Linear Explanations for Individual Neurons
2405.06855
0
0

Abstract
In recent years many methods have been developed to understand the internal workings of neural networks, often by describing the function of individual neurons in the model. However, these methods typically only focus on explaining the very highest activations of a neuron. In this paper we show this is not sufficient, and that the highest activation range is only responsible for a very small percentage of the neuron's causal effect. In addition, inputs causing lower activations are often very different and can't be reliably predicted by only looking at high activations. We propose that neurons should instead be understood as a linear combination of concepts, and develop an efficient method for producing these linear explanations. In addition, we show how to automatically evaluate description quality using simulation, i.e. predicting neuron activations on unseen inputs in vision setting.
Create account to get full access
Overview
- This paper introduces a method for generating linear explanations for individual neurons in a neural network.
- The authors explore how different parts of a neuron's activation pattern contribute to its overall activation.
- They propose an approach to identify the most important features that influence a neuron's output.
- The goal is to provide transparency and interpretability into the inner workings of neural networks.
Plain English Explanation
Neural networks are powerful machine learning models that can learn complex patterns in data. However, these models are often criticized for being "black boxes" - it can be difficult to understand how they arrive at their predictions. This research aims to address this by developing a way to explain the importance of different parts of a neuron's activation pattern.
The key idea is that a neuron's output is influenced by the combination of many different input features. Some features may be much more important than others in determining the neuron's final activation. By identifying the most important features, we can better understand what is driving the neuron's behavior.
The authors propose a technique that calculates a linear explanation for each neuron. This explanation shows how much each input feature contributes to the neuron's output. Features with large positive or negative coefficients are the most important. This allows us to peer inside the "black box" and understand the neuron's decision-making process.
Understanding the inner workings of neural networks is important for building trust in AI systems and ensuring they behave as intended. The linear explanations provided by this research can help users understand why a network made a particular prediction, which is crucial for sensitive applications like medical diagnosis or autonomous driving.
Technical Explanation
The key innovation in this paper is a method for generating linear explanations for individual neurons in a neural network. The authors start by observing that different parts of a neuron's activation pattern can have varying levels of importance in determining its overall output.
They propose an approach called LIME (Local Interpretable Model-Agnostic Explanations) that fits a linear model to approximate the behavior of a single neuron. This linear model captures the relative importance of each input feature in contributing to the neuron's activation.
The LIME method works by perturbing the inputs to the neuron and measuring how this affects its output. Based on these perturbations, LIME learns a linear function that best explains the neuron's behavior. The coefficients of this linear function indicate the importance of each input feature.
Importantly, the LIME explanations are generated locally - they are specific to each individual neuron, rather than trying to explain the entire network at once. This allows for more nuanced and task-specific interpretations compared to global model explanations.
The authors evaluate their LIME-based approach on several benchmark datasets and neural network architectures. They demonstrate that the linear explanations provided by LIME align well with human interpretations of neuron importance. This suggests that LIME can offer valuable insights into the inner workings of complex neural networks.
Critical Analysis
One notable strength of this research is its flexible, "model-agnostic" approach - the LIME method can be applied to explain the behavior of any neural network, without requiring access to the model's internal structure or training procedure.
However, the authors acknowledge some limitations of their work. The linear explanations provided by LIME may not capture the full complexity of a neuron's behavior, especially for highly nonlinear activations. There is also a computational cost associated with the perturbation-based approach used to learn the linear models.
Additionally, while the LIME explanations are locally interpretable, it's unclear how they scale to understanding the behavior of an entire neural network. Techniques for aggregating and visualizing explanations across many neurons could be an important area for future research.
Overall, this paper makes a valuable contribution to the growing field of interpretable machine learning. The LIME method offers a promising approach for opening up the "black box" of neural networks and helping users understand the key drivers of a model's predictions.
Conclusion
This research introduces a technique called LIME that generates linear explanations for individual neurons in a neural network. These explanations reveal the relative importance of different input features in determining a neuron's activation, providing transparency into the model's decision-making process.
The authors demonstrate the effectiveness of LIME on several benchmark tasks, showing that the linear explanations align well with human intuitions about neuron behavior. This work represents an important step towards building more interpretable and trustworthy AI systems that can be reliably deployed in high-stakes applications.
