Investigating Regularization of Self-Play Language Models
2404.04291
0
0
Abstract
This paper explores the effects of various forms of regularization in the context of language model alignment via self-play. While both reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) require to collect costly human-annotated pairwise preferences, the self-play fine-tuning (SPIN) approach replaces the rejected answers by data generated from the previous iterate. However, the SPIN method presents a performance instability issue in the learning phase, which can be mitigated by playing against a mixture of the two previous iterates. In the same vein, we propose in this work to address this issue from two perspectives: first, by incorporating an additional Kullback-Leibler (KL) regularization to stay at the proximity of the reference policy; second, by using the idea of fictitious play which smoothens the opponent policy across all previous iterations. In particular, we show that the KL-based regularizer boils down to replacing the previous policy by its geometric mixture with the base policy inside of the SPIN loss function. We finally discuss empirical results on MT-Bench as well as on the Hugging Face Open LLM Leaderboard.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates ways to regularize self-play language models, which are AI systems that learn by interacting with themselves.
- The researchers explore different techniques to improve the safety and reliability of these models, which have shown impressive language generation capabilities but can also exhibit undesirable behaviors.
- Key approaches covered include direct preference optimization, direct Nash optimization, and regularized best-n sampling.
Plain English Explanation
Language models are AI systems that can generate human-like text. Some of the most advanced models today are trained using a technique called self-play, where the model interacts with itself to learn how to communicate effectively. While these self-play models have shown impressive language abilities, they can also exhibit problematic behaviors, like generating harmful or biased content.
This paper explores different ways to "regularize" or control self-play language models, making them more reliable and safer. One approach is direct preference optimization, which tries to directly optimize the model to match human preferences, rather than just maximizing the likelihood of text. Another is direct Nash optimization, which treats the self-play process as a game between the model and a safety "opponent" and tries to find a stable outcome.
The researchers also investigate regularized best-n sampling, a technique that samples a diverse set of candidate text outputs from the model, rather than just picking the single most likely one. This helps reduce the model's tendency to generate repetitive or biased content.
Overall, this work aims to make self-play language models more robust and beneficial, by developing new ways to control their behavior and align them with human values.
Technical Explanation
The paper proposes several techniques to regularize self-play language models:
-
Direct preference optimization: The model is trained to directly optimize a learned preference function, rather than just maximizing the likelihood of the training data. This allows the preference function to incorporate human values and preferences.
-
Direct Nash optimization: The self-play process is treated as a game between the language model and a safety "opponent." The goal is to find a Nash equilibrium where neither player can unilaterally improve their outcome.
-
Regularized best-n sampling: Instead of always selecting the single most likely output, the model samples a diverse set of candidate outputs, which are then re-ranked using a regularized objective. This helps reduce the model's tendency to generate repetitive or biased content.
The paper also discusses the theoretical underpinnings of language model alignment and practical considerations for learning dynamics in self-play settings.
Critical Analysis
The paper provides a comprehensive exploration of various techniques for regularizing self-play language models. The proposed approaches, such as direct preference optimization and direct Nash optimization, offer promising avenues for aligning these models with human values and preferences.
One potential limitation of the work is the reliance on learned preference functions, which may not fully capture the nuances and complexities of human values. Additionally, the direct Nash optimization approach assumes the existence of a well-defined "safety opponent," which may be challenging to define in practice.
Further research is needed to better understand the long-term implications of these regularization techniques, particularly regarding their ability to maintain safety and reliability as self-play language models become increasingly sophisticated. Exploring ways to make the preference learning and optimization processes more transparent and interpretable could also be a valuable direction for future work.
Conclusion
This paper presents a thoughtful investigation of techniques for regularizing self-play language models, with the goal of improving their safety, reliability, and alignment with human values. The proposed approaches, including direct preference optimization, direct Nash optimization, and regularized best-n sampling, offer innovative ways to control the behavior of these powerful language models.
