LIRE: listwise reward enhancement for preference alignment
2405.13516
0
0
🔄
Abstract
Recently, tremendous strides have been made to align the generation of Large Language Models (LLMs) with human values to mitigate toxic or unhelpful content. Leveraging Reinforcement Learning from Human Feedback (RLHF) proves effective and is widely adopted by researchers. However, implementing RLHF is complex, and its sensitivity to hyperparameters renders achieving stable performance and scalability challenging. Furthermore, prevailing approaches to preference alignment primarily concentrate on pairwise comparisons, with limited exploration into multi-response scenarios, thereby overlooking the potential richness within the candidate pool. For the above reasons, we propose a new approach: Listwise Reward Enhancement for Preference Alignment (LIRE), a gradient-based reward optimization approach that incorporates the offline rewards of multiple responses into a streamlined listwise framework, thus eliminating the need for online sampling during training. LIRE is straightforward to implement, requiring minimal parameter tuning, and seamlessly aligns with the pairwise paradigm while naturally extending to multi-response scenarios. Moreover, we introduce a self-enhancement algorithm aimed at iteratively refining the reward during training. Our experiments demonstrate that LIRE consistently outperforms existing methods across several benchmarks on dialogue and summarization tasks, with good transferability to out-of-distribution data, assessed using proxy reward models and human annotators.
Create account to get full access
Overview
- Researchers have made significant progress in aligning the generation of Large Language Models (LLMs) with human values to mitigate toxic or unhelpful content.
- Reinforcement Learning from Human Feedback (RLHF) is a widely adopted approach, but it is complex to implement and sensitive to hyperparameters, making it challenging to achieve stable performance and scalability.
- Existing preference alignment methods primarily focus on pairwise comparisons, overlooking the potential richness within the candidate pool in multi-response scenarios.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. However, there have been concerns about these models producing content that may be harmful or go against human values. Researchers have been working on ways to "align" these models with human values, so they generate more helpful and less toxic content.
One popular approach is called Reinforcement Learning from Human Feedback (RLHF). This method uses feedback from humans to train the model to produce responses that are preferred by humans. However, implementing RLHF can be complex, and the model's performance can be sensitive to various settings (called "hyperparameters"), making it challenging to achieve consistent and scalable results.
Additionally, most existing preference alignment methods focus on comparing pairs of responses, rather than looking at a list of multiple responses. This may overlook important information that could be found in how the model ranks and selects from a broader set of potential responses.
Technical Explanation
To address these challenges, the researchers propose a new approach called Listwise Reward Enhancement for Preference Alignment (LIRE). LIRE is a gradient-based reward optimization method that incorporates the offline rewards of multiple responses into a streamlined listwise framework, eliminating the need for online sampling during training.
The key features of LIRE are:
- Listwise Approach: LIRE considers the model's ranking and selection of a list of potential responses, rather than just pairwise comparisons. This allows the model to learn from the relative preferences within a broader candidate pool.
- Gradient-based Optimization: LIRE uses a gradient-based optimization procedure to directly update the model's parameters based on the offline rewards of the response list, without the need for expensive online sampling.
- Self-Enhancement: The researchers introduce a self-enhancement algorithm that iteratively refines the reward function during training, further improving the model's alignment with human preferences.
The researchers evaluate LIRE on several benchmarks for dialogue and summarization tasks, and find that it consistently outperforms existing methods. Additionally, LIRE demonstrates good transferability to out-of-distribution data, as assessed using proxy reward models and human annotations.
Critical Analysis
While LIRE offers a promising approach to preference alignment, the researchers acknowledge some limitations and areas for further research:
- Scalability: The researchers note that the self-enhancement algorithm may be computationally expensive, particularly as the model size and complexity increase. Exploring more efficient ways to refine the reward function could be an important area for future work.
- Generalization: The researchers use proxy reward models and human annotations to assess the model's performance on out-of-distribution data. However, the true test of the model's alignment with human values would be its behavior in real-world, open-ended interactions. Further research is needed to understand how well LIRE-trained models perform in such settings.
- Interpretability: The researchers do not provide an in-depth analysis of the types of preferences and values that LIRE-trained models have learned. Understanding the model's internal decision-making process could be valuable for transparency and building trust in the technology.
