Let Me Teach You: Pedagogical Foundations of Feedback for Language Models
2307.00279
0
0

Abstract
Natural Language Feedback (NLF) is an increasingly popular mechanism for aligning Large Language Models (LLMs) to human preferences. Despite the diversity of the information it can convey, NLF methods are often hand-designed and arbitrary, with little systematic grounding. At the same time, research in learning sciences has long established several effective feedback models. In this opinion piece, we compile ideas from pedagogy to introduce FELT, a feedback framework for LLMs that outlines various characteristics of the feedback space, and a feedback content taxonomy based on these variables, providing a general mapping of the feedback space. In addition to streamlining NLF designs, FELT also brings out new, unexplored directions for research in NLF. We make our taxonomy available to the community, providing guides and examples for mapping our categorizations to future research.
Create account to get full access
Overview
- This paper explores the pedagogical foundations of feedback for large language models (LLMs), aiming to improve their performance and capabilities.
- The authors investigate how principles from educational psychology, such as feedback and scaffolding, can be applied to the training and deployment of LLMs.
- The paper provides insights into leveraging human feedback and interactions to enhance the learning and performance of LLMs.
Plain English Explanation
The paper looks at how we can use teaching and learning principles to help improve large language models, which are AI systems that can understand and generate human-like text. The authors explore how concepts from education, like providing feedback and support to learners, can be applied to training and using these language models.
The key idea is that by incorporating educational strategies, we can help language models learn more effectively and perform better. For example, providing feedback can guide the model's training and help it improve over time. Similarly, scaffolding – offering step-by-step support and guidance – could assist language models in tackling more complex tasks.
By drawing on pedagogical principles, the researchers aim to enhance the capabilities of language models and make them more useful and effective in real-world applications, such as automated feedback systems or conversational AI assistants.
Technical Explanation
The paper explores how principles from educational psychology, such as feedback and scaffolding, can be applied to the training and deployment of large language models (LLMs). The authors investigate ways to leverage human feedback and interactions to enhance the learning and performance of these AI systems.
The researchers review relevant literature from fields like instructional design, cognitive psychology, and education to identify key pedagogical strategies that could be beneficial for LLMs. They discuss how techniques like formative feedback, self-regulated learning, and zone of proximal development could be adapted and incorporated into the development and use of language models.
The paper also examines existing research on the use of feedback and human-AI interaction to improve language model performance. The authors analyze the potential benefits and challenges of applying these principles in the context of LLMs, considering factors such as model architecture, data sources, and real-world deployment scenarios.
Overall, the paper provides a theoretical foundation for leveraging pedagogical insights to enhance the capabilities and reliability of large language models, with the goal of making them more effective in various applications.
Critical Analysis
The paper presents a thoughtful and well-researched approach to applying educational principles to the development and deployment of large language models. The authors make a compelling case for the potential benefits of this approach, drawing on a broad range of literature from different fields.
