Lifelong Event Detection with Embedding Space Separation and Compaction

0

Sign in to get full access
Overview
- This paper proposes a new approach for lifelong event detection, which aims to continuously learn and detect new types of events over time without forgetting previously learned ones.
- The key idea is to separate and compact the embedding space to efficiently represent both old and new event types, enabling the model to continuously expand its event detection capabilities.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improved performance compared to existing lifelong learning methods.
Plain English Explanation
The paper addresses the challenge of lifelong event detection, which is the ability of a machine learning model to continuously learn and detect new types of events over time without forgetting what it has learned before. This is an important problem because in the real world, new types of events are constantly emerging, and we want our models to be able to adapt and recognize them without losing their ability to detect old events.
The authors' solution is to separate and compact the embedding space used by the model to represent event types. By carefully managing the way the embedding space is organized, the model can efficiently store representations for both old and new event types, allowing it to continuously expand its event detection capabilities over time.
The authors test their approach on several benchmark datasets and show that it outperforms existing lifelong learning methods. This suggests that their technique for separating and compacting the embedding space is a promising way to solve the lifelong event detection problem.
Technical Explanation
The paper proposes a novel approach for class-incremental few-shot event detection, which aims to enable a model to continuously learn and detect new types of events without forgetting previously learned ones.
The key idea is to separate and compact the embedding space used to represent event types. Specifically, the authors introduce two techniques:
-
Embedding Space Separation: The model maintains separate embedding spaces for old and new event types, allowing it to efficiently store representations for both.
-
Embedding Space Compaction: The model compacts the embedding space for old event types, reducing the number of parameters required to represent them. This frees up capacity in the overall embedding space to accommodate new event types.
By carefully managing the embedding space in this way, the model can continuously expand its event detection capabilities over time, adding new event types while preserving its ability to recognize previously learned ones.
The authors evaluate their approach on several benchmark datasets for event detection, including TAC-KBP and ERE. The results show that their method outperforms existing lifelong learning approaches, demonstrating the effectiveness of the embedding space separation and compaction techniques.
Critical Analysis
The paper presents a promising solution to the challenging problem of lifelong event detection. The authors' key insight of separating and compacting the embedding space is a clever way to address the core challenge of continuously expanding the model's event detection capabilities without forgetting previously learned knowledge.
That said, the paper does not address several important practical considerations. For example, the authors do not discuss how their approach would scale to a large number of event types or how it would handle evolving event definitions over time. Additionally, the paper does not provide much insight into the computational and memory efficiency of the proposed techniques, which would be important for real-world deployment.
Furthermore, the authors acknowledge that their method relies on having access to a small number of examples for each new event type, which may not always be feasible in practice. It would be valuable to explore ways to relax this requirement and make the approach more robust to limited data scenarios.
Despite these limitations, the paper makes a valuable contribution to the field of lifelong learning, and the authors' techniques for separating and compacting the embedding space could inspire further research into efficient ways to continuously expand machine learning models' capabilities.
Conclusion
The paper presents a new approach for lifelong event detection that addresses the challenge of continuously learning and detecting new event types without forgetting previously learned ones. The key innovation is the use of embedding space separation and compaction, which allows the model to efficiently represent both old and new event types in its internal representations.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improved performance compared to existing lifelong learning methods. This suggests that their techniques for separating and compacting the embedding space could be a valuable contribution to the field of lifelong learning, with potential applications in a wide range of real-world scenarios where machine learning models need to continuously adapt and expand their capabilities over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lifelong Event Detection with Embedding Space Separation and Compaction
Chengwei Qin, Ruirui Chen, Ruochen Zhao, Wenhan Xia, Shafiq Joty
To mitigate forgetting, existing lifelong event detection methods typically maintain a memory module and replay the stored memory data during the learning of a new task. However, the simple combination of memory data and new-task samples can still result in substantial forgetting of previously acquired knowledge, which may occur due to the potential overlap between the feature distribution of new data and the previously learned embedding space. Moreover, the model suffers from overfitting on the few memory samples rather than effectively remembering learned patterns. To address the challenges of forgetting and overfitting, we propose a novel method based on embedding space separation and compaction. Our method alleviates forgetting of previously learned tasks by forcing the feature distribution of new data away from the previous embedding space. It also mitigates overfitting by a memory calibration mechanism that encourages memory data to be close to its prototype to enhance intra-class compactness. In addition, the learnable parameters of the new task are initialized by drawing upon acquired knowledge from the previously learned task to facilitate forward knowledge transfer. With extensive experiments, we demonstrate that our method can significantly outperform previous state-of-the-art approaches.