Looking ahead, further research is needed to address the limitations of the LIME approach and explore ways to scale neuron-level explanations to the full network level. Nonetheless, this paper offers a valuable contribution to the growing field of explainable AI, with the potential to significantly improve our understanding of how neural networks operate.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
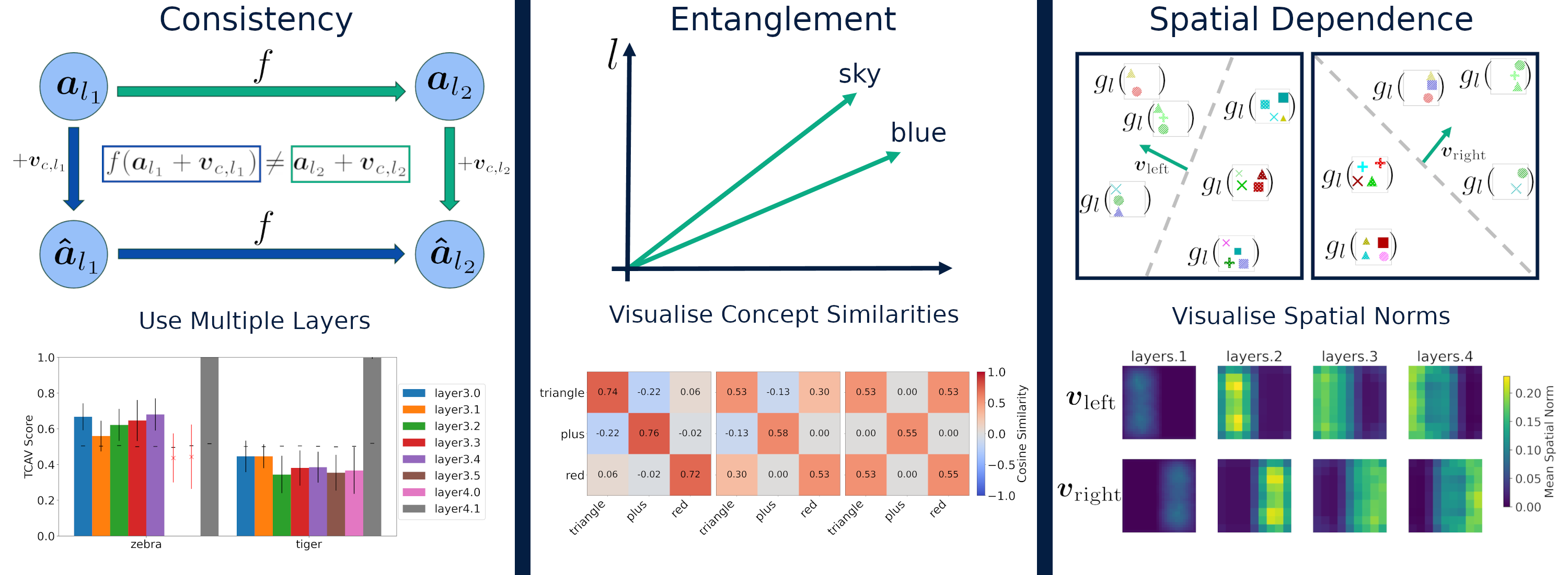
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
0
0
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
4/8/2024
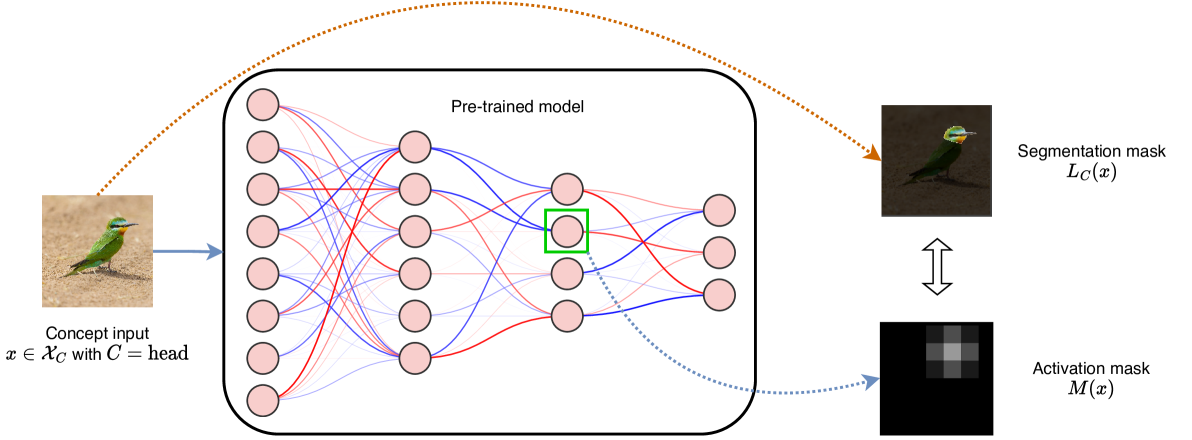
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Jae Hee Lee, Sergio Lanza, Stefan Wermter
0
0
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
5/6/2024
🎲
Error-margin Analysis for Hidden Neuron Activation Labels
Abhilekha Dalal, Rushrukh Rayan, Pascal Hitzler
