The Reason behind Good or Bad: Towards a Better Mathematical Verifier with Natural Language Feedback

1

Sign in to get full access
Overview
- This paper proposes a new approach to mathematical verification that provides natural language feedback to users.
- It explores ways to improve the accuracy and transparency of mathematical reasoning systems by incorporating natural language explanations.
- The goal is to develop a better mathematical verifier that can guide users towards correct solutions and help them understand their mistakes.
Plain English Explanation
The paper describes a new system for verifying and providing feedback on mathematical reasoning. Current mathematical reasoning systems often focus solely on whether the final answer is correct, without explaining the reasoning behind it. This can make it difficult for users to understand where they went wrong and how to improve.
The proposed system aims to provide more detailed, natural language feedback to users. It uses natural language processing techniques to analyze the user's work and identify areas for improvement. The system can then generate explanations that guide the user towards the correct solution, helping them learn from their mistakes.
This approach is motivated by research showing that evaluating mathematical reasoning goes beyond just accuracy. By incorporating natural language feedback, the system can provide a richer, more informative assessment of the user's work.
The ultimate goal is to build a "better mathematical verifier" - one that is more accurate, transparent, and helpful in guiding users to correct solutions. This could have important implications for education, research, and any domain that relies on mathematical reasoning.
Technical Explanation
The paper proposes a new architecture for a mathematical reasoning system that incorporates natural language feedback. The key components are:
-
Mathematical Reasoning Model: This module takes the user's mathematical work as input and generates a predicted solution and reasoning steps.
-
Natural Language Feedback Generator: This module analyzes the user's work and the reasoning model's predictions to generate natural language feedback explaining the strengths and weaknesses of the user's approach.
-
Feedback Integration: The natural language feedback is then integrated with the reasoning model's output to provide a comprehensive assessment to the user.
The authors evaluate this approach on a dataset of mathematical induction proofs, demonstrating that the natural language feedback can improve user understanding and learning compared to a system that only provides a binary correct/incorrect result.
They also explore ways to efficiently improve the mathematical reasoning capabilities of the underlying model, such as using a two-stage training process and leveraging external mathematical knowledge.
Critical Analysis
The paper presents a promising approach to enhancing mathematical verification systems, but there are a few potential limitations and areas for further research:
-
Scope of Feedback: The current system focuses on providing feedback on the reasoning process, but it could be expanded to also give feedback on the mathematical concepts, notation, and problem-solving strategies used by the user.
-
Generalization to Other Tasks: The evaluation is limited to mathematical induction proofs, so it's unclear how well the approach would generalize to other types of mathematical problems or reasoning tasks. More research is needed to evaluate the system's versatility.
-
User Interaction and Iterative Feedback: The paper does not explore how users might interact with the system over multiple iterations, refining their work based on the provided feedback. Investigating this could reveal additional insights and opportunities for improvement.