Read more4/4/2024
0
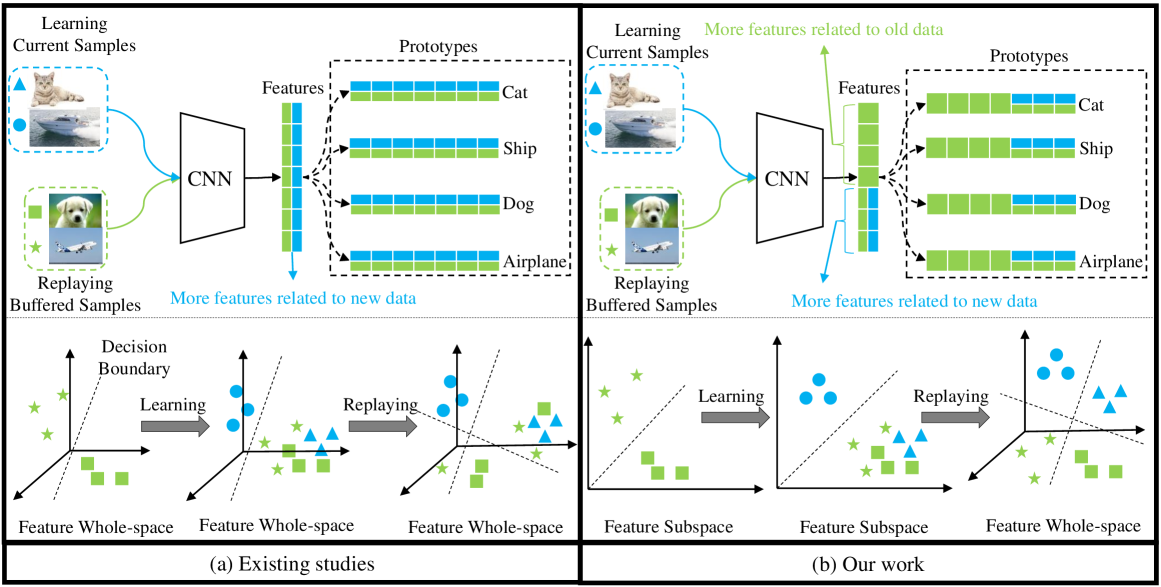
ER-FSL: Experience Replay with Feature Subspace Learning for Online Continual Learning
Huiwei Lin
Online continual learning (OCL) involves deep neural networks retaining knowledge from old data while adapting to new data, which is accessible only once. A critical challenge in OCL is catastrophic forgetting, reflected in reduced model performance on old data. Existing replay-based methods mitigate forgetting by replaying buffered samples from old data and learning current samples of new data. In this work, we dissect existing methods and empirically discover that learning and replaying in the same feature space is not conducive to addressing the forgetting issue. Since the learned features associated with old data are readily changed by the features related to new data due to data imbalance, leading to the forgetting problem. Based on this observation, we intuitively explore learning and replaying in different feature spaces. Learning in a feature subspace is sufficient to capture novel knowledge from new data while replaying in a larger feature space provides more feature space to maintain historical knowledge from old data. To this end, we propose a novel OCL approach called experience replay with feature subspace learning (ER-FSL). Firstly, ER-FSL divides the entire feature space into multiple subspaces, with each subspace used to learn current samples. Moreover, it introduces a subspace reuse mechanism to address situations where no blank subspaces exist. Secondly, ER-FSL replays previous samples using an accumulated space comprising all learned subspaces. Extensive experiments on three datasets demonstrate the superiority of ER-FSL over various state-of-the-art methods.
Read more7/18/2024
0
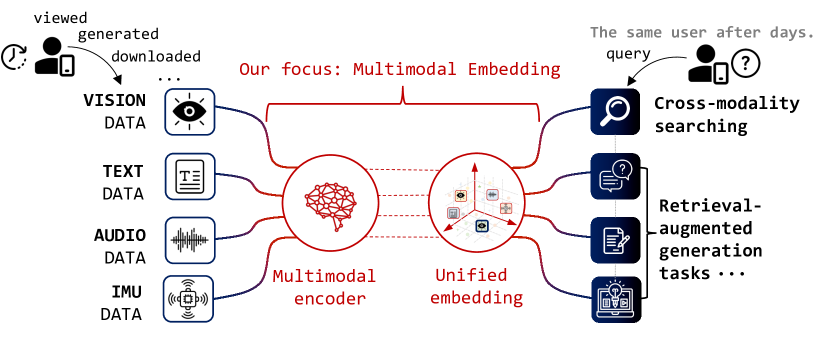
Recall: Empowering Multimodal Embedding for Edge Devices
Dongqi Cai, Shangguang Wang, Chen Peng, Zeling Zhang, Mengwei Xu
Human memory is inherently prone to forgetting. To address this, multimodal embedding models have been introduced, which transform diverse real-world data into a unified embedding space. These embeddings can be retrieved efficiently, aiding mobile users in recalling past information. However, as model complexity grows, so do its resource demands, leading to reduced throughput and heavy computational requirements that limit mobile device implementation. In this paper, we introduce RECALL, a novel on-device multimodal embedding system optimized for resource-limited mobile environments. RECALL achieves high-throughput, accurate retrieval by generating coarse-grained embeddings and leveraging query-based filtering for refined retrieval. Experimental results demonstrate that RECALL delivers high-quality embeddings with superior throughput, all while operating unobtrusively with minimal memory and energy consumption.
Read more9/25/2024
➖
0
Lifelong Learning and Selective Forgetting via Contrastive Strategy
Lianlei Shan, Wenzhang Zhou, Wei Li, Xingyu Ding
Lifelong learning aims to train a model with good performance for new tasks while retaining the capacity of previous tasks. However, some practical scenarios require the system to forget undesirable knowledge due to privacy issues, which is called selective forgetting. The joint task of the two is dubbed Learning with Selective Forgetting (LSF). In this paper, we propose a new framework based on contrastive strategy for LSF. Specifically, for the preserved classes (tasks), we make features extracted from different samples within a same class compacted. And for the deleted classes, we make the features from different samples of a same class dispersed and irregular, i.e., the network does not have any regular response to samples from a specific deleted class as if the network has no training at all. Through maintaining or disturbing the feature distribution, the forgetting and memory of different classes can be or independent of each other. Experiments are conducted on four benchmark datasets, and our method acieves new state-of-the-art.
Read more5/30/2024