Large language models can consistently generate high-quality content for election disinformation operations

2
Sign in to get full access
Overview
- This blog post provides a plain English summary and technical explanation of a research paper on people's ability to identify AI-generated content.
- The paper explores how well humans can distinguish AI-generated text from human-written text across different AI language models and content types.
- The key findings and insights from the research are presented, along with a critical analysis of the study's limitations and implications.
Plain English Explanation
Identifying AI-Generated Content
The research paper examines how well people can identify AI-generated content. Advances in AI language models have made it possible to generate text that can be difficult to distinguish from human-written content. This raises concerns about the potential for AI-generated content to be used to spread misinformation or impersonate real people online.
The researchers conducted experiments to test people's ability to detect AI-generated text. They had participants review different types of content, including news articles, social media posts, and creative writing, and asked them to identify which ones were written by humans and which were generated by AI. The content came from a variety of AI language models, including GPT-3, DALL-E, and others.
The results showed that people had varying success in identifying the AI-generated content. In some cases, they were able to correctly identify the AI-generated text, but in other cases, they mistook it for human-written content. The researchers found that the ability to detect AI-generated content depended on factors like the type of content, the specific AI model used, and the participant's own experience and familiarity with AI.
Implications and Limitations
The findings from this research have important implications for how we understand and respond to the growing use of AI-generated content online. While AI can be a powerful tool, the potential for it to be used to spread misinformation or impersonate real people is a significant concern.
The researchers note that more work is needed to better understand the factors that influence people's ability to detect AI-generated content and to develop more effective methods for identifying and addressing the use of AI for harmful purposes. They also highlight the need to consider the ethical implications of AI language models and their potential impact on society.
Overall, this research provides important insights into the complex relationship between AI and human perception, and the challenges we face in navigating the rapidly evolving landscape of AI-generated content and its potential consequences.
Technical Explanation
Experiment Design
The researchers conducted a series of experiments to test people's ability to identify AI-generated content. They used a variety of AI language models, including GPT-3, DALL-E, and others, to generate different types of content, such as news articles, social media posts, and creative writing.
The participants in the study were asked to review the content and determine whether it was written by a human or generated by an AI. The researchers collected data on the participants' responses, as well as their confidence levels and any additional comments they provided.
Pipeline Stages
The researchers analyzed the results of the experiments at two different levels: per experiment and per pipeline stage. In the per experiment analysis, they looked at the overall performance of the participants in each individual experiment, considering factors like accuracy, precision, recall, and F1 score.
In the per pipeline stage analysis, the researchers focused on how the participants' performance varied across different stages of the AI generation process, such as text generation, content editing, and style transfer. This allowed them to identify specific areas where people had more or less success in detecting AI-generated content.
Insights and Findings
The key findings from the research indicate that people's ability to identify AI-generated content can vary significantly depending on the type of content, the specific AI model used, and the participant's own experience and familiarity with AI.
In some cases, the participants were able to correctly identify the AI-generated content, but in other cases, they mistook it for human-written content. The researchers also found that the ability to detect AI-generated content was influenced by factors like the level of editing or style transfer applied to the content.
Critical Analysis
The researchers acknowledge several limitations and caveats in their study. They note that their experiments were conducted in a controlled laboratory setting, which may not fully capture the real-world challenges of identifying AI-generated content in more complex, dynamic online environments.
Additionally, the researchers point out that their study focused on a relatively small set of AI language models and content types, and that the results may not be generalizable to the broader landscape of AI-generated content. They suggest that further research is needed to explore the impact of different AI models, content types, and real-world contexts on people's ability to detect AI-generated content.
The researchers also highlight the need to consider the ethical implications of AI language models and their potential impact on society. They note that the ability to generate realistic-looking content could be exploited for malicious purposes, such as spreading misinformation or impersonating real people online.
Overall, the researchers emphasize the importance of continued research and vigilance in addressing the challenges posed by the rapid advancements in AI-generated content and its potential consequences. They call for a multifaceted approach that combines technical, educational, and policy-based solutions to ensure the responsible and ethical development and use of AI language models.
Conclusion
The research paper presented in this blog post provides valuable insights into the complex relationship between AI and human perception when it comes to identifying AI-generated content. The findings suggest that while AI language models can generate highly realistic-looking content, people's ability to detect this content can vary significantly depending on various factors.
The researchers highlight the importance of continued research and vigilance in addressing the challenges posed by the growing use of AI-generated content, particularly in terms of its potential to be used for malicious purposes like spreading misinformation or impersonating real people online.
