Learning Neural Volumetric Pose Features for Camera Localization

0
Sign in to get full access
Overview
- This paper presents a novel approach for camera localization using neural volumetric pose features.
- The authors propose a method to learn informative 3D features from neural implicit representations, which can be used for efficient and accurate 6-DoF camera pose regression.
- The approach outperforms existing absolute pose regression and neural implicit feature learning methods on standard benchmarks.
Plain English Explanation
The paper focuses on the problem of camera localization, which is crucial for many applications like augmented reality, robotics, and self-driving cars. The authors introduce a new way to estimate the 6-degree-of-freedom (6-DoF) camera pose, which includes the position and orientation of the camera, from visual inputs.
The key idea is to learn informative 3D features from neural implicit representations, which are compact and efficient representations of 3D scenes. These learned features can then be used to regress the camera's pose directly, without the need for additional processing steps.
Compared to existing approaches, this method is more accurate and efficient, as it can directly predict the camera's position and orientation from the input images. The authors demonstrate that their approach outperforms other state-of-the-art absolute pose regression and neural implicit feature learning methods on standard benchmarks.
Technical Explanation
The paper introduces a novel method for camera localization that learns informative 3D features from neural implicit representations. The authors propose a neural network architecture that takes in an input image and predicts the 6-DoF camera pose directly, without the need for additional processing steps.
The core of the approach is a neural network that learns to extract 3D features from a neural implicit representation of the scene, such as a Neural Radiance Field (NeRF) or a Signed Distance Field (SDF). These features are then used to regress the camera's position and orientation.
The network is trained in an end-to-end fashion, using a combination of pose regression and self-supervised feature learning losses. The authors also introduce a novel keyframe selection strategy to improve the robustness of the pose regression.
The experimental results show that the proposed method outperforms existing absolute pose regression and neural implicit feature learning approaches on standard benchmarks, demonstrating the effectiveness of learning neural volumetric pose features for camera localization.
Critical Analysis
The paper presents a promising approach for camera localization, but there are a few potential limitations and areas for further research:
-
The method relies on the availability of a pre-computed neural implicit representation of the scene, which may not always be practical or feasible in real-world scenarios. Exploring ways to integrate the neural implicit feature learning and pose regression into a single end-to-end pipeline could be an interesting direction.
-
The authors only evaluate the approach on synthetic and small-scale real-world datasets. Assessing the performance on larger and more challenging real-world datasets would be valuable to better understand the method's practical applicability.
-
The paper does not provide a detailed analysis of the learned 3D features and their properties. Further investigation into the specific characteristics of these features and how they contribute to the improved pose regression performance could yield additional insights.
-
While the keyframe selection strategy helps improve robustness, exploring other techniques, such as fusing structure-from-motion with simulation-augmented pose, could potentially lead to even more robust and accurate camera localization.
Overall, the proposed method represents a promising step forward in camera localization, and the insights and techniques presented in this paper could inspire further advancements in this important research area.
Conclusion
This paper introduces a novel approach for camera localization that learns informative 3D features from neural implicit representations. The authors demonstrate that these learned features can be effectively used for efficient and accurate 6-DoF camera pose regression, outperforming existing state-of-the-art methods.
The key contribution of this work is the integration of neural implicit feature learning and pose regression into a unified framework, which allows for direct and efficient camera localization from visual inputs. The promising results on standard benchmarks suggest that this approach could have significant implications for a wide range of applications, such as augmented reality, robotics, and autonomous navigation.
