Learning to Maximize Mutual Information for Chain-of-Thought Distillation
2403.03348
0
0

Abstract
Knowledge distillation, the technique of transferring knowledge from large, complex models to smaller ones, marks a pivotal step towards efficient AI deployment. Distilling Step-by-Step~(DSS), a novel method utilizing chain-of-thought~(CoT) distillation, has demonstrated promise by imbuing smaller models with the superior reasoning capabilities of their larger counterparts. In DSS, the distilled model acquires the ability to generate rationales and predict labels concurrently through a multi-task learning framework. However, DSS overlooks the intrinsic relationship between the two training tasks, leading to ineffective integration of CoT knowledge with the task of label prediction. To this end, we investigate the mutual relationship of the two tasks from Information Bottleneck perspective and formulate it as maximizing the mutual information of the representation features of the two tasks. We propose a variational approach to solve this optimization problem using a learning-based method. Our experimental results across four datasets demonstrate that our method outperforms the state-of-the-art DSS. Our findings offer insightful guidance for future research on language model distillation as well as applications involving CoT. Codes are available at url{https://github.com/xinchen9/cot_distillation_ACL2024}.
Create account to get full access
Overview
- This paper presents a method for "chain-of-thought distillation", where a large language model is trained to produce step-by-step reasoning chains that can then be distilled into a smaller, more efficient model.
- The key idea is to use mutual information maximization to align the student model's outputs with the teacher model's reasoning steps, allowing the student to learn the teacher's thought process.
- Experiments show this approach can significantly improve the performance of smaller models on reasoning and multi-step tasks, bringing them closer to the capabilities of larger, more complex models.
Plain English Explanation
This paper describes a technique called "chain-of-thought distillation" that aims to transfer the reasoning abilities of a large, powerful language model to a smaller, more efficient model.
The core insight is that the larger model doesn't just produce a final answer - it also generates a step-by-step "chain of thought" that explains how it arrived at that answer. By maximizing the mutual information between the student model's outputs and the teacher model's reasoning steps, the student can learn to mimic the teacher's thought process.
This allows the student model to acquire the comprehensive reasoning skills of the larger model, while being much smaller and more practical to deploy. The researchers show this approach can significantly boost the performance of smaller models on complex, multi-step tasks, bridging the gap between them and their larger counterparts.
Technical Explanation
The key methodological contribution of this paper is a mutual information maximization framework for "chain-of-thought distillation". The authors train a student model to predict not just the final answer, but the step-by-step reasoning process of a larger teacher model.
Specifically, the student model is trained to maximize the mutual information between its own outputs and the reasoning steps produced by the teacher. This encourages the student to mimic the thought patterns of the teacher, allowing it to acquire the teacher's comprehensive reasoning capabilities.
The authors evaluate this approach on a variety of multi-step reasoning tasks, demonstrating significant performance improvements for smaller student models compared to standard distillation techniques. This suggests the proposed method is an effective way to bridge the capability gap between large, complex models and their smaller counterparts.
Critical Analysis
The paper provides a thorough empirical evaluation of the proposed chain-of-thought distillation method, exploring its performance on a range of reasoning tasks. However, it would be valuable to see further analysis of the limitations and potential drawbacks of this approach.
For example, the authors do not delve deeply into the computational and memory overhead required to implement the mutual information maximization framework, which could be a practical concern for deploying smaller models in resource-constrained environments. Additionally, the reliance on a larger teacher model may limit the broader applicability of this technique if such models are not available.
Further research could also investigate the robustness and generalization of the student models trained using this method, as well as explore ways to make the distillation process more efficient and scalable. Nonetheless, the core ideas presented in this paper represent an intriguing advance in the field of model compression and knowledge transfer.
Conclusion
This paper introduces a novel approach to distilling the reasoning capabilities of large language models into smaller, more efficient student models. By maximizing the mutual information between the student's outputs and the teacher's step-by-step thought process, the authors demonstrate a way to effectively transfer the comprehensive reasoning skills of powerful models to their smaller counterparts.
The experimental results show this chain-of-thought distillation method can significantly improve the performance of smaller models on complex, multi-step tasks, bridging the capability gap between large and small models. This has important implications for deploying high-performing AI systems in resource-constrained environments, where smaller models are often necessary.