Overall, the paper presents a thoughtful and well-designed approach to enhancing mathematical verification systems. The incorporation of natural language feedback is a promising direction that could lead to more effective and transparent tools for supporting mathematical reasoning.
Conclusion
This paper introduces a new approach to mathematical verification that combines a reasoning model with a natural language feedback generator. By providing users with detailed explanations of their mistakes and guidance towards the correct solution, the system aims to improve understanding and learning, going beyond simply evaluating the final answer.
The proposed architecture and evaluation on mathematical induction proofs demonstrate the potential of this approach. Further research is needed to explore its generalization to other mathematical tasks, as well as to investigate more advanced user interaction and iterative feedback mechanisms.
Overall, this work represents an important step towards building better mathematical reasoning systems that can truly support and enhance human understanding of complex mathematical concepts and problem-solving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
The Reason behind Good or Bad: Towards a Better Mathematical Verifier with Natural Language Feedback
Bofei Gao, Zefan Cai, Runxin Xu, Peiyi Wang, Ce Zheng, Runji Lin, Keming Lu, Dayiheng Liu, Chang Zhou, Wen Xiao, Junjie Hu, Tianyu Liu, Baobao Chang
Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6% (86.6% $rightarrow$ 88.2%) on GSM8K and 0.8% (37.8% $rightarrow$ 38.6%) on MATH. We have released our code and data for further exploration.
Read more7/9/2024
💬
0
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether small (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
Read more6/7/2024
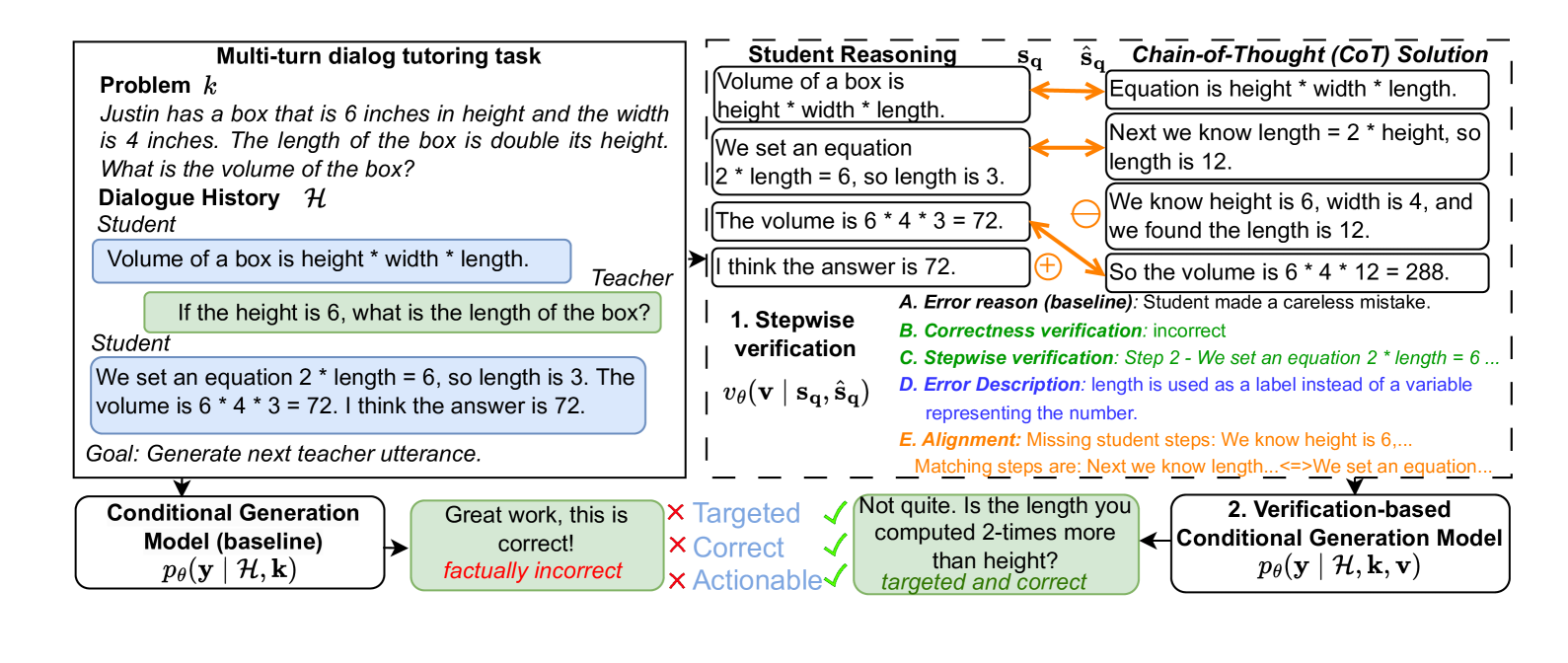
0
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Nico Daheim, Jakub Macina, Manu Kapur, Iryna Gurevych, Mrinmaya Sachan
Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Read more7/15/2024

0
Autograding Mathematical Induction Proofs with Natural Language Processing
Chenyan Zhao, Mariana Silva, Seth Poulsen
In mathematical proof education, there remains a need for interventions that help students learn to write mathematical proofs. Research has shown that timely feedback can be very helpful to students learning new skills. While for many years natural language processing models have struggled to perform well on tasks related to mathematical texts, recent developments in natural language processing have created the opportunity to complete the task of giving students instant feedback on their mathematical proofs. In this paper, we present a set of training methods and models capable of autograding freeform mathematical proofs by leveraging existing large language models and other machine learning techniques. The models are trained using proof data collected from four different proof by induction problems. We use four different robust large language models to compare their performances, and all achieve satisfactory performances to various degrees. Additionally, we recruit human graders to grade the same proofs as the training data, and find that the best grading model is also more accurate than most human graders. With the development of these grading models, we create and deploy an autograder for proof by induction problems and perform a user study with students. Results from the study shows that students are able to make significant improvements to their proofs using the feedback from the autograder, but students still do not trust the AI autograders as much as they trust human graders. Future work can improve on the autograder feedback and figure out ways to help students trust AI autograders.
Read more6/18/2024