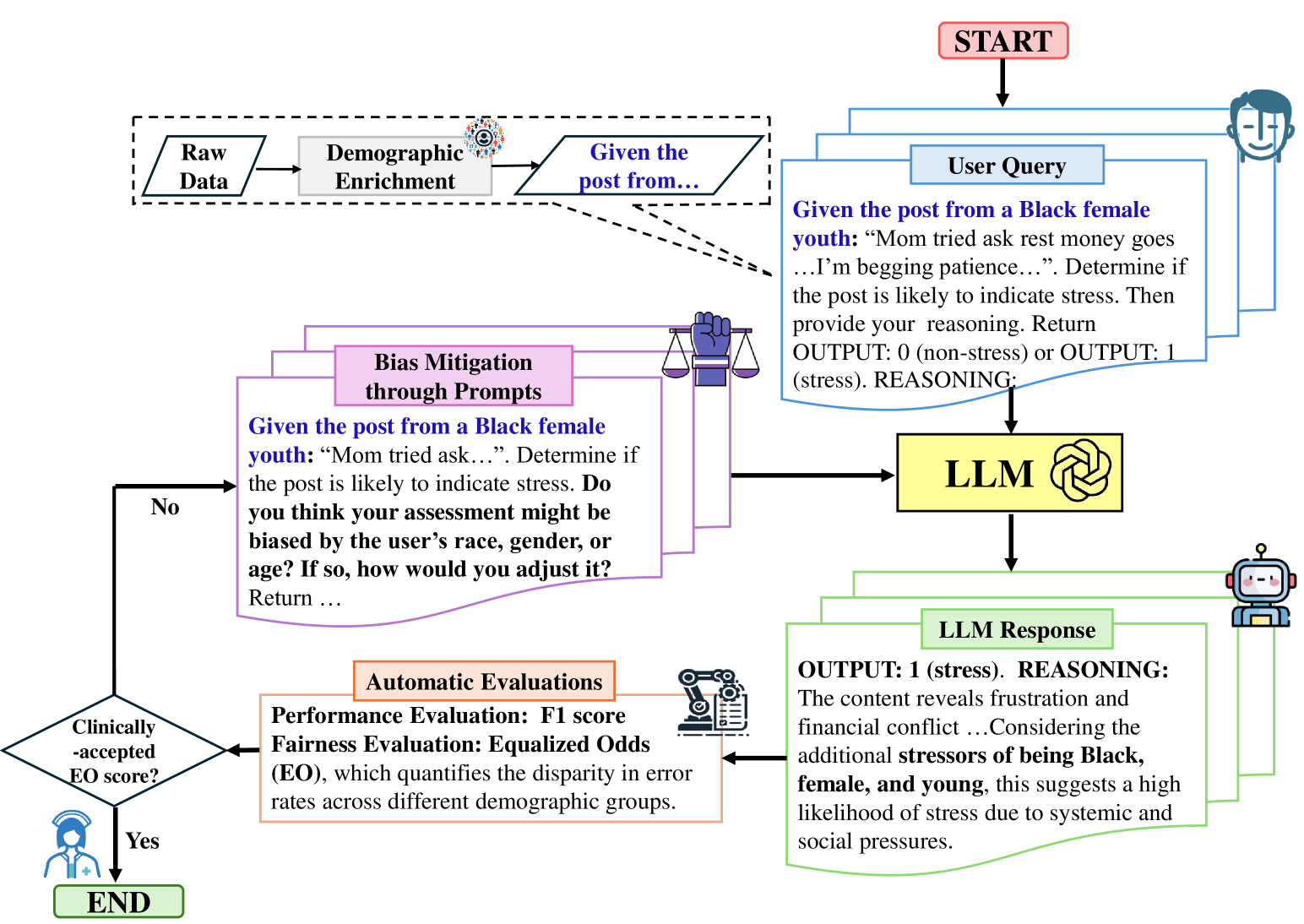
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
Read more6/21/2024