Conclusion
The Listwise Reward Enhancement for Preference Alignment (LIRE) approach proposed in this research offers a promising step forward in aligning large language models with human values. By incorporating the relative preferences within a broader set of potential responses, LIRE demonstrates improved performance and scalability compared to existing pairwise-based methods.
While there are still some challenges to address, the researchers' work highlights the importance of exploring more holistic and efficient methods for preference alignment. As large language models become increasingly prevalent, ensuring their alignment with human values will be crucial for building safe and beneficial AI systems that can be deployed with confidence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
0
0
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
6/26/2024
LiPO: Listwise Preference Optimization through Learning-to-Rank
Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mohammad Saleh, Simon Baumgartner, Jialu Liu, Peter J. Liu, Xuanhui Wang
0
0
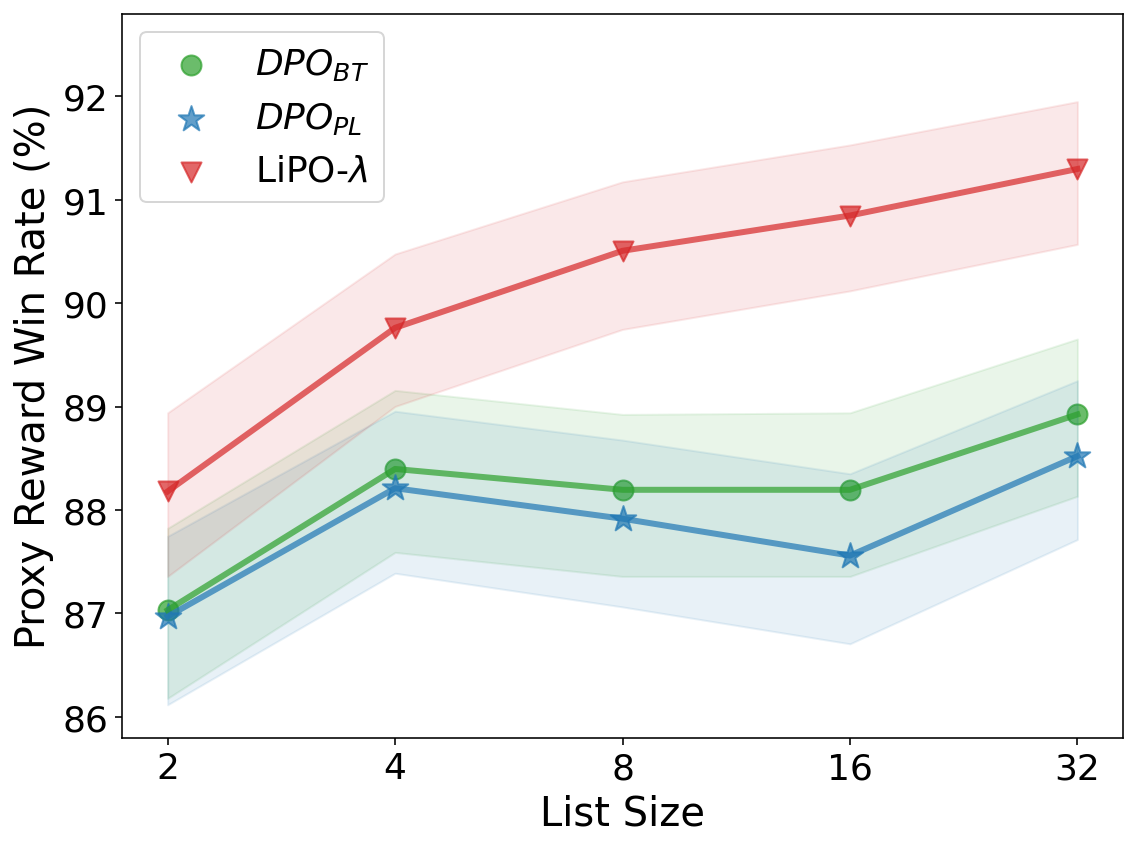
Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a thorough study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a textit{listwise} ranking problem and describe the LiPO framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment with DPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-$lambda$, which leverages a state-of-the-art textit{listwise} ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-$lambda$ can outperform DPO variants and SLiC by a clear margin on several preference alignment tasks with both curated and real rankwise preference data.
5/24/2024

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024
🏅
Multi-turn Reinforcement Learning from Preference Human Feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, Avinatan Hassidim, Yossi Matias, R'emi Munos
0
0
Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
5/24/2024