However, the paper also acknowledges several caveats and limitations that warrant further consideration. For instance, the authors note that the practical implementation of these pedagogical strategies may be challenging, given the complexities of LLM architectures and the inherent difficulties in interpreting and responding to human feedback.
Additionally, the paper suggests that more research is needed to fully understand the implications of applying educational psychology to language models, particularly in terms of model performance, robustness, and alignment with human values and preferences. Potential issues around biases, fairness, and the impact of feedback on model behavior should also be carefully examined.
Despite these limitations, the paper provides a valuable theoretical framework for exploring the intersection of language models and educational principles. By encouraging critical thinking and further research in this area, the authors contribute to the ongoing efforts to develop more effective and reliable AI systems that can positively impact society.
Conclusion
This paper presents a compelling approach to enhancing the capabilities of large language models by drawing on principles from educational psychology. The authors argue that by incorporating strategies like feedback, scaffolding, and self-regulated learning, LLMs can become more effective, reliable, and aligned with human needs and values.
The insights offered in this paper have the potential to inform the development of advanced language models that can provide better assistance, feedback, and learning experiences to users across a wide range of applications, from automated tutoring systems to conversational AI assistants.
As the field of artificial intelligence continues to evolve, the integration of educational principles into the design and deployment of language models may be a key factor in creating AI systems that are more aligned with human needs, goals, and perspectives. This research represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Policy Improvement using Language Feedback Models
Victor Zhong, Dipendra Misra, Xingdi Yuan, Marc-Alexandre C^ot'e
0
0
We introduce Language Feedback Models (LFMs) that identify desirable behaviour - actions that help achieve tasks specified in the instruction - for imitation learning in instruction following. To train LFMs, we obtain feedback from Large Language Models (LLMs) on visual trajectories verbalized to language descriptions. First, by using LFMs to identify desirable behaviour to imitate, we improve in task-completion rate over strong behavioural cloning baselines on three distinct language grounding environments (Touchdown, ScienceWorld, and ALFWorld). Second, LFMs outperform using LLMs as experts to directly predict actions, when controlling for the number of LLM output tokens. Third, LFMs generalize to unseen environments, improving task-completion rate by 3.5-12.0% through one round of adaptation. Finally, LFM can be modified to provide human-interpretable feedback without performance loss, allowing human verification of desirable behaviour for imitation learning.
4/22/2024
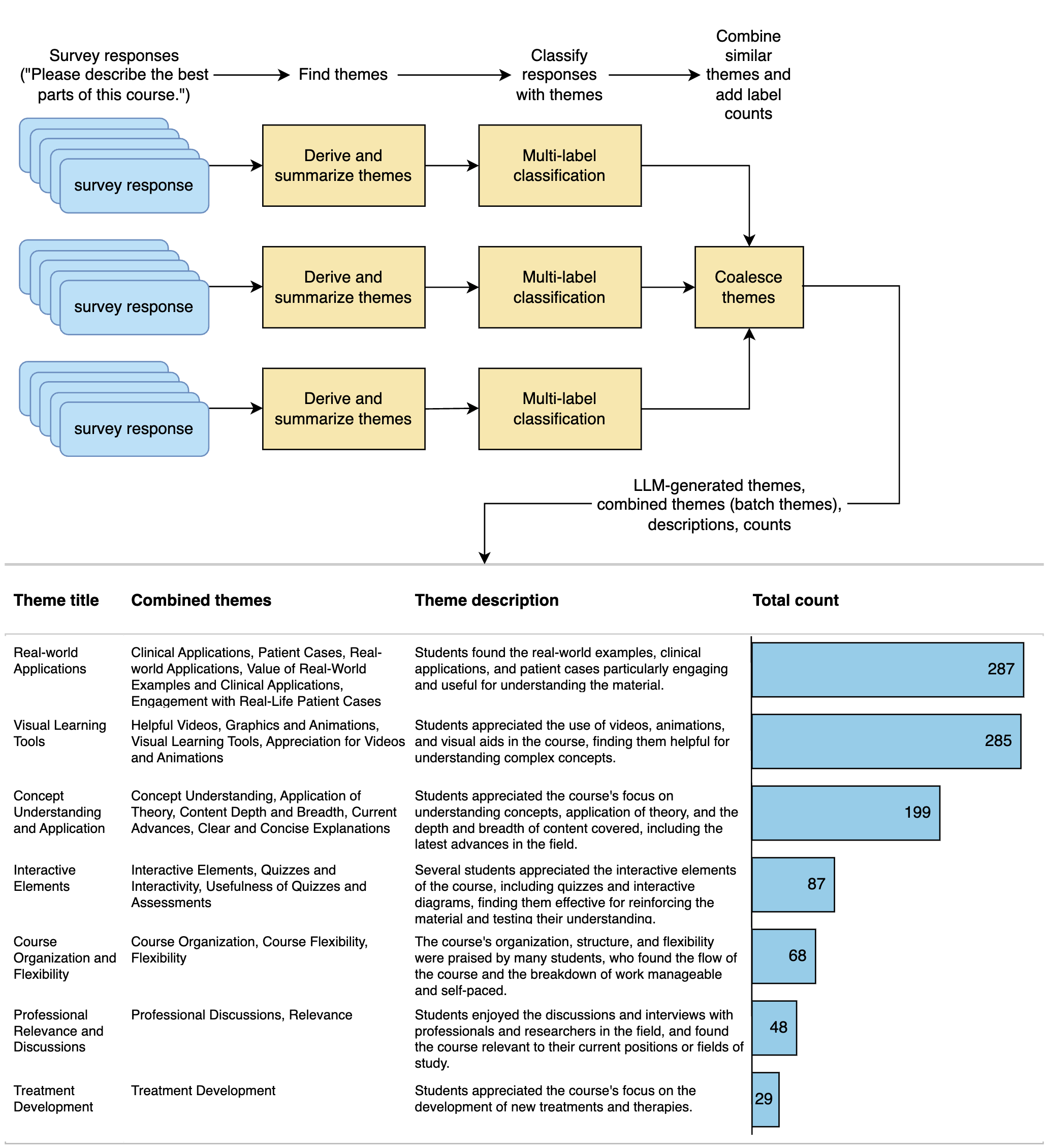
A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024

Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
0
0
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
5/2/2024

Nash Learning from Human Feedback
R'emi Munos, Michal Valko, Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Zhaohan Daniel Guo, Yunhao Tang, Matthieu Geist, Thomas Mesnard, Andrea Michi, Marco Selvi, Sertan Girgin, Nikola Momchev, Olivier Bachem, Daniel J. Mankowitz, Doina Precup, Bilal Piot
0
0
Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
6/12/2024