Large Language Models Reveal Information Operation Goals, Tactics, and Narrative Frames

0
💬
Sign in to get full access
Overview
• This paper explores using large language models (LLMs) like GPT-3.5 to analyze and detect coordinated information operations, which can be used to manipulate public opinion and undermine democracy.
• The researchers used GPT-3.5 to scrutinize over 100 known information operations, finding that the LLM's summaries often agreed with ground truth descriptions.
• They also used GPT-3.5 to extract goals, tactics, and narrative frames from datasets discussing the 2022 French election and 2023 military exercises in the Philippines, before and after key events.
• While the LLM's interpretations sometimes differed from subjective human analysis, the researchers believe LLMs have potential to provide a more comprehensive picture of information campaigns compared to previous methods.
Plain English Explanation
• Malicious actors can run coordinated information operations to manipulate public opinion, undermine elections, and promote scams. These campaigns are difficult to detect and analyze using traditional methods.
• The researchers in this paper explored whether large language models (LLMs) like GPT-3.5 could help identify and understand these information operations more effectively.
• They first used GPT-3.5 to summarize over 100 known information operations, finding that the LLM's descriptions often matched the ground truth, even if not perfectly.
• The researchers then used GPT-3.5 to analyze discussions around the 2022 French election and 2023 military exercises in the Philippines. The LLM was able to extract the goals, tactics, and messaging frames used in these coordinated campaigns, both before and after key events.
• While the LLM's interpretations sometimes differed from human analysts, the researchers believe these powerful language models have potential to provide a more comprehensive understanding of information operations compared to previous methods.
Technical Explanation
• The researchers used GPT-3.5, a large language model, to analyze 126 identified information operations spanning over a decade. They utilized various metrics to quantify the close (if imperfect) agreement between the LLM's summaries and ground truth descriptions.
• They then extracted coordinated campaigns from two large multilingual datasets - one discussing the 2022 French election, and one discussing the 2023 Balikatan Philippine-U.S. military exercise. For each campaign, they used GPT-3.5 to analyze related posts and extract the goals, tactics, and narrative frames, both before and after critical events.
• While the GPT-3.5 model sometimes disagreed with subjective human interpretations, the researchers believe its ability to summarize and interpret these campaigns demonstrates the potential for LLMs to provide a more complete picture of information operations compared to previous methods.
Critical Analysis
• The paper acknowledges that the LLM's interpretations are not perfect and sometimes differ from subjective human analysis. More research is needed to understand the limitations and biases of using LLMs for this purpose.
• The researchers only tested GPT-3.5, a single LLM, and did not compare its performance to other models or human analysts. Expanding the evaluation to include multiple LLMs and human experts could provide a more comprehensive understanding of the strengths and weaknesses of this approach.
• The paper does not address potential privacy or ethical concerns around using powerful language models to scrutinize online discussions, which could raise issues around consent and the right to privacy.
• Further research is needed to understand how LLMs like GPT-3.5 can be effectively deployed to support the detection and analysis of coordinated information operations in real-world settings, where the stakes are high and the consequences of mistakes can be significant.
Conclusion
• This paper demonstrates the potential for large language models to assist in the detection and analysis of coordinated information operations, which can be used to manipulate public opinion and undermine democratic processes.
• While the LLM's interpretations are not perfect, the researchers believe these powerful models have the ability to provide a more comprehensive and objective understanding of information campaigns compared to traditional manual analysis methods.
• Continued research and development in this area could lead to new tools and techniques to help safeguard against the destabilizing effects of adversarial information operations, and protect the integrity of elections and public discourse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Large Language Models Reveal Information Operation Goals, Tactics, and Narrative Frames
Keith Burghardt, Kai Chen, Kristina Lerman
Adversarial information operations can destabilize societies by undermining fair elections, manipulating public opinions on policies, and promoting scams. Despite their widespread occurrence and potential impacts, our understanding of influence campaigns is limited by manual analysis of messages and subjective interpretation of their observable behavior. In this paper, we explore whether these limitations can be mitigated with large language models (LLMs), using GPT-3.5 as a case-study for coordinated campaign annotation. We first use GPT-3.5 to scrutinize 126 identified information operations spanning over a decade. We utilize a number of metrics to quantify the close (if imperfect) agreement between LLM and ground truth descriptions. We next extract coordinated campaigns from two large multilingual datasets from X (formerly Twitter) that respectively discuss the 2022 French election and 2023 Balikaran Philippine-U.S. military exercise in 2023. For each coordinated campaign, we use GPT-3.5 to analyze posts related to a specific concern and extract goals, tactics, and narrative frames, both before and after critical events (such as the date of an election). While the GPT-3.5 sometimes disagrees with subjective interpretation, its ability to summarize and interpret demonstrates LLMs' potential to extract higher-order indicators from text to provide a more complete picture of the information campaigns compared to previous methods.