0
0
Understanding how high-level concepts are represented within artificial neural networks is a fundamental challenge in the field of artificial intelligence. While existing literature in explainable AI emphasizes the importance of labeling neurons with concepts to understand their functioning, they mostly focus on identifying what stimulus activates a neuron in most cases, this corresponds to the notion of recall in information retrieval. We argue that this is only the first-part of a two-part job, it is imperative to also investigate neuron responses to other stimuli, i.e., their precision. We call this the neuron labels error margin.
5/17/2024
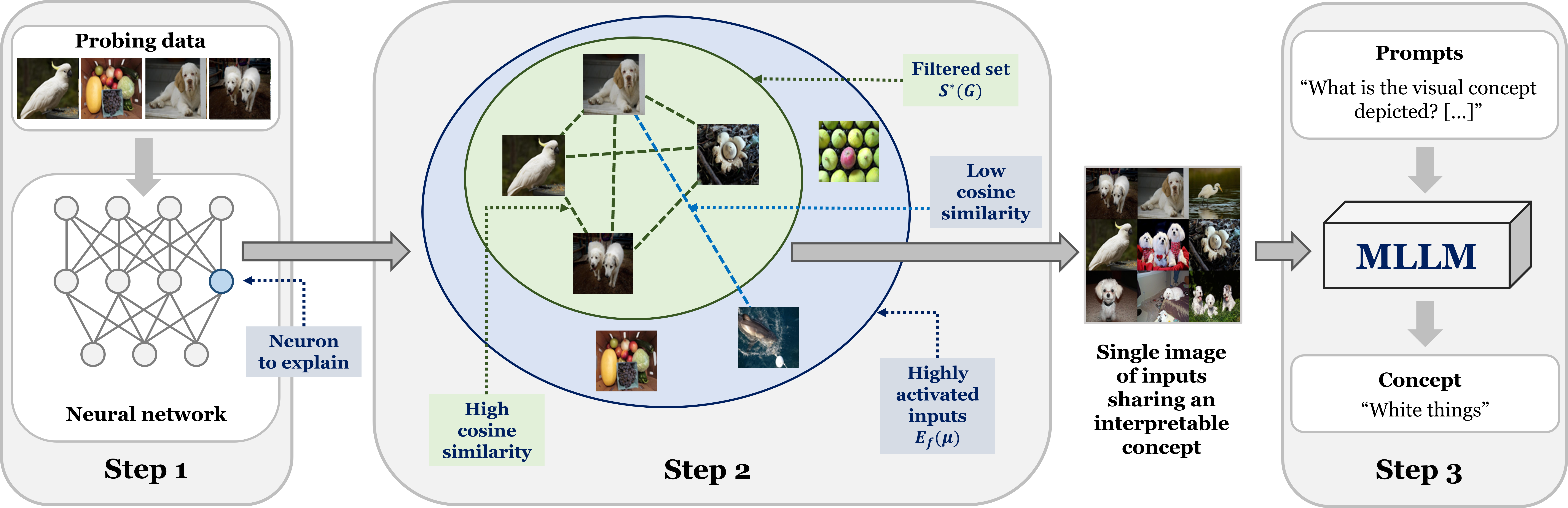
LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
Nhat Hoang-Xuan, Minh Vu, My T. Thai
0
0
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
6/14/2024