While the paper presents some limitations and areas for further research, the overall approach represents an important step forward in the field of camera localization and could inspire future advancements in this crucial area of computer vision and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Neural Volumetric Pose Features for Camera Localization
Jingyu Lin, Jiaqi Gu, Bojian Wu, Lubin Fan, Renjie Chen, Ligang Liu, Jieping Ye
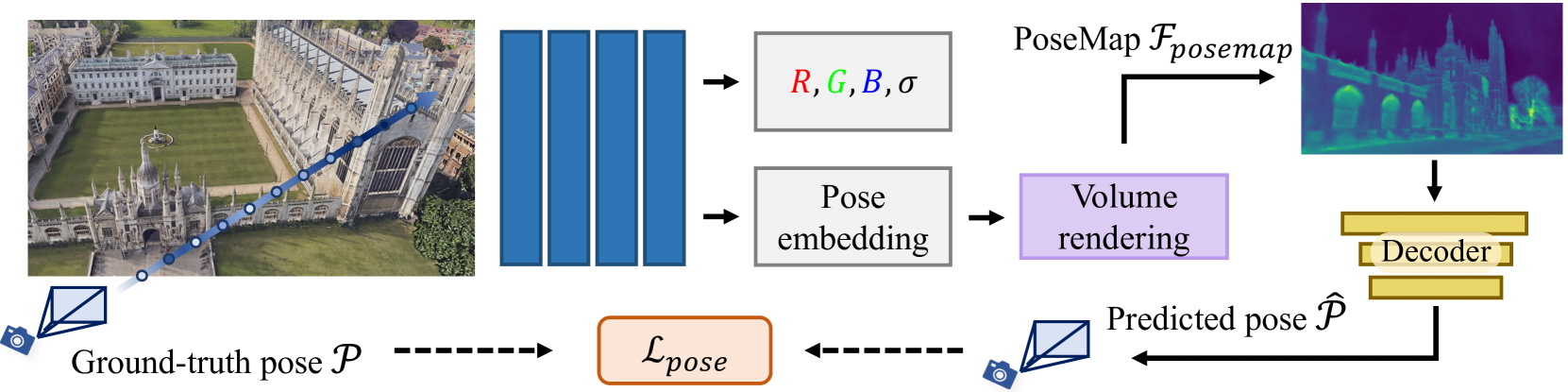
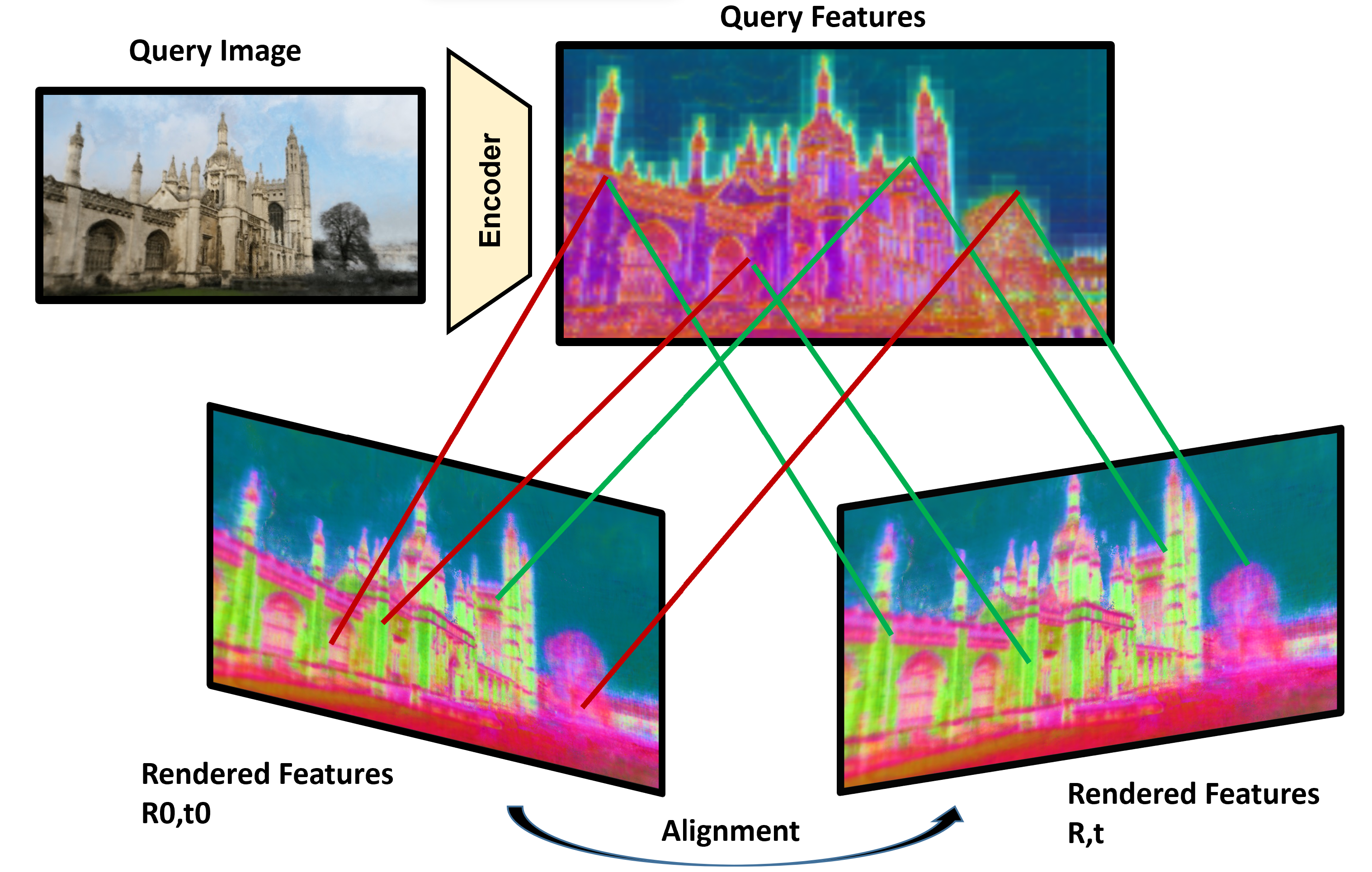
We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
Read more7/15/2024

0
Map-Relative Pose Regression for Visual Re-Localization
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, Eric Brachmann
Pose regression networks predict the camera pose of a query image relative to a known environment. Within this family of methods, absolute pose regression (APR) has recently shown promising accuracy in the range of a few centimeters in position error. APR networks encode the scene geometry implicitly in their weights. To achieve high accuracy, they require vast amounts of training data that, realistically, can only be created using novel view synthesis in a days-long process. This process has to be repeated for each new scene again and again. We present a new approach to pose regression, map-relative pose regression (marepo), that satisfies the data hunger of the pose regression network in a scene-agnostic fashion. We condition the pose regressor on a scene-specific map representation such that its pose predictions are relative to the scene map. This allows us to train the pose regressor across hundreds of scenes to learn the generic relation between a scene-specific map representation and the camera pose. Our map-relative pose regressor can be applied to new map representations immediately or after mere minutes of fine-tuning for the highest accuracy. Our approach outperforms previous pose regression methods by far on two public datasets, indoor and outdoor. Code is available: https://nianticlabs.github.io/marepo
Read more4/16/2024
0
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