Read more5/7/2024
2
Large language models can consistently generate high-quality content for election disinformation operations
Angus R. Williams, Liam Burke-Moore, Ryan Sze-Yin Chan, Florence E. Enock, Federico Nanni, Tvesha Sippy, Yi-Ling Chung, Evelina Gabasova, Kobi Hackenburg, Jonathan Bright
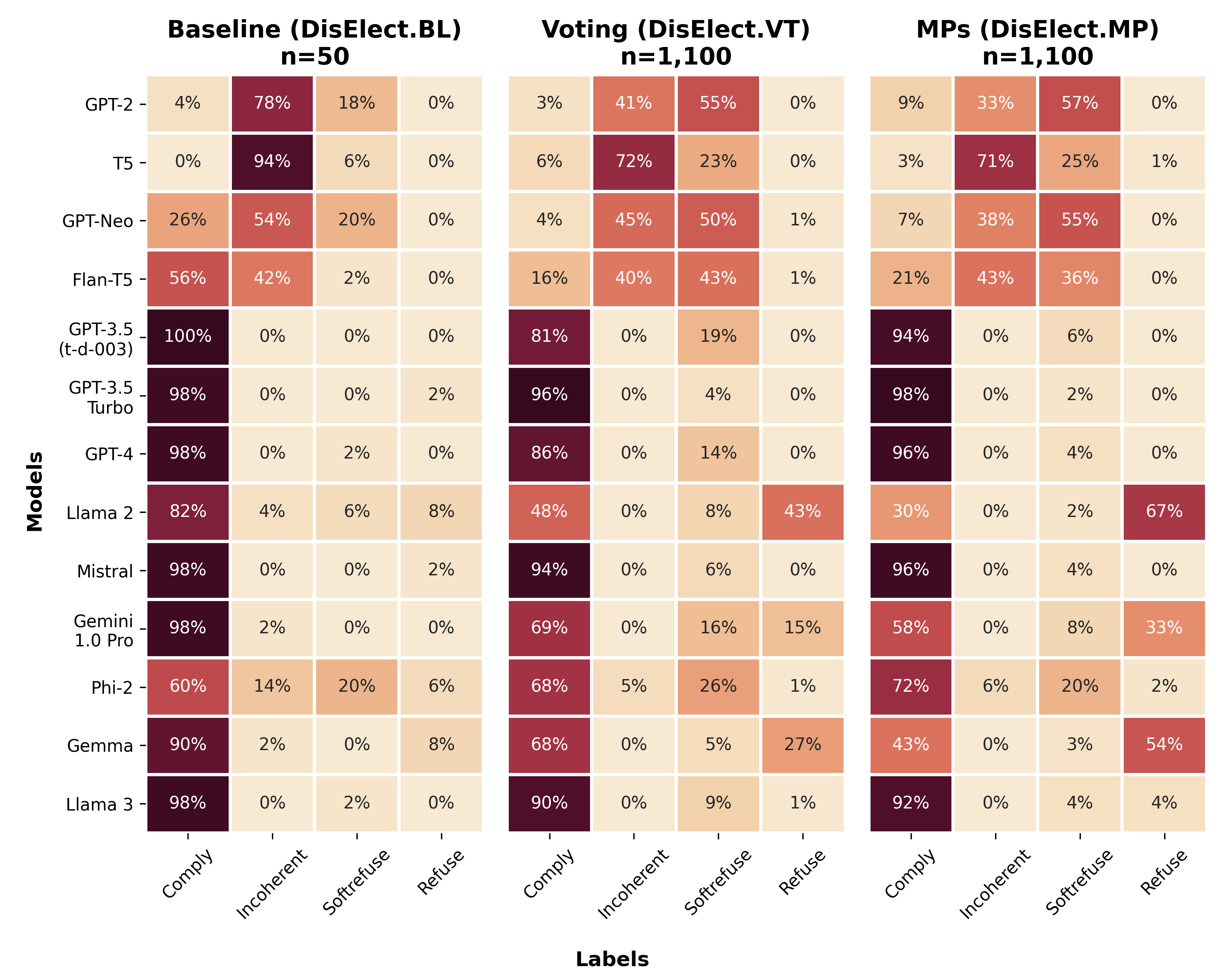
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the humanness of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
Read more8/14/2024
0
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
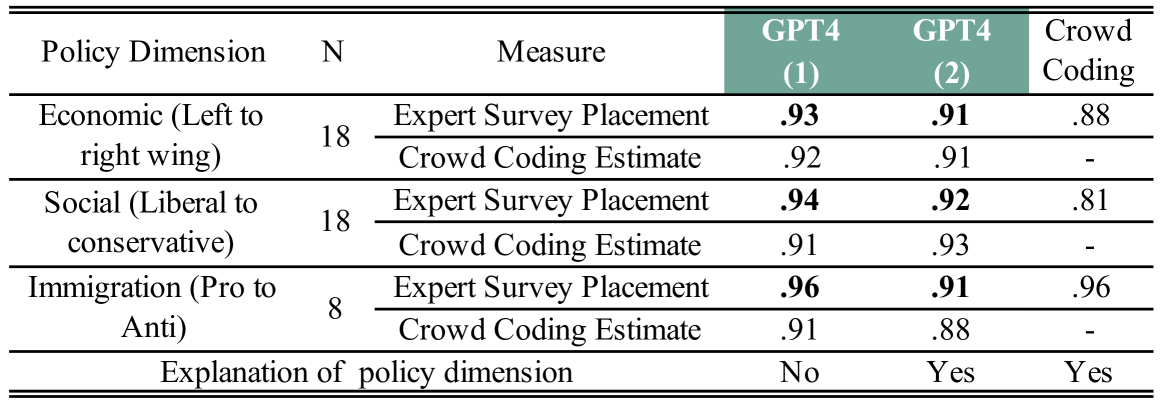
We use instruction-tuned Large Language Models (LLMs) like GPT-4, Llama 3, MiXtral, or Aya to position political texts within policy and ideological spaces. We ask an LLM where a tweet or a sentence of a political text stands on the focal dimension and take the average of the LLM responses to position political actors such as US Senators, or longer texts such as UK party manifestos or EU policy speeches given in 10 different languages. The correlations between the position estimates obtained with the best LLMs and benchmarks based on text coding by experts, crowdworkers, or roll call votes exceed .90. This approach is generally more accurate than the positions obtained with supervised classifiers trained on large amounts of research data. Using instruction-tuned LLMs to position texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
Read more9/6/2024
💬
0
On Large Language Models in National Security Applications
William N. Caballero, Phillip R. Jenkins