Overall, this paper presents a promising approach to model compression and knowledge transfer, with the potential to enhance the reasoning abilities of a wide range of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond Imitation: Learning Key Reasoning Steps from Dual Chain-of-Thoughts in Reasoning Distillation
Chengwei Dai, Kun Li, Wei Zhou, Songlin Hu
0
0
As Large Language Models (LLMs) scale up and gain powerful Chain-of-Thoughts (CoTs) reasoning abilities, practical resource constraints drive efforts to distill these capabilities into more compact Smaller Language Models (SLMs). We find that CoTs consist mainly of simple reasoning forms, with a small proportion ($approx 4.7%$) of key reasoning steps that truly impact conclusions. However, previous distillation methods typically involve supervised fine-tuning student SLMs only on correct CoTs data produced by teacher LLMs, resulting in students struggling to learn the key reasoning steps, instead imitating the teacher's reasoning forms and making errors or omissions on these steps. To address these issues, drawing an analogy to human learning, where analyzing mistakes according to correct solutions often reveals the crucial steps leading to successes or failures, we propose mistaktextbf{E}-textbf{D}riven key reasontextbf{I}ng step distillatextbf{T}ion (textbf{EDIT}), a novel method that further aids SLMs learning key reasoning steps rather than mere simple fine-tuning. Firstly, to expose these crucial steps in CoTs, we design specific prompts to generate dual CoTs data with similar reasoning paths but divergent conclusions. Then, we apply the minimum edit distance algorithm on the dual CoTs data to locate these key steps and optimize the likelihood of these steps. Extensive experiments validate the effectiveness of EDIT across both in-domain and out-of-domain benchmark reasoning datasets. Further analysis shows that EDIT can generate high-quality CoTs with more correct key reasoning steps. Notably, we also explore how different mistake patterns affect performance and find that EDIT benefits more from logical errors than from knowledge or mathematical calculation errors in dual CoTsfootnote{Code can be found at url{https://github.com/C-W-D/EDIT}}.
5/31/2024
Improve Student's Reasoning Generalizability through Cascading Decomposed CoTs Distillation
Chengwei Dai, Kun Li, Wei Zhou, Songlin Hu
0
0
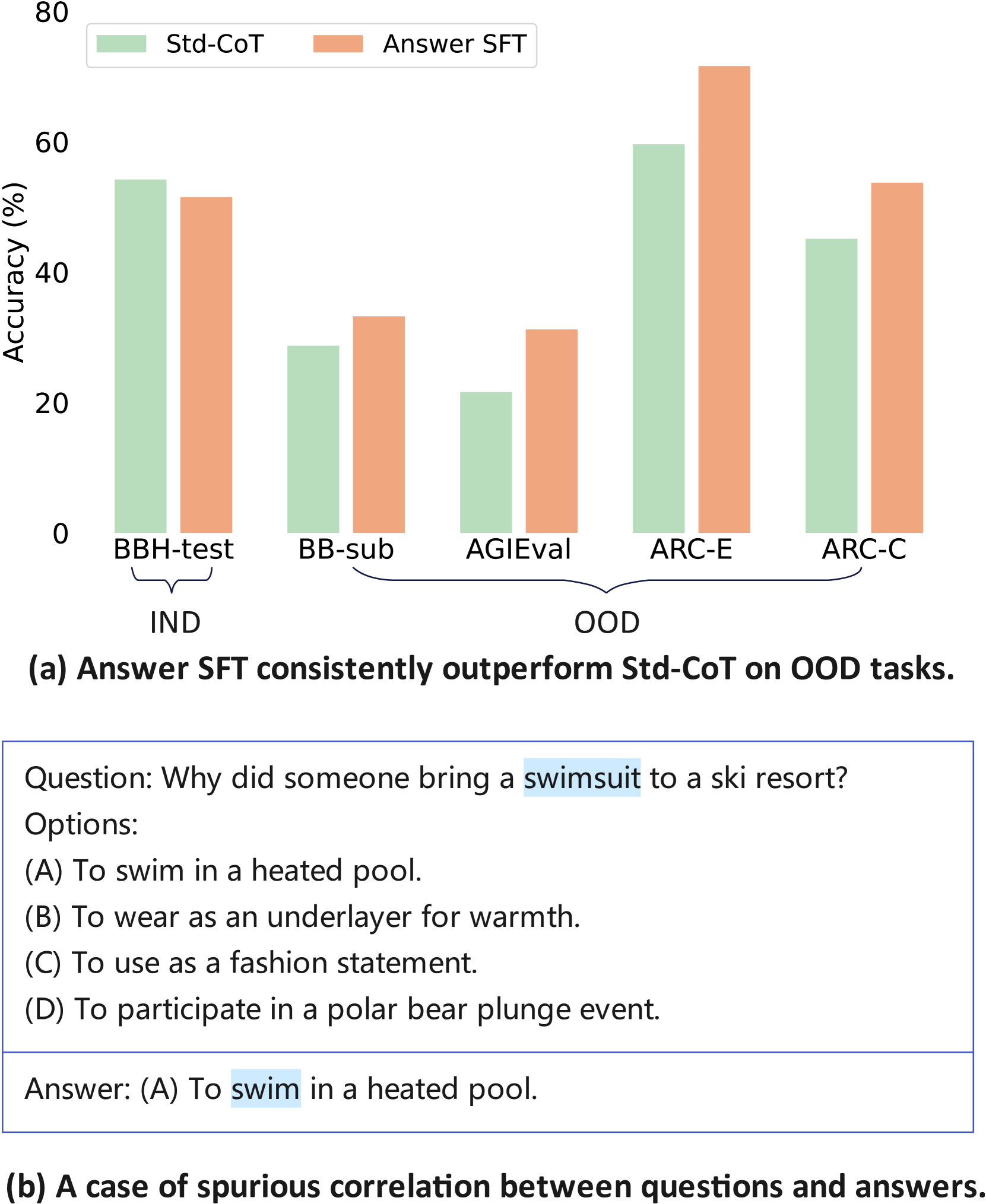