Read more6/13/2024
↗️
0
Fusing Structure from Motion and Simulation-Augmented Pose Regression from Optical Flow for Challenging Indoor Environments
Felix Ott, Lucas Heublein, David Rugamer, Bernd Bischl, Christopher Mutschler
The localization of objects is a crucial task in various applications such as robotics, virtual and augmented reality, and the transportation of goods in warehouses. Recent advances in deep learning have enabled the localization using monocular visual cameras. While structure from motion (SfM) predicts the absolute pose from a point cloud, absolute pose regression (APR) methods learn a semantic understanding of the environment through neural networks. However, both fields face challenges caused by the environment such as motion blur, lighting changes, repetitive patterns, and feature-less structures. This study aims to address these challenges by incorporating additional information and regularizing the absolute pose using relative pose regression (RPR) methods. RPR methods suffer under different challenges, i.e., motion blur. The optical flow between consecutive images is computed using the Lucas-Kanade algorithm, and the relative pose is predicted using an auxiliary small recurrent convolutional network. The fusion of absolute and relative poses is a complex task due to the mismatch between the global and local coordinate systems. State-of-the-art methods fusing absolute and relative poses use pose graph optimization (PGO) to regularize the absolute pose predictions using relative poses. In this work, we propose recurrent fusion networks to optimally align absolute and relative pose predictions to improve the absolute pose prediction. We evaluate eight different recurrent units and construct a simulation environment to pre-train the APR and RPR networks for better generalized training. Additionally, we record a large database of different scenarios in a challenging large-scale indoor environment that mimics a warehouse with transportation robots. We conduct hyperparameter searches and experiments to show the effectiveness of our recurrent fusion method compared to PGO.
Read more6/11/2024