Linguistic Analysis using Paninian System of Sounds and Finite State Machines

0
🔄
Sign in to get full access
Overview
- The paper explores the fundamental components of spoken languages, including phonology, morphology, and grammar.
- It proposes a novel approach to representing words as state transitions on a phonetic map, and defines Morphological Finite Automata (MFA) to capture relationships between words across languages.
- The study also introduces an "Ecosystem Model for Linguistic Development" with Sanskrit at the core, challenging the widely accepted family tree model.
Plain English Explanation
The study of spoken languages can be broken down into several key areas, such as phonology, which deals with the sounds of a language, morphology, which looks at the structure of words, and grammar, which governs the rules of a language.
When analyzing a language, researchers can focus on its syntax, semantics, and pragmatics. Languages can also be categorized based on their structure, such as root languages, inflectional languages, and stem languages. All these factors contribute to the vocabulary of a language, which can have both similarities and differences across different languages.
In this paper, the researchers use the Paninian system of sounds to create a phonetic map, and then represent words as "state transitions" on this map. They define Morphological Finite Automata (MFA) that can recognize words belonging to a specific group or "m-language" that spans multiple languages. This approach helps to better understand the relationships between words in spoken languages, both in a language-agnostic and language-specific manner.
Additionally, the study proposes an "Ecosystem Model for Linguistic Development" with Sanskrit at the core, which challenges the widely accepted family tree model of language evolution.
Technical Explanation
The researchers in this paper explore the fundamental components of spoken languages, including phonology, morphology, and grammar. They analyze languages based on their syntax, semantics, and pragmatics, and classify them as root languages, inflectional languages, and stem languages.
To study the relationships between words across languages, the researchers make use of the Paninian system of sounds to construct a phonetic map. They then represent words as state transitions on this phonetic map and define Morphological Finite Automata (MFA) that can accept words belonging to a given "m-language" (a group of related words that span multiple languages). This approach allows them to examine the inter-relationships between words in a language-agnostic and language-cognizant manner.
Based on their study and analysis, the researchers propose an "Ecosystem Model for Linguistic Development" with Sanskrit at the core, in contrast to the widely accepted family tree model of language evolution. This novel model aims to better explain the complex relationships and evolution of spoken languages.
Critical Analysis
The paper presents a unique and innovative approach to studying the relationships between words in spoken languages. By using the Paninian system of sounds and representing words as state transitions on a phonetic map, the researchers are able to capture the intricate connections between words that transcend individual languages.
However, the paper does not provide extensive details on the experimental design or the specific algorithms used to construct the phonetic map and define the Morphological Finite Automata. Additionally, the proposed "Ecosystem Model for Linguistic Development" with Sanskrit at the core is a significant departure from the widely accepted family tree model, and the authors do not offer a comprehensive justification or empirical evidence for this new model.
Further research would be needed to validate the effectiveness of the MFA-based approach and to thoroughly evaluate the Ecosystem Model in comparison to the family tree model. It would also be interesting to see how the proposed methods could be applied to a wider range of languages and to explore the potential applications in areas such as language learning and speech recognition.
Conclusion
This paper presents a novel approach to studying the relationships between words in spoken languages by representing them as state transitions on a phonetic map and defining Morphological Finite Automata (MFA) to capture cross-language word groups. The researchers also propose an "Ecosystem Model for Linguistic Development" with Sanskrit at the core, challenging the widely accepted family tree model of language evolution.
While the paper offers a unique perspective on language analysis, it lacks extensive details on the experimental design and justification for the Ecosystem Model. Further research and validation would be necessary to fully assess the potential of the MFA-based approach and the implications of the proposed linguistic development model.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Linguistic Analysis using Paninian System of Sounds and Finite State Machines
Shreekanth M Prabhu, Abhisek Midye
The study of spoken languages comprises phonology, morphology, and grammar. Analysis of a language can be based on its syntax, semantics, and pragmatics. The languages can be classified as root languages, inflectional languages, and stem languages. All these factors lead to the formation of vocabulary which has commonality/similarity as well as distinct and subtle differences across languages. In this paper, we make use of Paninian system of sounds to construct a phonetic map and then words are represented as state transitions on the phonetic map. Each group of related words that cut across languages is represented by a m-language (morphological language). Morphological Finite Automata (MFA) are defined that accept the words belonging to a given m-language. This exercise can enable us to better understand the inter-relationships between words in spoken languages in both language-agnostic and language-cognizant manner. Based on our study and analysis, we propose an Ecosystem Model for Linguistic Development with Sanskrit at the core, in place of the widely accepted family tree model.
