Limits to Predicting Online Speech Using Large Language Models

0
Sign in to get full access
Overview
- This paper explores the limits of using large language models (LLMs) to predict online speech, particularly in the context of sensitive and controversial topics.
- The researchers conducted several experiments to assess the performance of LLMs in predicting online comments, and found significant limitations in their ability to accurately forecast speech.
- The findings have important implications for the use of LLMs in content moderation, political forecasting, and other applications where accurately predicting online discourse is crucial.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. Researchers have been exploring whether these models can be used to predict what people will say online, such as on social media or in online discussions. This could be useful for things like moderating harmful content or forecasting political events.
However, the authors of this paper found that LLMs have significant limitations when it comes to accurately predicting online speech, especially on sensitive or controversial topics. In their experiments, the models often failed to accurately forecast what people would say, even when trained on large amounts of data.
The researchers believe this is because online speech is heavily influenced by complex social and psychological factors that LLMs struggle to capture. Things like personal experiences, emotions, and social context can play a big role in shaping what people say online, and these factors are difficult for current language models to fully understand and account for.
This means that while LLMs can be powerful tools for tasks like summarizing text or generating coherent content, they have significant limitations when it comes to predicting online behavior. The authors caution that over-reliance on these models for applications like content moderation or political forecasting could lead to unreliable and potentially harmful results.
Technical Explanation
The researchers conducted a series of experiments to assess the ability of large language models (LLMs) to predict online speech. They trained LLMs on large datasets of online comments and then tasked the models with generating predictions for new comments on a range of topics, including sensitive and controversial subjects.
The results showed that the LLMs struggled to accurately forecast the content and tone of the comments, even when trained on vast amounts of data. The models tended to generate comments that were stylistically similar to the training data but failed to capture the nuanced social, psychological, and contextual factors that shape real-world online discourse.
For example, the LLMs often produced comments that were more inflammatory or extreme than the actual comments they were trying to predict. They also struggled to anticipate how users would react to particular topics or events, frequently underestimating the potential for heated, emotional, or polarized responses.
The researchers attribute these limitations to the inherent challenges of using LLMs to model complex human behavior and social interactions. While these models excel at tasks like text generation and semantic understanding, they lack the deeper understanding of human psychology, social dynamics, and contextual nuance required to accurately predict real-world online speech.
Critical Analysis
The researchers acknowledge several important caveats and limitations in their work. First, they note that their experiments were conducted on a limited set of topics and platforms, and that the performance of LLMs may vary depending on the specific domain and context.
Additionally, the researchers point out that their findings do not necessarily preclude the use of LLMs in certain applications, such as content moderation or political forecasting, but rather suggest the need for a more nuanced and cautious approach. They recommend that any use of LLMs for these purposes should be accompanied by rigorous validation, human oversight, and a clear understanding of the models' limitations.
One potential concern that the paper does not address is the potential for LLMs to be used to generate harmful or manipulative content, even if they cannot accurately predict real-world speech. The researchers may want to consider the implications of their findings for the responsible development and deployment of these powerful language models.
Overall, this paper provides valuable insights into the challenges of using LLMs to model and predict online discourse, particularly on sensitive and controversial topics. The findings serve as an important reminder that these models, while impressive in many ways, have significant limitations and should be approached with caution and careful consideration of their potential impacts.
Conclusion
This paper highlights the significant limitations of using large language models (LLMs) to predict online speech, particularly in the context of sensitive and controversial topics. The researchers found that despite their impressive capabilities in tasks like text generation and semantic understanding, LLMs struggle to accurately forecast the content and tone of real-world online comments.
These findings have important implications for the use of LLMs in applications like content moderation, political forecasting, and other areas where accurately predicting online discourse is crucial. The authors caution that over-reliance on these models could lead to unreliable and potentially harmful results, and they recommend a more cautious and nuanced approach that takes into account the inherent limitations of current language models.
Overall, this paper serves as a valuable reminder that while LLMs are powerful tools, they are not a panacea for understanding and predicting complex human behavior and social interactions. As these models continue to evolve and be applied in new domains, it will be important for researchers, developers, and policymakers to carefully consider their strengths, limitations, and potential impacts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Limits to Predicting Online Speech Using Large Language Models
Mina Remeli, Moritz Hardt, Robert C. Williamson
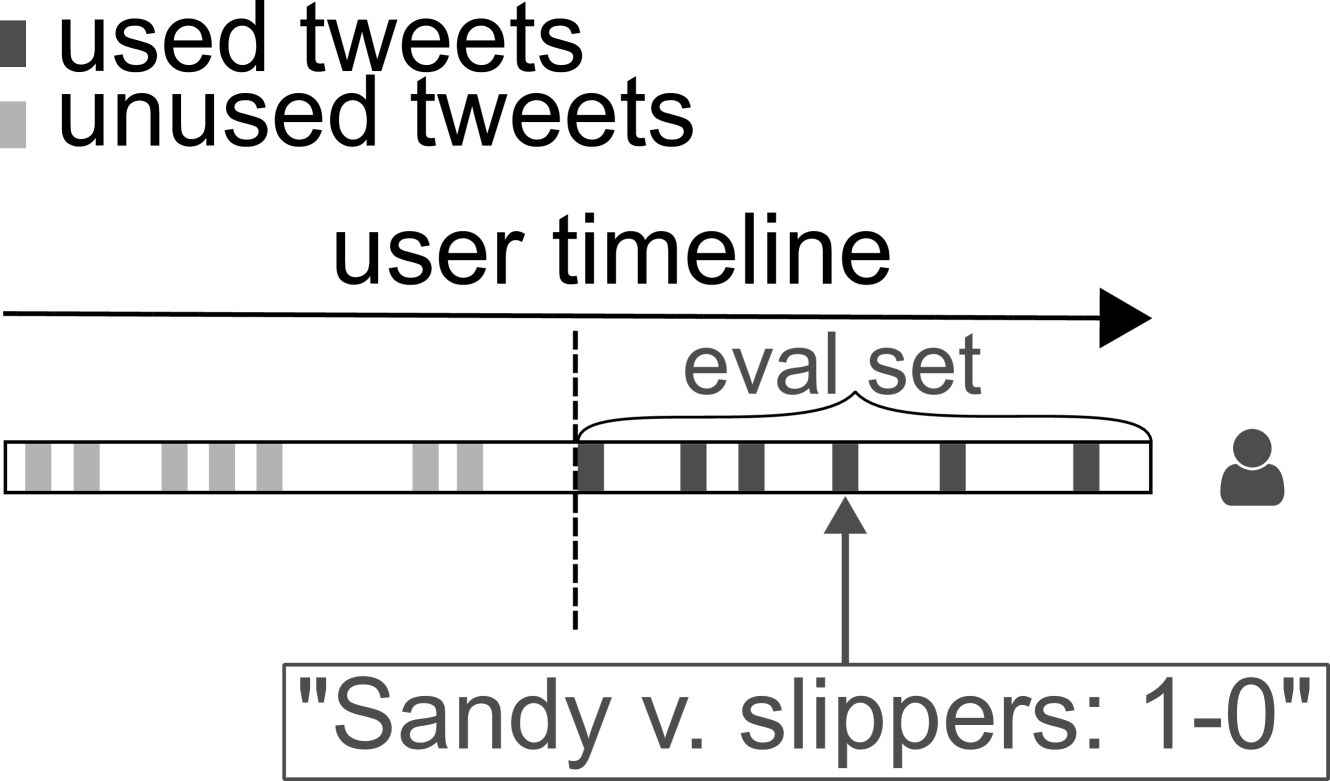
We study the predictability of online speech on social media, and whether predictability improves with information outside a user's own posts. Recent work suggests that the predictive information contained in posts written by a user's peers can surpass that of the user's own posts. Motivated by the success of large language models, we empirically test this hypothesis. We define unpredictability as a measure of the model's uncertainty, i.e., its negative log-likelihood on future tokens given context. As the basis of our study, we collect a corpus of 6.25M posts from more than five thousand X (previously Twitter) users and their peers. Across three large language models ranging in size from 1 billion to 70 billion parameters, we find that predicting a user's posts from their peers' posts performs poorly. Moreover, the value of the user's own posts for prediction is consistently higher than that of their peers'. Across the board, we find that the predictability of social media posts remains low, comparable to predicting financial news without context. We extend our investigation with a detailed analysis about the causes of unpredictability and the robustness of our findings. Specifically, we observe that a significant amount of predictive uncertainty comes from hashtags and @-mentions. Moreover, our results replicate if instead of prompting the model with additional context, we finetune on additional context.
Read more7/19/2024
💬
0
Large Language Models Can Infer Psychological Dispositions of Social Media Users
Heinrich Peters, Sandra Matz
Large Language Models (LLMs) demonstrate increasingly human-like abilities across a wide variety of tasks. In this paper, we investigate whether LLMs like ChatGPT can accurately infer the psychological dispositions of social media users and whether their ability to do so varies across socio-demographic groups. Specifically, we test whether GPT-3.5 and GPT-4 can derive the Big Five personality traits from users' Facebook status updates in a zero-shot learning scenario. Our results show an average correlation of r = .29 (range = [.22, .33]) between LLM-inferred and self-reported trait scores - a level of accuracy that is similar to that of supervised machine learning models specifically trained to infer personality. Our findings also highlight heterogeneity in the accuracy of personality inferences across different age groups and gender categories: predictions were found to be more accurate for women and younger individuals on several traits, suggesting a potential bias stemming from the underlying training data or differences in online self-expression. The ability of LLMs to infer psychological dispositions from user-generated text has the potential to democratize access to cheap and scalable psychometric assessments for both researchers and practitioners. On the one hand, this democratization might facilitate large-scale research of high ecological validity and spark innovation in personalized services. On the other hand, it also raises ethical concerns regarding user privacy and self-determination, highlighting the need for stringent ethical frameworks and regulation.
Read more6/6/2024