Large language models (LLMs) exhibit enhanced reasoning at larger scales, driving efforts to distill these capabilities into smaller models via teacher-student learning. Previous works simply fine-tune student models on teachers' generated Chain-of-Thoughts (CoTs) data. Although these methods enhance in-domain (IND) reasoning performance, they struggle to generalize to out-of-domain (OOD) tasks. We believe that the widespread spurious correlations between questions and answers may lead the model to preset a specific answer which restricts the diversity and generalizability of its reasoning process. In this paper, we propose Cascading Decomposed CoTs Distillation (CasCoD) to address these issues by decomposing the traditional single-step learning process into two cascaded learning steps. Specifically, by restructuring the training objectives -- removing the answer from outputs and concatenating the question with the rationale as input -- CasCoD's two-step learning process ensures that students focus on learning rationales without interference from the preset answers, thus improving reasoning generalizability. Extensive experiments demonstrate the effectiveness of CasCoD on both IND and OOD benchmark reasoning datasets. Code can be found at https://github.com/C-W-D/CasCoD.
5/31/2024

Symbolic Chain-of-Thought Distillation: Small Models Can Also Think Step-by-Step
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, Yejin Choi
0
0
Chain-of-thought prompting (e.g., Let's think step-by-step) primes large language models to verbalize rationalization for their predictions. While chain-of-thought can lead to dramatic performance gains, benefits appear to emerge only for sufficiently large models (beyond 50B parameters). We show that orders-of-magnitude smaller models (125M -- 1.3B parameters) can still benefit from chain-of-thought prompting. To achieve this, we introduce Symbolic Chain-of-Thought Distillation (SCoTD), a method to train a smaller student model on rationalizations sampled from a significantly larger teacher model. Experiments across several commonsense benchmarks show that: 1) SCoTD enhances the performance of the student model in both supervised and few-shot settings, and especially for challenge sets; 2) sampling many reasoning chains per instance from the teacher is paramount; and 3) after distillation, student chain-of-thoughts are judged by humans as comparable to the teacher, despite orders of magnitude fewer parameters. We test several hypotheses regarding what properties of chain-of-thought samples are important, e.g., diversity vs. teacher likelihood vs. open-endedness. We release our corpus of chain-of-thought samples and code.
