Lion Secretly Solves Constrained Optimization: As Lyapunov Predicts

0
🤖
Sign in to get full access
Overview
- A new optimizer called Lion has been discovered through program search and shows promising results in training large AI models.
- Lion performs comparably or better than AdamW but with greater memory efficiency.
- Lion incorporates elements from several existing algorithms, including signed momentum, decoupled weight decay, Polak, and Nesterov momentum, but does not fit into any existing category of theoretically grounded optimizers.
- The lack of theoretical clarity around Lion limits opportunities to further enhance and expand its efficacy.
Plain English Explanation
The paper discusses a new optimization algorithm called Lion that was discovered through a process of random searches. This new algorithm, Lion, has shown promising results when training large AI models, performing as well as or better than the popular AdamW optimizer, while using less memory.
Lion incorporates ideas from several existing optimization algorithms, such as signed momentum, decoupled weight decay, and Nesterov momentum. However, it doesn't neatly fit into any of the existing categories of theoretically-grounded optimizers. This lack of theoretical understanding makes it difficult to further improve and expand the capabilities of Lion.
Technical Explanation
The paper aims to provide a deeper understanding of the Lion optimizer by analyzing it from both a continuous-time and discrete-time perspective. The researchers develop a new Lyapunov function to demonstrate that Lion is a theoretically novel and principled approach for minimizing a general loss function $f(x)$ while enforcing a bound constraint $|x|_infty \leq 1/\lambda$, where $\lambda$ represents the weight decay coefficient.
The analysis extends to a broader family of Lion-$\kappa$ algorithms, where the $\text{sign}(\cdot)$ operator in Lion is replaced by the subgradient of a convex function $\kappa$, leading to the solution of a general composite optimization problem of $\min_x f(x) + \kappa^*(x)$. This theoretical framework provides valuable insights into the dynamics of Lion and paves the way for further improvements and extensions of Lion-related algorithms.
Critical Analysis
While the paper provides a thorough theoretical analysis of the Lion optimizer, it acknowledges that the lack of a clear theoretical foundation for the algorithm limits opportunities to further enhance its capabilities. The researchers note that even though Lion appears to perform well as a general-purpose optimizer, its underlying principles are not fully understood.
One potential area for further research could be exploring the practical implications of the Lion-$\kappa$ framework and investigating how different choices of the convex function $\kappa$ might impact the optimizer's performance on various tasks and applications.
Additionally, it would be valuable to understand the specific circumstances or problem domains where Lion excels compared to other well-established optimizers, as this could inform the development of more targeted improvements or extensions to the algorithm.
Conclusion
The paper presents a new optimizer called Lion that has shown promising results in training large AI models, performing on par or better than AdamW while being more memory-efficient. However, the lack of a clear theoretical foundation for Lion limits opportunities to further enhance and expand its capabilities.
The researchers have developed a new Lyapunov function to analyze Lion from both continuous-time and discrete-time perspectives, providing valuable insights into the algorithm's dynamics. This work paves the way for further research and development of Lion-related optimization algorithms, which could lead to more powerful and adaptable tools for training large-scale AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Lion Secretly Solves Constrained Optimization: As Lyapunov Predicts
Lizhang Chen, Bo Liu, Kaizhao Liang, Qiang Liu
Lion (Evolved Sign Momentum), a new optimizer discovered through program search, has shown promising results in training large AI models. It performs comparably or favorably to AdamW but with greater memory efficiency. As we can expect from the results of a random search program, Lion incorporates elements from several existing algorithms, including signed momentum, decoupled weight decay, Polak, and Nesterov momentum, but does not fit into any existing category of theoretically grounded optimizers. Thus, even though Lion appears to perform well as a general-purpose optimizer for a wide range of tasks, its theoretical basis remains uncertain. This lack of theoretical clarity limits opportunities to further enhance and expand Lion's efficacy. This work aims to demystify Lion. Based on both continuous-time and discrete-time analysis, we demonstrate that Lion is a theoretically novel and principled approach for minimizing a general loss function $f(x)$ while enforcing a bound constraint $|x|_infty leq 1/lambda$. Lion achieves this through the incorporation of decoupled weight decay, where $lambda$ represents the weight decay coefficient. Our analysis is made possible by the development of a new Lyapunov function for the Lion updates. It applies to a broader family of Lion-$kappa$ algorithms, where the $text{sign}(cdot)$ operator in Lion is replaced by the subgradient of a convex function $kappa$, leading to the solution of a general composite optimization problem of $min_x f(x) + kappa^*(x)$. Our findings provide valuable insights into the dynamics of Lion and pave the way for further improvements and extensions of Lion-related algorithms.