0
Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, Maarten Sap
As natural language becomes the default interface for human-AI interaction, there is a need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence in responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are reluctant to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (an average of 47%) among confident responses. We test the risks of LM overconfidence by conducting human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in post training alignment and find that humans are biased against texts with uncertainty. Our work highlights new safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
Read more7/11/2024

0
Perceptions of Linguistic Uncertainty by Language Models and Humans
Catarina G Belem, Markelle Kelly, Mark Steyvers, Sameer Singh, Padhraic Smyth
Uncertainty expressions such as ``probably'' or ``highly unlikely'' are pervasive in human language. While prior work has established that there is population-level agreement in terms of how humans interpret these expressions, there has been little inquiry into the abilities of language models to interpret such expressions. In this paper, we investigate how language models map linguistic expressions of uncertainty to numerical responses. Our approach assesses whether language models can employ theory of mind in this setting: understanding the uncertainty of another agent about a particular statement, independently of the model's own certainty about that statement. We evaluate both humans and 10 popular language models on a task created to assess these abilities. Unexpectedly, we find that 8 out of 10 models are able to map uncertainty expressions to probabilistic responses in a human-like manner. However, we observe systematically different behavior depending on whether a statement is actually true or false. This sensitivity indicates that language models are substantially more susceptible to bias based on their prior knowledge (as compared to humans). These findings raise important questions and have broad implications for human-AI alignment and AI-AI communication.
Read more7/23/2024