Map-Relative Pose Regression for Visual Re-Localization

0

Sign in to get full access
Overview
- This paper presents a novel approach for visual re-localization called "Map-Relative Pose Regression".
- The method aims to accurately estimate the 6-DOF (degree-of-freedom) pose of a camera relative to a known 3D map, using only a single input image.
- The key idea is to regress the camera's pose directly from the input image, without relying on traditional geometry-based techniques like feature matching and structure-from-motion.
Plain English Explanation
The paper describes a new way to figure out where a camera is located in a known 3D environment, using just a single photo. Normally, this is done by matching features in the photo to a 3D map, and then calculating the camera's position and orientation. However, the approach in this paper skips that feature matching step and instead uses machine learning to directly predict the camera's pose - its position and orientation - relative to the known 3D map.
The key innovation is that the system learns to map directly from the input photo to the camera's pose, without needing to first extract and match visual features. This can potentially make the re-localization process more robust and efficient, as it avoids some of the challenges associated with traditional geometry-based techniques, like feature matching and structure-from-motion.
Technical Explanation
The proposed "Map-Relative Pose Regression" approach takes a single input image and directly regresses the 6-DOF camera pose relative to a known 3D map. This is done using a deep neural network that is trained to learn the mapping from image to pose.
The network architecture consists of a backbone encoder, followed by several fully-connected layers that predict the 6 pose parameters (3 for position, 3 for orientation). To train the model, the authors use a combination of loss functions that encourage the predicted pose to be close to the ground truth.
The key insight is that by learning this direct mapping from image to pose, the system can bypass the traditional geometry-based pipeline of feature extraction, matching, and structure-from-motion. This can potentially make the re-localization process more robust and efficient, especially in challenging environments where traditional techniques may struggle.
Critical Analysis
The authors acknowledge several limitations and areas for further research. For example, the approach may not generalize well to environments that are significantly different from the training data. Additionally, the training process requires ground truth 6-DOF poses, which can be difficult and expensive to obtain in practice.
One potential concern is the black-box nature of the deep learning model. While the direct pose regression approach may be more efficient, it provides less interpretability than the traditional geometry-based techniques. It may be difficult to understand why the model makes certain predictions, which could be a concern in safety-critical applications.
Furthermore, the paper does not provide a detailed comparison to state-of-the-art geometry-based re-localization methods. It would be helpful to see how the proposed approach performs relative to these traditional techniques, especially in terms of accuracy, robustness, and computational efficiency.
Conclusion
Overall, the "Map-Relative Pose Regression" approach presented in this paper offers a novel and promising direction for visual re-localization. By learning to directly predict camera pose from input images, the system has the potential to be more efficient and robust than traditional geometry-based techniques, especially in challenging environments.
However, the approach also raises some questions and concerns that warrant further investigation. Researchers may need to explore ways to improve the generalization and interpretability of the deep learning model, as well as to conduct more thorough comparisons with existing re-localization methods.
If these challenges can be addressed, the proposed technique could have significant implications for a wide range of applications, from autonomous navigation to augmented reality, where accurate and efficient visual re-localization is a critical capability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Map-Relative Pose Regression for Visual Re-Localization
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, Eric Brachmann