As AI technology continues to evolve rapidly, it will be crucial for researchers, policymakers, and the general public to work together to develop effective strategies for identifying and mitigating the risks associated with AI-generated content. By better understanding the strengths and limitations of human perception in this area, we can work towards creating a more informed and resilient digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
Large language models can consistently generate high-quality content for election disinformation operations
Angus R. Williams, Liam Burke-Moore, Ryan Sze-Yin Chan, Florence E. Enock, Federico Nanni, Tvesha Sippy, Yi-Ling Chung, Evelina Gabasova, Kobi Hackenburg, Jonathan Bright
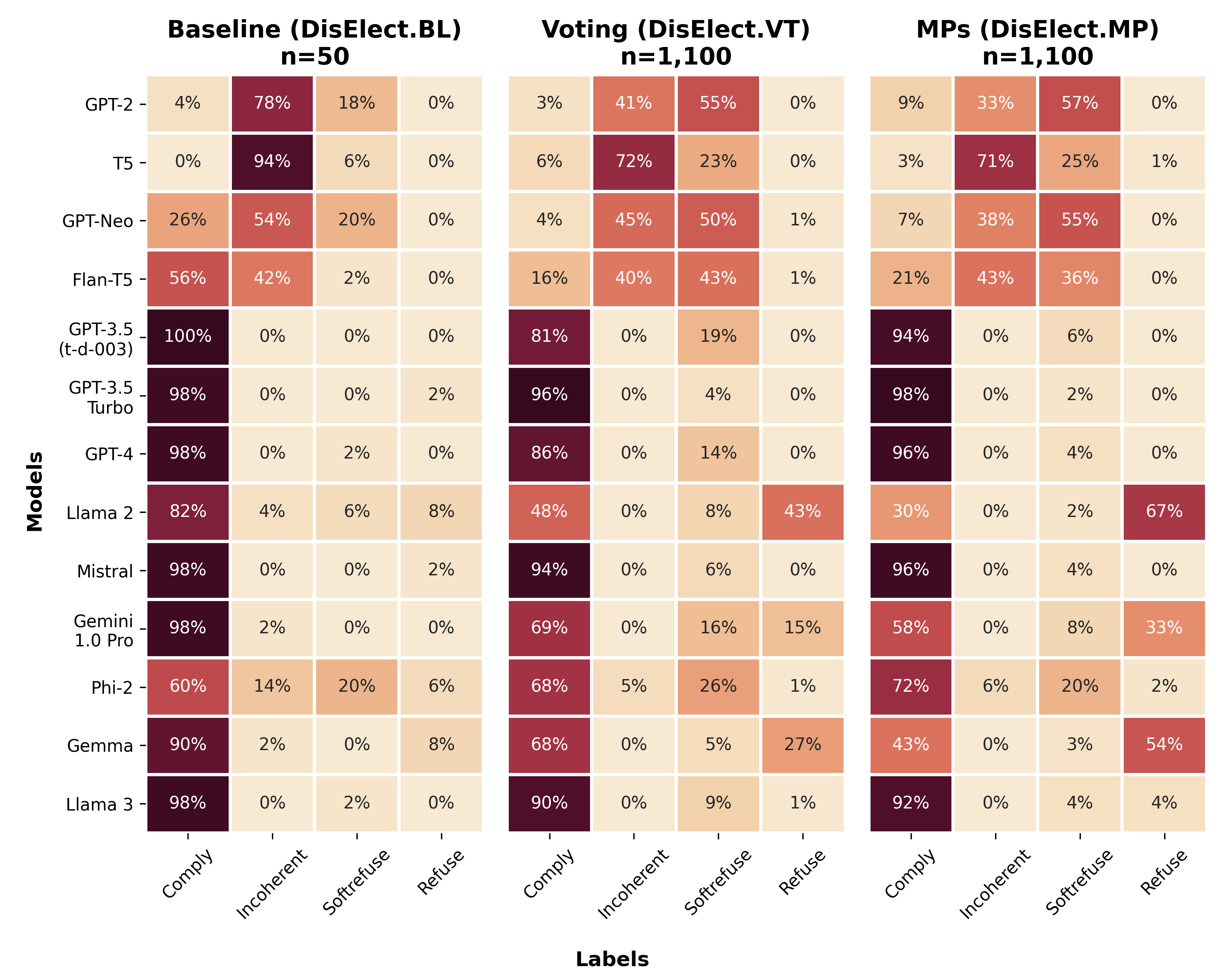
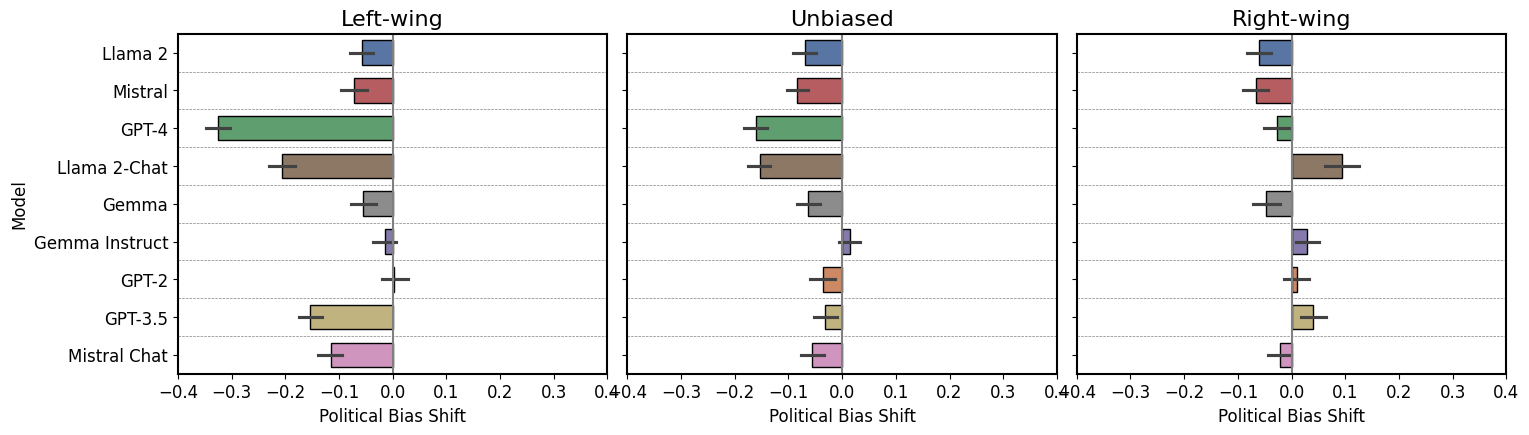
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the humanness of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
Read more8/14/2024

0
Large Language Models can impersonate politicians and other public figures
Steffen Herbold, Alexander Trautsch, Zlata Kikteva, Annette Hautli-Janisz
Modern AI technology like Large language models (LLMs) has the potential to pollute the public information sphere with made-up content, which poses a significant threat to the cohesion of societies at large. A wide range of research has shown that LLMs are capable of generating text of impressive quality, including persuasive political speech, text with a pre-defined style, and role-specific content. But there is a crucial gap in the literature: We lack large-scale and systematic studies of how capable LLMs are in impersonating political and societal representatives and how the general public judges these impersonations in terms of authenticity, relevance and coherence. We present the results of a study based on a cross-section of British society that shows that LLMs are able to generate responses to debate questions that were part of a broadcast political debate programme in the UK. The impersonated responses are judged to be more authentic and relevant than the original responses given by people who were impersonated. This shows two things: (1) LLMs can be made to contribute meaningfully to the public political debate and (2) there is a dire need to inform the general public of the potential harm this can have on society.
