Learning to Decode Collaboratively with Multiple Language Models

1

Sign in to get full access
Overview
- The paper proposes a latent-variable framework for collaborative generation using multiple language models.
- The framework allows language models to work together to generate high-quality text by sharing latent representations.
- Experiments show the approach improves performance on various text generation tasks compared to using a single language model.
Plain English Explanation
The paper introduces a new way for multiple language models to work together to generate better text.
The key idea is to have the language models share an underlying "latent representation" of the text they are trying to generate. This allows the models to collaborate and learn from each other, rather than working in isolation.
The authors demonstrate that this collaborative approach leads to improved performance on a variety of text generation tasks, compared to using a single language model on its own.
This is an interesting approach that could help large language models become even more capable at generating high-quality, coherent text. The collaborative inference technique could also have applications in encoding text and other areas.
Technical Explanation
The paper proposes a latent-variable framework for collaborative text generation using multiple language models. The key idea is to have the language models share a common latent representation of the text, which allows them to learn from each other and generate higher-quality output.
Specifically, the framework introduces a shared latent variable z that encodes the overall meaning and content of the text. Each individual language model then generates the text conditioned on this shared latent variable, as well as its own model-specific parameters.
The authors show how this framework can be trained in an unsupervised manner, using a variational autoencoder (VAE) approach. By optimizing the VAE objective, the language models learn to cooperate and produce more coherent and fluent text compared to using a single language model alone.
The paper demonstrates the effectiveness of this collaborative approach through experiments on various text generation tasks, including story continuation, dialogue response generation, and open-ended text generation. The results indicate consistent performance improvements over using a single language model.
Critical Analysis
The proposed framework is an interesting approach to leveraging multiple language models for improved text generation. By sharing a common latent representation, the models can work together to produce more coherent and contextually relevant output.
However, the paper does not deeply explore the limitations or potential downsides of this collaborative approach. For example, it is unclear how the framework would scale to very large ensembles of language models, or how it would perform in settings with conflicting or contradictory models.
Additionally, the unsupervised training process relies on the VAE objective, which can be challenging to optimize in practice. The paper does not provide a detailed analysis of the training dynamics or potential failure modes of this approach.
Further research could investigate the robustness of the collaborative framework, its generalization to different types of language models, and potential ways to make the training process more stable and reliable. Exploring applications beyond text generation, such as language understanding or multimodal tasks, could also be fruitful avenues for future work.
Conclusion