While the paper highlights the potential of these techniques, it also acknowledges the ongoing challenges in this field, such as the difficulty of fully capturing human values and the need for further research on the long-term implications of these methods. As self-play language models continue to advance, this work provides a valuable contribution to the ongoing efforts to ensure these systems are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
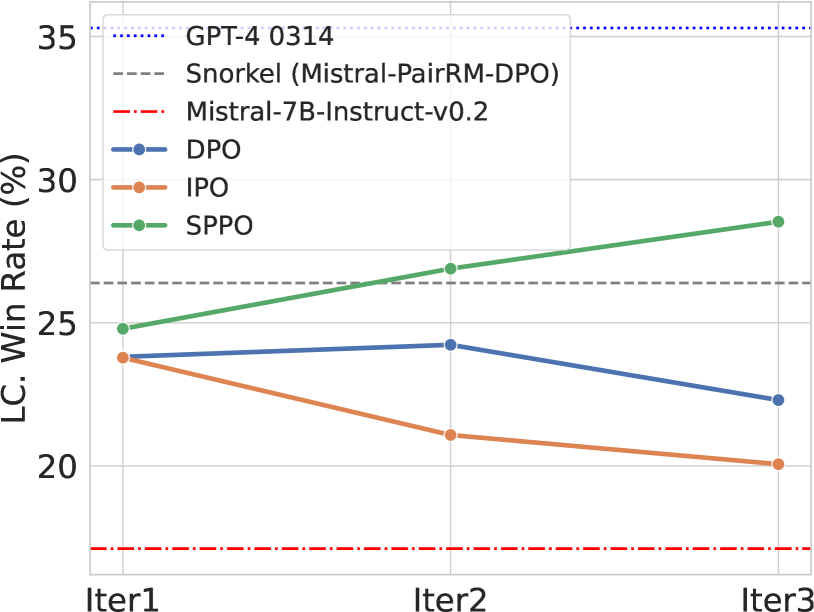
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed textit{Self-Play Preference Optimization} (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
5/2/2024

Learn Your Reference Model for Real Good Alignment
Alexey Gorbatovski, Boris Shaposhnikov, Alexey Malakhov, Nikita Surnachev, Yaroslav Aksenov, Ian Maksimov, Nikita Balagansky, Daniil Gavrilov
0
0
The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming. For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized. This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy. In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets. We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
4/16/2024
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Arsalan Sharifnassab, Sina Ghiassian, Saber Salehkaleybar, Surya Kanoria, Dale Schuurmans
0
0
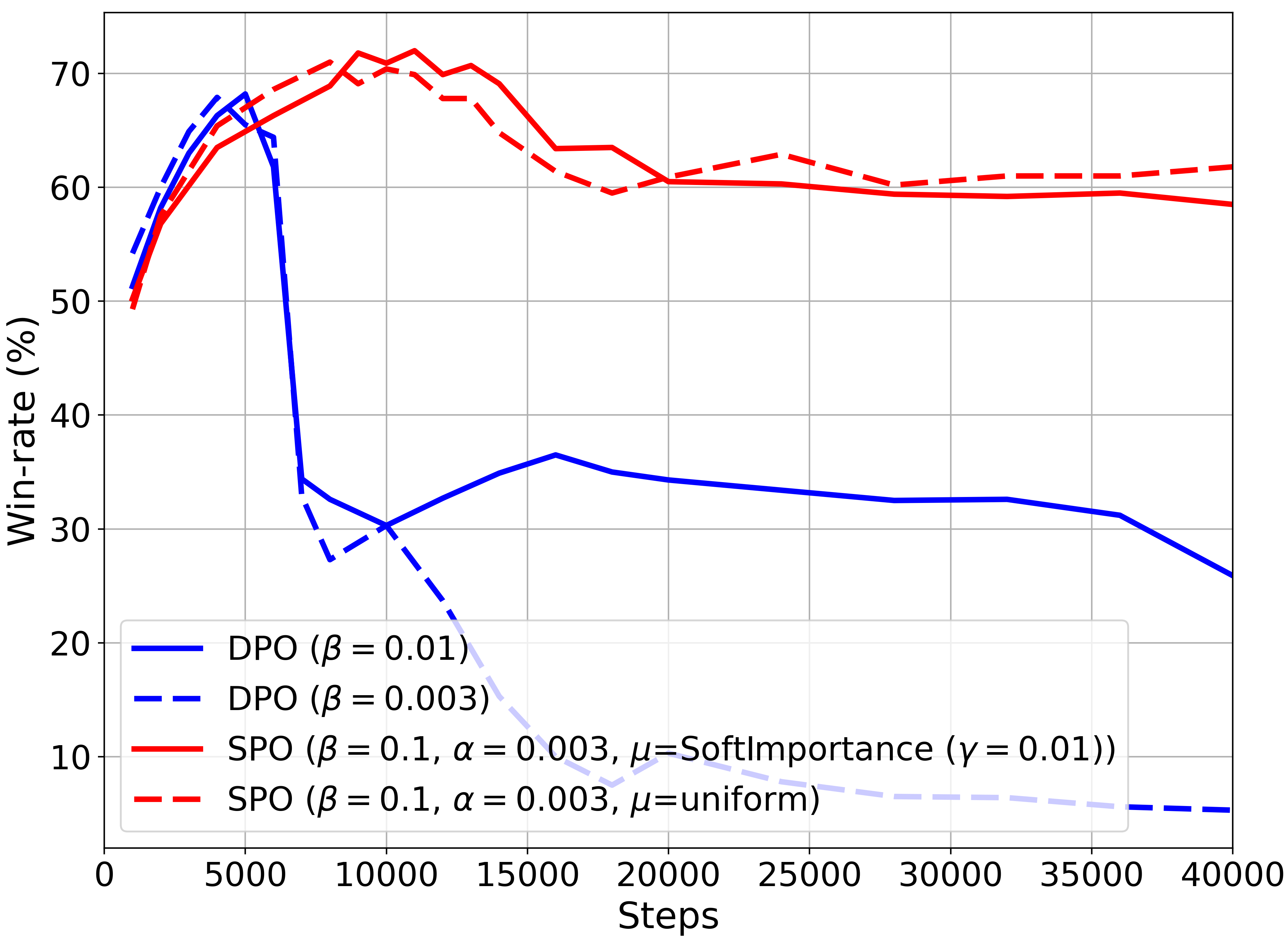
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's softness adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
5/3/2024
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024