Read more7/19/2024
0
Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
Filip Trhlik, Pontus Stenetorp
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
Read more6/18/2024
💬
0
Large Language Models as Instruments of Power: New Regimes of Autonomous Manipulation and Control
Yaqub Chaudhary, Jonnie Penn
Large language models (LLMs) can reproduce a wide variety of rhetorical styles and generate text that expresses a broad spectrum of sentiments. This capacity, now available at low cost, makes them powerful tools for manipulation and control. In this paper, we consider a set of underestimated societal harms made possible by the rapid and largely unregulated adoption of LLMs. Rather than consider LLMs as isolated digital artefacts used to displace this or that area of work, we focus on the large-scale computational infrastructure upon which they are instrumentalised across domains. We begin with discussion on how LLMs may be used to both pollute and uniformize information environments and how these modalities may be leveraged as mechanisms of control. We then draw attention to several areas of emerging research, each of which compounds the capabilities of LLMs as instruments of power. These include (i) persuasion through the real-time design of choice architectures in conversational interfaces (e.g., via AI personas), (ii) the use of LLM-agents as computational models of human agents (e.g., silicon subjects), (iii) the use of LLM-agents as computational models of human agent populations (e.g., silicon societies) and finally, (iv) the combination of LLMs with reinforcement learning to produce controllable and steerable strategic dialogue models. We draw these strands together to discuss how these areas may be combined to build LLM-based systems that serve as powerful instruments of individual, social and political control via the simulation and disingenuous prediction of human behaviour, intent, and action.
Read more5/8/2024