WWW: A Unified Framework for Explaining What, Where and Why of Neural Networks by Interpretation of Neuron Concepts
2402.18956
0
0

Abstract
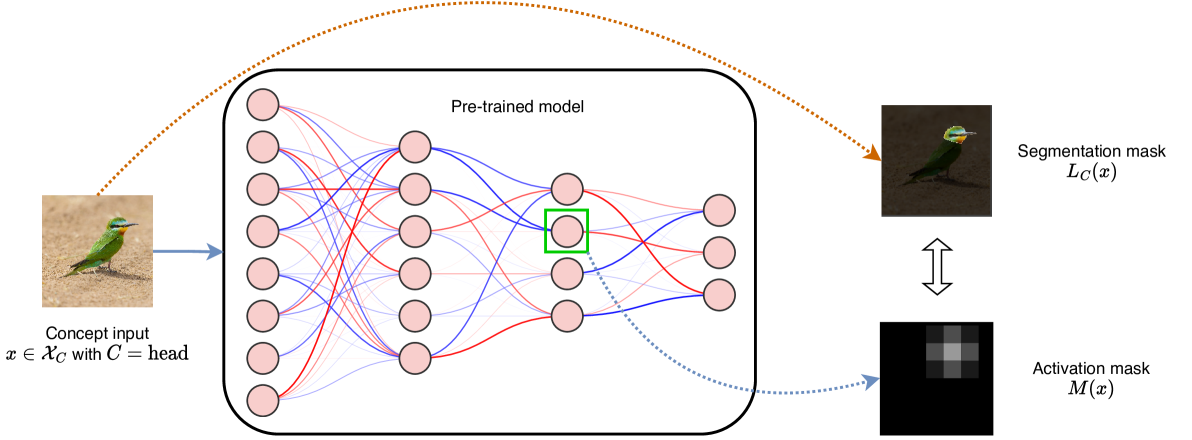
Recent advancements in neural networks have showcased their remarkable capabilities across various domains. Despite these successes, the black box problem still remains. Addressing this, we propose a novel framework, WWW, that offers the 'what', 'where', and 'why' of the neural network decisions in human-understandable terms. Specifically, WWW utilizes adaptive selection for concept discovery, employing adaptive cosine similarity and thresholding techniques to effectively explain 'what'. To address the 'where' and 'why', we proposed a novel combination of neuron activation maps (NAMs) with Shapley values, generating localized concept maps and heatmaps for individual inputs. Furthermore, WWW introduces a method for predicting uncertainty, leveraging heatmap similarities to estimate 'how' reliable the prediction is. Experimental evaluations of WWW demonstrate superior performance in both quantitative and qualitative metrics, outperforming existing methods in interpretability. WWW provides a unified solution for explaining 'what', 'where', and 'why', introducing a method for localized explanations from global interpretations and offering a plug-and-play solution adaptable to various architectures.
Create account to get full access
Overview
- The paper presents a unified framework called WWW (What, Where, and Why) for interpreting the concepts and activations of neurons in neural networks.
- The framework aims to provide a comprehensive understanding of what a neural network is learning, where it is learning it, and why it is making certain predictions.
- The paper introduces a novel concept-based approach to neural network interpretation, building on previous work on neuron-concept association and disentangled explanations.
Plain English Explanation
The paper proposes a new way to understand how neural networks work. Neural networks are powerful machine learning models that can learn to perform complex tasks, like image recognition or language understanding. However, it's often difficult to explain exactly how they arrive at their predictions.
The WWW framework aims to provide a more comprehensive explanation of neural networks. It looks at three key aspects:
- What: What concepts or features is the neural network learning to recognize?
- Where: Where in the neural network are these concepts being represented?
- Why: Why is the neural network making a particular prediction based on the learned concepts?
By analyzing these three elements, the researchers hope to give a more complete picture of how neural networks operate under the hood. This could be valuable for building trust in AI systems, as well as for debugging and improving the models.
The paper builds on previous work on neuron-concept association and disentangled explanations, which have looked at interpreting individual neurons and their connections to high-level concepts. The WWW framework takes a more holistic approach, considering the overall network architecture and decision-making process.
Technical Explanation
The key components of the WWW framework are:
-
Neuron Concept Extraction: The researchers develop a method to associate each neuron in the neural network with a set of high-level concepts that it represents. This builds on the neuron-concept association approach.
-
Spatial Concept Mapping: The framework maps the spatial distribution of these learned concepts within the neural network, identifying where different concepts are represented.
-
Concept-based Prediction Explanation: Finally, the framework analyzes how the activation of these learned concepts contributes to the network's overall predictions, providing an explanation of "why" the network made a particular decision.
The researchers evaluate their framework on various image classification and segmentation tasks, demonstrating its ability to provide comprehensive interpretations of neural network behavior. They show that the WWW framework can identify the key concepts learned by the network, locate where those concepts are represented, and explain how those concepts are used to make predictions.
Critical Analysis
The WWW framework represents a significant advancement in the field of neural network interpretation. By considering the "what", "where", and "why" of neural network behavior, it provides a more holistic understanding than previous approaches focused on individual neurons or concept activations.
However, the paper does acknowledge some limitations of the framework. For example, the concept extraction process may not capture all the relevant concepts learned by the network, and the spatial mapping may be sensitive to the network architecture. Additionally, the concept-based prediction explanation relies on certain assumptions about the network's decision-making process.
Further research could explore ways to address these limitations, such as by developing more robust concept extraction methods or exploring alternative approaches to prediction explanation. There may also be opportunities to extend the framework to other domains, such as natural language processing or reinforcement learning.
Overall, the WWW framework represents a significant step forward in making neural networks more interpretable and understandable to researchers and users. By providing a comprehensive view of what neural networks are learning and how they are making decisions, it has the potential to build trust, enable debugging and improvement, and advance the development of more transparent and accountable AI systems.
Conclusion
The paper presents the WWW framework, a novel approach to interpreting neural networks by examining what concepts they are learning, where those concepts are represented in the network, and how those concepts are used to make predictions. This comprehensive understanding of neural network behavior has the potential to enhance trust, enable debugging and improvement, and advance the development of more transparent and accountable AI systems.
The WWW framework builds on previous work on neuron-concept association and disentangled explanations, taking a more holistic approach to interpretation. While the framework has some limitations, it represents a significant advancement in the field of neural network interpretation and opens up new avenues for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Jae Hee Lee, Sergio Lanza, Stefan Wermter
0
0
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
5/6/2024
LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
Nhat Hoang-Xuan, Minh Vu, My T. Thai
0
0
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
6/14/2024