Pose regression networks predict the camera pose of a query image relative to a known environment. Within this family of methods, absolute pose regression (APR) has recently shown promising accuracy in the range of a few centimeters in position error. APR networks encode the scene geometry implicitly in their weights. To achieve high accuracy, they require vast amounts of training data that, realistically, can only be created using novel view synthesis in a days-long process. This process has to be repeated for each new scene again and again. We present a new approach to pose regression, map-relative pose regression (marepo), that satisfies the data hunger of the pose regression network in a scene-agnostic fashion. We condition the pose regressor on a scene-specific map representation such that its pose predictions are relative to the scene map. This allows us to train the pose regressor across hundreds of scenes to learn the generic relation between a scene-specific map representation and the camera pose. Our map-relative pose regressor can be applied to new map representations immediately or after mere minutes of fine-tuning for the highest accuracy. Our approach outperforms previous pose regression methods by far on two public datasets, indoor and outdoor. Code is available: https://nianticlabs.github.io/marepo
Read more4/16/2024
0
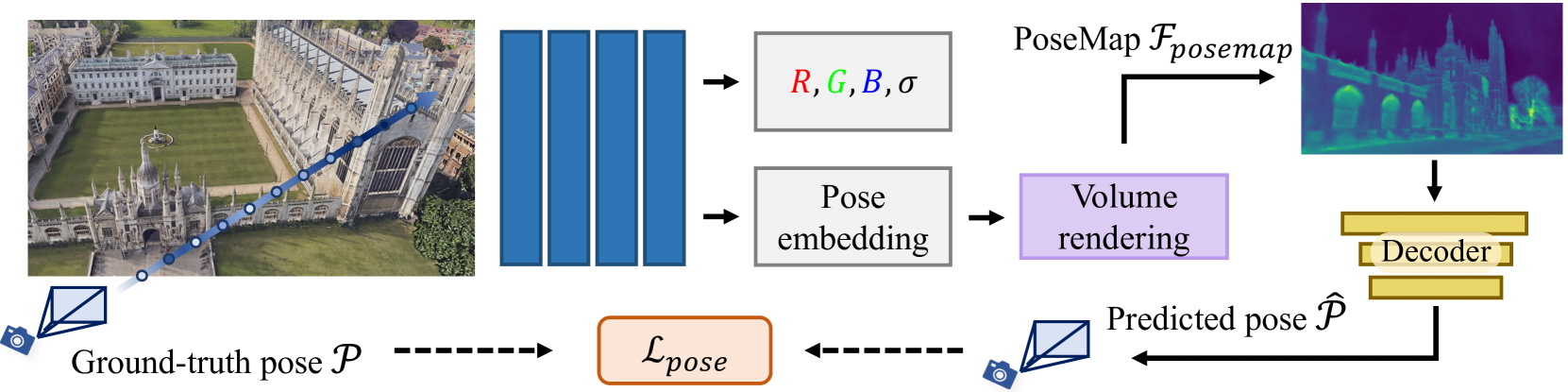
Learning Neural Volumetric Pose Features for Camera Localization
Jingyu Lin, Jiaqi Gu, Bojian Wu, Lubin Fan, Renjie Chen, Ligang Liu, Jieping Ye
We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
Read more7/15/2024
↗️
0
Fusing Structure from Motion and Simulation-Augmented Pose Regression from Optical Flow for Challenging Indoor Environments
Felix Ott, Lucas Heublein, David Rugamer, Bernd Bischl, Christopher Mutschler
The localization of objects is a crucial task in various applications such as robotics, virtual and augmented reality, and the transportation of goods in warehouses. Recent advances in deep learning have enabled the localization using monocular visual cameras. While structure from motion (SfM) predicts the absolute pose from a point cloud, absolute pose regression (APR) methods learn a semantic understanding of the environment through neural networks. However, both fields face challenges caused by the environment such as motion blur, lighting changes, repetitive patterns, and feature-less structures. This study aims to address these challenges by incorporating additional information and regularizing the absolute pose using relative pose regression (RPR) methods. RPR methods suffer under different challenges, i.e., motion blur. The optical flow between consecutive images is computed using the Lucas-Kanade algorithm, and the relative pose is predicted using an auxiliary small recurrent convolutional network. The fusion of absolute and relative poses is a complex task due to the mismatch between the global and local coordinate systems. State-of-the-art methods fusing absolute and relative poses use pose graph optimization (PGO) to regularize the absolute pose predictions using relative poses. In this work, we propose recurrent fusion networks to optimally align absolute and relative pose predictions to improve the absolute pose prediction. We evaluate eight different recurrent units and construct a simulation environment to pre-train the APR and RPR networks for better generalized training. Additionally, we record a large database of different scenarios in a challenging large-scale indoor environment that mimics a warehouse with transportation robots. We conduct hyperparameter searches and experiments to show the effectiveness of our recurrent fusion method compared to PGO.
Read more6/11/2024
🖼️
0
Leveraging Image Matching Toward End-to-End Relative Camera Pose Regression
Fadi Khatib, Yuval Margalit, Meirav Galun, Ronen Basri
This paper proposes a generalizable, end-to-end deep learning-based method for relative pose regression between two images. Given two images of the same scene captured from different viewpoints, our method predicts the relative rotation and translation (including direction and scale) between the two respective cameras. Inspired by the classical pipeline, our method leverages Image Matching (IM) as a pre-trained task for relative pose regression. Specifically, we use LoFTR, an architecture that utilizes an attention-based network pre-trained on Scannet, to extract semi-dense feature maps, which are then warped and fed into a pose regression network. Notably, we use a loss function that utilizes separate terms to account for the translation direction and scale. We believe such a separation is important because translation direction is determined by point correspondences while the scale is inferred from prior on shape sizes. Our ablations further support this choice. We evaluate our method on several datasets and show that it outperforms previous end-to-end methods. The method also generalizes well to unseen datasets.
Read more4/17/2024