Read more4/22/2024
🛠️
0
Dynamic Multi-Objective Lion Swarm Optimization with Multi-strategy Fusion: An application in 6R robot trajectory
Bao Liu, Tianbao Liu, Zhongshuo Hu, Fei Ye, Lei Gao
The advancement of industrialization has spurred the development of innovative swarm intelligence algorithms, with Lion Swarm Optimization (LSO) notable for its robustness, parallelism, simplicity, and efficiency. While LSO excels in single-objective optimization, its multi-objective variants face challenges such as poor initialization, local optima entrapment, and so on. This study proposes Dynamic Multi-Objective Lion Swarm Optimization with Multi-strategy Fusion (MF-DMOLSO) to address these limitations. MF-DMOLSO comprises three key components: initialization, swarm position update, and external archive update. The initialization unit employs chaotic mapping for uniform population distribution. The position update unit enhances behavior patterns and step size formulas for cub lions, incorporating crowding degree sorting, Pareto non-dominated sorting, and Levy flight to improve convergence speed and global search capabilities. Reference points guide convergence in higher-dimensional spaces, maintaining population diversity. An adaptive cold-hot start strategy generates a population responsive to environmental changes. The external archive update unit re-evaluates solutions based on non-domination and diversity to form the new population. Evaluations on benchmark functions showed MF-DMOLSO surpassed multi-objective particle swarm optimization, non-dominated sorting genetic algorithm II, and multi-objective lion swarm optimization, exceeding 90% accuracy for two-objective and 97% for three-objective problems. Compared to non-dominated sorting genetic algorithm III, MF-DMOLSO showed a 60% improvement. Applied to 6R robot trajectory planning, MF-DMOLSO optimized running time and maximum acceleration to 8.3s and 0.3pi rad/s^2, achieving a set coverage rate of 70.97% compared to 2% by multi-objective particle swarm optimization, thus improving efficiency and reducing mechanical dither.
Read more6/11/2024
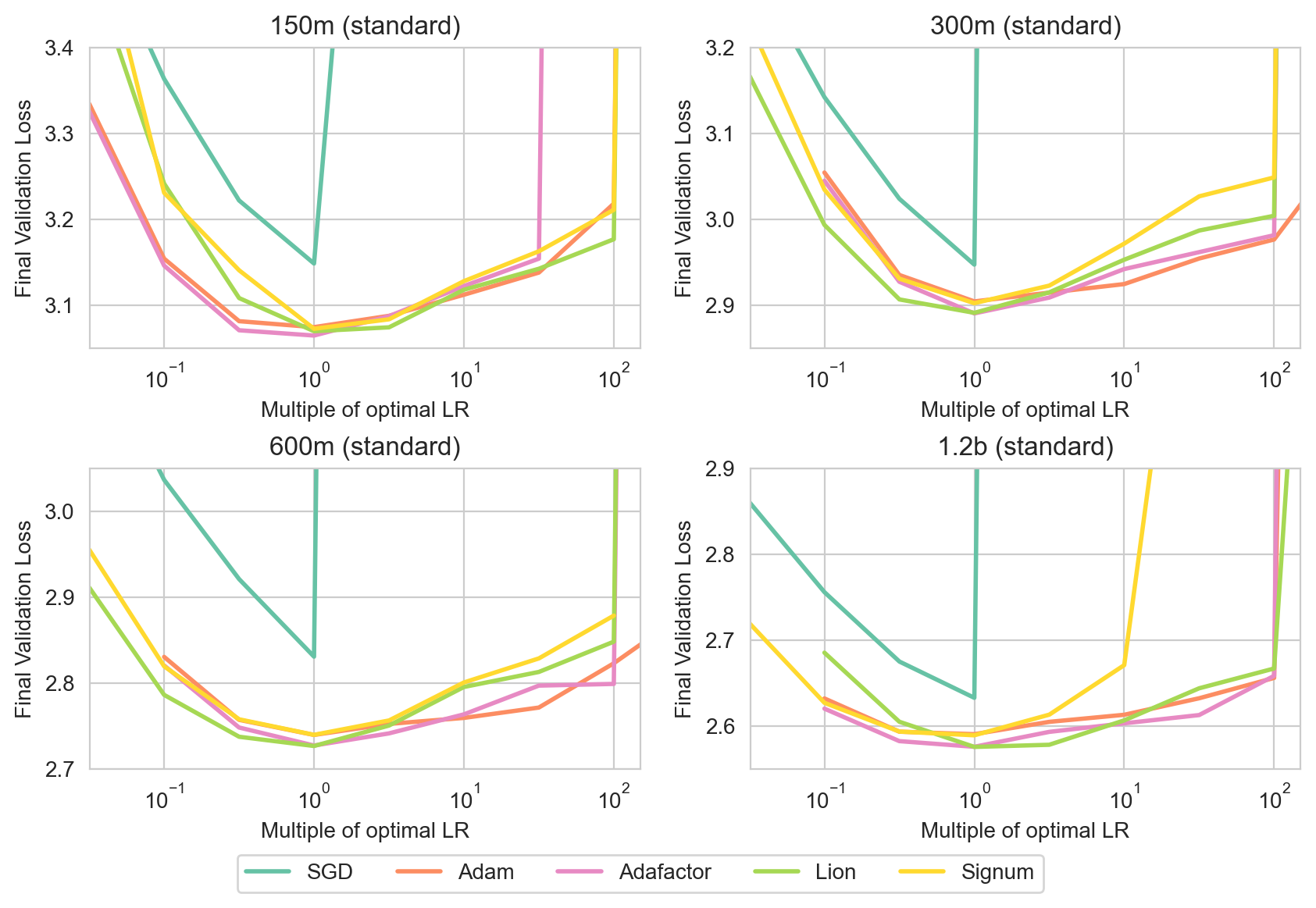
0
Deconstructing What Makes a Good Optimizer for Language Models
Rosie Zhao, Depen Morwani, David Brandfonbrener, Nikhil Vyas, Sham Kakade
Training language models becomes increasingly expensive with scale, prompting numerous attempts to improve optimization efficiency. Despite these efforts, the Adam optimizer remains the most widely used, due to a prevailing view that it is the most effective approach. We aim to compare several optimization algorithms, including SGD, Adafactor, Adam, and Lion, in the context of autoregressive language modeling across a range of model sizes, hyperparameters, and architecture variants. Our findings