The paper presents a novel latent-variable framework for collaborative text generation using multiple language models. By sharing a common latent representation, the models can learn to work together and generate higher-quality output compared to using a single model alone.
The results demonstrate the potential of this approach to improve the capabilities of large language models in a variety of text generation tasks. While the framework has some limitations that warrant further investigation, it represents an interesting step towards more sophisticated and effective language generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Learning to Decode Collaboratively with Multiple Language Models
Shannon Zejiang Shen, Hunter Lang, Bailin Wang, Yoon Kim, David Sontag
We propose a method to teach multiple large language models (LLM) to collaborate by interleaving their generations at the token level. We model the decision of which LLM generates the next token as a latent variable. By optimizing the marginal likelihood of a training set under our latent variable model, the base LLM automatically learns when to generate itself and when to call on one of the ``assistant'' language models to generate, all without direct supervision. Token-level collaboration during decoding allows for a fusion of each model's expertise in a manner tailored to the specific task at hand. Our collaborative decoding is especially useful in cross-domain settings where a generalist base LLM learns to invoke domain expert models. On instruction-following, domain-specific QA, and reasoning tasks, we show that the performance of the joint system exceeds that of the individual models. Through qualitative analysis of the learned latent decisions, we show models trained with our method exhibit several interesting collaboration patterns, e.g., template-filling. Our code is available at https://github.com/clinicalml/co-llm.
Read more8/28/2024
💬
0
Improving Machine Translation with Large Language Models: A Preliminary Study with Cooperative Decoding
Jiali Zeng, Fandong Meng, Yongjing Yin, Jie Zhou
Contemporary translation engines based on the encoder-decoder framework have made significant strides in development. However, the emergence of Large Language Models (LLMs) has disrupted their position by presenting the potential for achieving superior translation quality. To uncover the circumstances in which LLMs excel and explore how their strengths can be harnessed to enhance translation quality, we first conduct a comprehensive analysis to assess the strengths and limitations of various commercial NMT systems and MT-oriented LLMs. Our findings indicate that neither NMT nor MT-oriented LLMs alone can effectively address all the translation issues, but MT-oriented LLMs show promise as a complementary solution to NMT systems. Building upon these insights, we propose Cooperative Decoding (CoDec), which treats NMT systems as a pretranslation model and MT-oriented LLMs as a supplemental solution to handle complex scenarios beyond the capability of NMT alone. Experimental results on the WMT22 test sets and a newly collected test set WebCrawl demonstrate the effectiveness and efficiency of CoDec, highlighting its potential as a robust solution for combining NMT systems with MT-oriented LLMs in the field of machine translation.
Read more5/28/2024
1
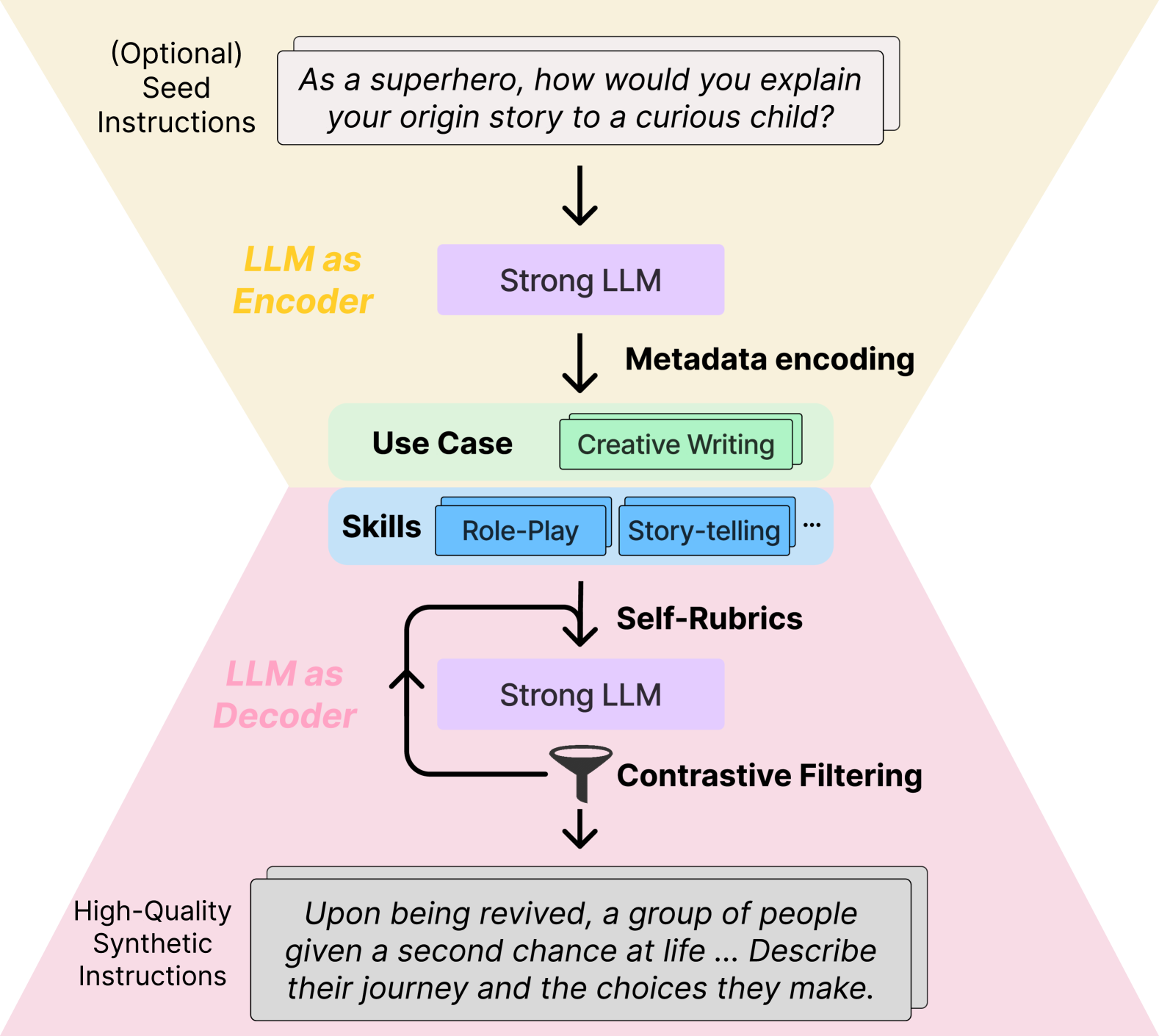
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Read more4/10/2024

0
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Benjamin Bergner, Andrii Skliar, Amelie Royer, Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4times$, with minor performance penalties of $1-2%$ for translation and summarization tasks compared to the LLM.
Read more7/18/2024