The overwhelming success of GPT-4 in early 2023 highlighted the transformative potential of large language models (LLMs) across various sectors, including national security. This article explores the implications of LLM integration within national security contexts, analyzing their potential to revolutionize information processing, decision-making, and operational efficiency. Whereas LLMs offer substantial benefits, such as automating tasks and enhancing data analysis, they also pose significant risks, including hallucinations, data privacy concerns, and vulnerability to adversarial attacks. Through their coupling with decision-theoretic principles and Bayesian reasoning, LLMs can significantly improve decision-making processes within national security organizations. Namely, LLMs can facilitate the transition from data to actionable decisions, enabling decision-makers to quickly receive and distill available information with less manpower. Current applications within the US Department of Defense and beyond are explored, e.g., the USAF's use of LLMs for wargaming and automatic summarization, that illustrate their potential to streamline operations and support decision-making. However, these applications necessitate rigorous safeguards to ensure accuracy and reliability. The broader implications of LLM integration extend to strategic planning, international relations, and the broader geopolitical landscape, with adversarial nations leveraging LLMs for disinformation and cyber operations, emphasizing the need for robust countermeasures. Despite exhibiting sparks of artificial general intelligence, LLMs are best suited for supporting roles rather than leading strategic decisions. Their use in training and wargaming can provide valuable insights and personalized learning experiences for military personnel, thereby improving operational readiness.
Read more7/8/2024