indicate that, except for SGD, these algorithms all perform comparably both in their optimal performance and also in terms of how they fare across a wide range of hyperparameter choices. Our results suggest to practitioners that the choice of optimizer can be guided by practical considerations like memory constraints and ease of implementation, as no single algorithm emerged as a clear winner in terms of performance or stability to hyperparameter misspecification. Given our findings, we further dissect these approaches, examining two simplified versions of Adam: a) signed momentum (Signum) which we see recovers both the performance and hyperparameter stability of Adam and b) Adalayer, a layerwise variant of Adam which we introduce to study Adam's preconditioning. Examining Adalayer leads us to the conclusion that the largest impact of Adam's preconditioning is restricted to the last layer and LayerNorm parameters, and, perhaps surprisingly, the remaining layers can be trained with SGD.
Read more7/12/2024
🛠️
0
Leo: Lagrange Elementary Optimization
Aso M. Aladdin, Tarik A. Rashid
Global optimization problems are frequently solved using the practical and efficient method of evolutionary sophistication. But as the original problem becomes more complex, so does its efficacy and expandability. Thus, the purpose of this research is to introduce the Lagrange Elementary Optimization (Leo) as an evolutionary method, which is self-adaptive inspired by the remarkable accuracy of vaccinations using the albumin quotient of human blood. They develop intelligent agents using their fitness function value after gene crossing. These genes direct the search agents during both exploration and exploitation. The main objective of the Leo algorithm is presented in this paper along with the inspiration and motivation for the concept. To demonstrate its precision, the proposed algorithm is validated against a variety of test functions, including 19 traditional benchmark functions and the CECC06 2019 test functions. The results of Leo for 19 classic benchmark test functions are evaluated against DA, PSO, and GA separately, and then two other recent algorithms such as FDO and LPB are also included in the evaluation. In addition, the Leo is tested by ten functions on CECC06 2019 with DA, WOA, SSA, FDO, LPB, and FOX algorithms distinctly. The cumulative outcomes demonstrate Leo's capacity to increase the starting population and move toward the global optimum. Different standard measurements are used to verify and prove the stability of Leo in both the exploration and exploitation phases. Moreover, Statistical analysis supports the findings results of the proposed research. Finally, novel applications in the real world are introduced to demonstrate the practicality of Leo.
Read more8/27/2024