4/17/2024
Keypoint-based Progressive Chain-of-Thought Distillation for LLMs
Kaituo Feng, Changsheng Li, Xiaolu Zhang, Jun Zhou, Ye Yuan, Guoren Wang
0
0
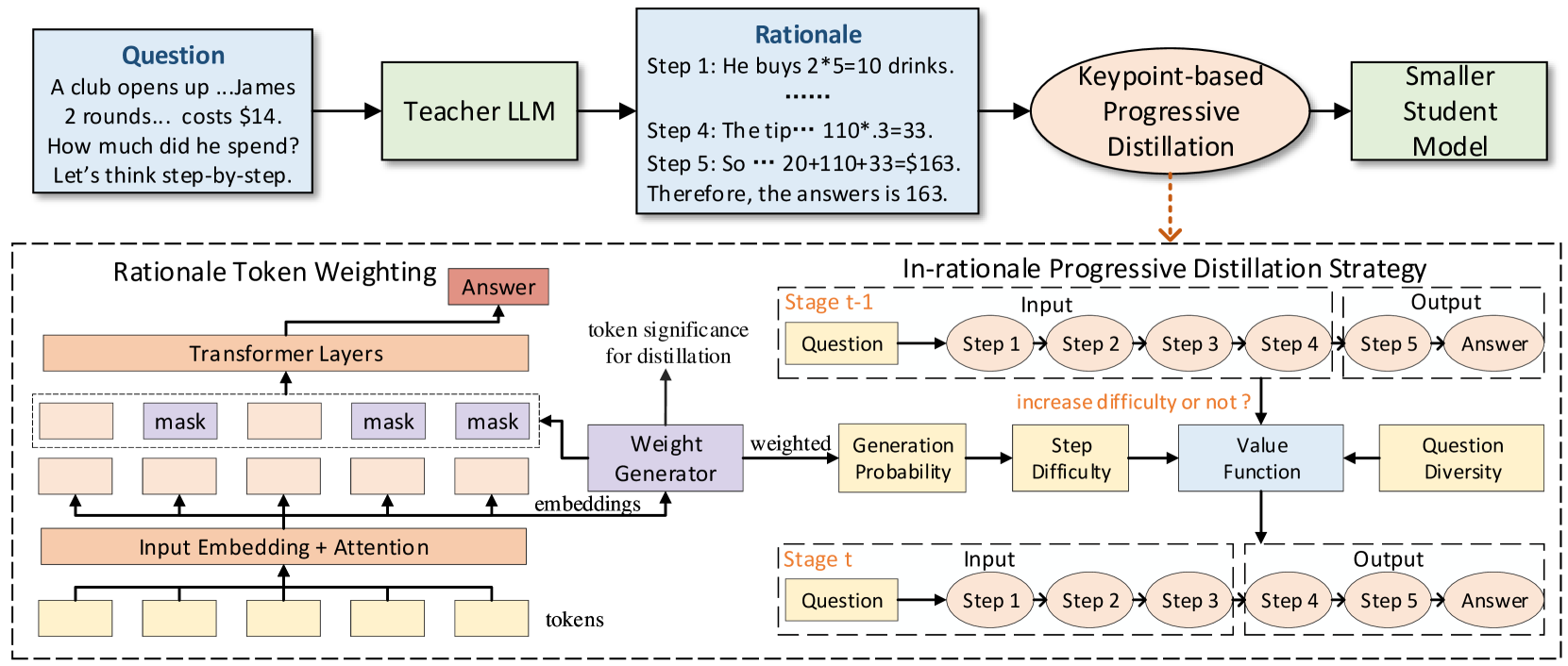
Chain-of-thought distillation is a powerful technique for transferring reasoning abilities from large language models (LLMs) to smaller student models. Previous methods typically require the student to mimic the step-by-step rationale produced by LLMs, often facing the following challenges: (i) Tokens within a rationale vary in significance, and treating them equally may fail to accurately mimic keypoint tokens, leading to reasoning errors. (ii) They usually distill knowledge by consistently predicting all the steps in a rationale, which falls short in distinguishing the learning order of step generation. This diverges from the human cognitive progression of starting with easy tasks and advancing to harder ones, resulting in sub-optimal outcomes. To this end, we propose a unified framework, called KPOD, to address these issues. Specifically, we propose a token weighting module utilizing mask learning to encourage accurate mimicry of keypoint tokens by the student during distillation. Besides, we develop an in-rationale progressive distillation strategy, starting with training the student to generate the final reasoning steps and gradually extending to cover the entire rationale. To accomplish this, a weighted token generation loss is proposed to assess step reasoning difficulty, and a value function is devised to schedule the progressive distillation by considering both step difficulty and question diversity. Extensive experiments on four reasoning benchmarks illustrate our KPOD outperforms previous methods by a large margin.
5/28/2024