On the Value of Labeled Data and Symbolic Methods for Hidden Neuron Activation Analysis
Abhilekha Dalal, Rushrukh Rayan, Adrita Barua, Eugene Y. Vasserman, Md Kamruzzaman Sarker, Pascal Hitzler
0
0
A major challenge in Explainable AI is in correctly interpreting activations of hidden neurons: accurate interpretations would help answer the question of what a deep learning system internally detects as relevant in the input, demystifying the otherwise black-box nature of deep learning systems. The state of the art indicates that hidden node activations can, in some cases, be interpretable in a way that makes sense to humans, but systematic automated methods that would be able to hypothesize and verify interpretations of hidden neuron activations are underexplored. This is particularly the case for approaches that can both draw explanations from substantial background knowledge, and that are based on inherently explainable (symbolic) methods. In this paper, we introduce a novel model-agnostic post-hoc Explainable AI method demonstrating that it provides meaningful interpretations. Our approach is based on using a Wikipedia-derived concept hierarchy with approximately 2 million classes as background knowledge, and utilizes OWL-reasoning-based Concept Induction for explanation generation. Additionally, we explore and compare the capabilities of off-the-shelf pre-trained multimodal-based explainable methods. Our results indicate that our approach can automatically attach meaningful class expressions as explanations to individual neurons in the dense layer of a Convolutional Neural Network. Evaluation through statistical analysis and degree of concept activation in the hidden layer show that our method provides a competitive edge in both quantitative and qualitative aspects compared to prior work.
4/23/2024

A Self-explaining Neural Architecture for Generalizable Concept Learning
Sanchit Sinha, Guangzhi Xiong, Aidong Zhang
0
0
With the wide proliferation of Deep Neural Networks in high-stake applications, there is a growing demand for explainability behind their decision-making process. Concept learning models attempt to learn high-level 'concepts' - abstract entities that align with human understanding, and thus provide interpretability to DNN architectures. However, in this paper, we demonstrate that present SOTA concept learning approaches suffer from two major problems - lack of concept fidelity wherein the models fail to learn consistent concepts among similar classes and limited concept interoperability wherein the models fail to generalize learned concepts to new domains for the same task. Keeping these in mind, we propose a novel self-explaining architecture for concept learning across domains which - i) incorporates a new concept saliency network for representative concept selection, ii) utilizes contrastive learning to capture representative domain invariant concepts, and iii) uses a novel prototype-based concept grounding regularization to improve concept alignment across domains. We demonstrate the efficacy of our proposed approach over current SOTA concept learning approaches on four widely used real-world datasets. Empirical results show that our method improves both concept fidelity measured through concept overlap and concept interoperability measured through domain adaptation performance.
5/7/2024