Read more4/17/2024

0
LLMs' morphological analyses of complex FST-generated Finnish words
Anssi Moisio, Mathias Creutz, Mikko Kurimo
Rule-based language processing systems have been overshadowed by neural systems in terms of utility, but it remains unclear whether neural NLP systems, in practice, learn the grammar rules that humans use. This work aims to shed light on the issue by evaluating state-of-the-art LLMs in a task of morphological analysis of complex Finnish noun forms. We generate the forms using an FST tool, and they are unlikely to have occurred in the training sets of the LLMs, therefore requiring morphological generalisation capacity. We find that GPT-4-turbo has some difficulties in the task while GPT-3.5-turbo struggles and smaller models Llama2-70B and Poro-34B fail nearly completely.
Read more7/12/2024
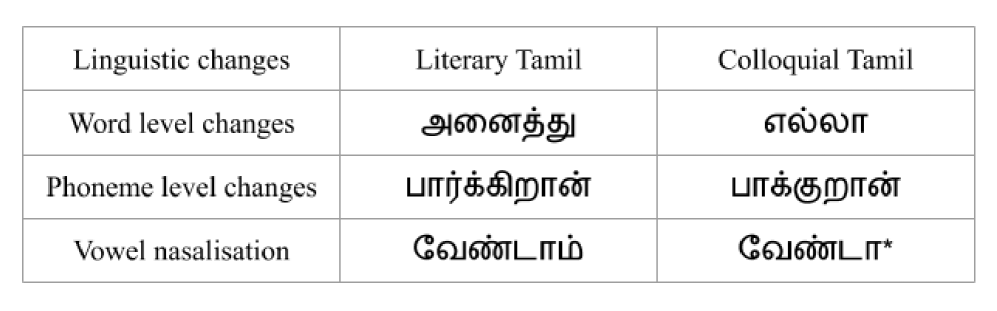
0
Literary and Colloquial Dialect Identification for Tamil using Acoustic Features
M. Nanmalar, P. Vijayalakshmi, T. Nagarajan
The evolution and diversity of a language is evident from it's various dialects. If the various dialects are not addressed in technological advancements like automatic speech recognition and speech synthesis, there is a chance that these dialects may disappear. Speech technology plays a role in preserving various dialects of a language from going extinct. In order to build a full fledged automatic speech recognition system that addresses various dialects, an Automatic Dialect Identification (ADI) system acting as the front end is required. This is similar to how language identification systems act as front ends to automatic speech recognition systems that handle multiple languages. The current work proposes a way to identify two popular and broadly classified Tamil dialects, namely literary and colloquial Tamil. Acoustical characteristics rather than phonetics and phonotactics are used, alleviating the requirement of language-dependant linguistic tools. Hence one major advantage of the proposed method is that it does not require an annotated corpus, hence it can be easily adapted to other languages. Gaussian Mixture Models (GMM) using Mel Frequency Cepstral Coefficient (MFCC) features are used to perform the classification task. The experiments yielded an error rate of 12%. Vowel nasalization, as being the reason for this good performance, is discussed. The number of mixture models for the GMM is varied and the performance is analysed.
Read more8/28/2024
↗️
0
Morphosyntactic Analysis for CHILDES
Houjun Liu, Brian MacWhinney
Language development researchers are interested in comparing the process of language learning across languages. Unfortunately, it has been difficult to construct a consistent quantitative framework for such comparisons. However, recent advances in AI (Artificial Intelligence) and ML (Machine Learning) are providing new methods for ASR (automatic speech recognition) and NLP (natural language processing) that can be brought to bear on this problem. Using the Batchalign2 program (Liu et al., 2023), we have been transcribing and linking data for the CHILDES database and have applied the UD (Universal Dependencies) framework to provide a consistent and comparable morphosyntactic analysis for 27 languages. These new resources open possibilities for deeper crosslinguistic study of language learning.
Read more7/18/2024