Evaluating Mathematical Reasoning Beyond Accuracy

0

Sign in to get full access
Overview
- This paper explores ways to evaluate the mathematical reasoning capabilities of large language models (LLMs) beyond just measuring accuracy on specific tasks.
- The authors propose new evaluation metrics and techniques that aim to capture a more holistic understanding of how LLMs reason about mathematical problems.
- The paper builds on previous work on evaluating the reasoning abilities of LLMs and enhancing LLMs' mathematical reasoning capabilities.
Plain English Explanation
The paper focuses on finding better ways to assess how well large language models (LLMs) can reason about and solve mathematical problems. Accuracy, or getting the right answer, is an important metric, but it doesn't tell the whole story. The authors argue that we should also look at things like:
- How LLMs break down and approach mathematical problems
- The logical steps they take to arrive at solutions
- Their ability to explain their reasoning in natural language
- Their capacity for interventional reasoning (understanding how changes to a problem would affect the solution)
By evaluating LLMs on these types of measures, the authors hope to gain a deeper understanding of their mathematical reasoning abilities, which could ultimately lead to models that can better assist humans with mathematical tasks and problem-solving.
Technical Explanation
The paper proposes a new evaluation framework for assessing the mathematical reasoning capabilities of LLMs. The key components of this framework include:
-
Problem Formulation: The authors define a set of mathematical problems that test different aspects of reasoning, such as step-by-step solution paths, natural language explanations, and interventional reasoning.
-
Evaluation Metrics: In addition to accuracy, the framework includes metrics that capture the quality and coherence of the models' reasoning processes, such as step-level similarity to human-generated solutions and the plausibility of natural language justifications.
-
Evaluation Datasets: The authors curate a dataset of mathematical problems and human-generated solutions to serve as a benchmark for evaluating LLMs.
-
Evaluation Procedures: The paper outlines protocols for systematically testing LLMs on the proposed evaluation tasks and metrics, including prompting strategies and data collection methods.
The authors demonstrate the application of this framework by evaluating several state-of-the-art LLMs on a range of mathematical reasoning tasks. The results suggest that while these models can achieve high accuracy, they still struggle with aspects of mathematical reasoning beyond just finding the correct answer.
Critical Analysis
The paper presents a compelling approach for evaluating the mathematical reasoning capabilities of LLMs. The proposed framework addresses important limitations of existing evaluation methods that focus solely on accuracy. By considering factors like step-by-step reasoning and natural language explanations, the authors aim to gain a more nuanced understanding of how LLMs approach mathematical problem-solving.
That said, the paper acknowledges several caveats and limitations of the current work. For example, the evaluation dataset and tasks may not capture the full breadth of mathematical reasoning skills, and the metrics used to assess reasoning quality could be further refined and validated. Additionally, the paper does not delve into the potential biases or systematic errors that LLMs may exhibit in their mathematical reasoning, which could be an important area for future research.
Overall, the paper makes a valuable contribution to the ongoing efforts to assess and improve the reasoning capabilities of large language models. By shifting the focus beyond just accuracy, the authors pave the way for the development of LLMs that can more effectively assist humans in mathematical problem-solving and reasoning tasks.
Conclusion
This paper presents a novel framework for evaluating the mathematical reasoning capabilities of large language models (LLMs) beyond just measuring accuracy. By considering factors like step-by-step solution paths, natural language explanations, and interventional reasoning, the authors aim to gain a more holistic understanding of how LLMs approach and solve mathematical problems.
The proposed evaluation framework and the insights gleaned from its application to state-of-the-art LLMs have the potential to drive further advancements in the field of mathematical reasoning in AI. As LLMs continue to play an increasingly important role in assisting humans with complex tasks, the ability to accurately assess and enhance their reasoning capabilities will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Mathematical Reasoning Beyond Accuracy
Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, Pengfei Liu
The leaderboard of Large Language Models (LLMs) in mathematical tasks has been continuously updated. However, the majority of evaluations focus solely on the final results, neglecting the quality of the intermediate steps. This oversight can mask underlying problems, such as logical errors or unnecessary steps in the reasoning process. To measure reasoning beyond final-answer accuracy, we introduce ReasonEval, a new methodology for evaluating the quality of reasoning steps. ReasonEval employs $textit{validity}$ and $textit{redundancy}$ to characterize the reasoning quality, as well as accompanying LLMs to assess them automatically. Instantiated by base models that possess strong mathematical knowledge and trained with high-quality labeled data, ReasonEval achieves state-of-the-art performance on human-labeled datasets and can accurately detect different types of errors generated by perturbation. When applied to evaluate LLMs specialized in math, we find that an increase in final-answer accuracy does not necessarily guarantee an improvement in the overall quality of the reasoning steps for challenging mathematical problems. Additionally, we observe that ReasonEval can play a significant role in data selection. We release the best-performing model, meta-evaluation script, and all evaluation results at https://github.com/GAIR-NLP/ReasonEval.
Read more4/9/2024

0
Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on sophisticated reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
Read more8/7/2024
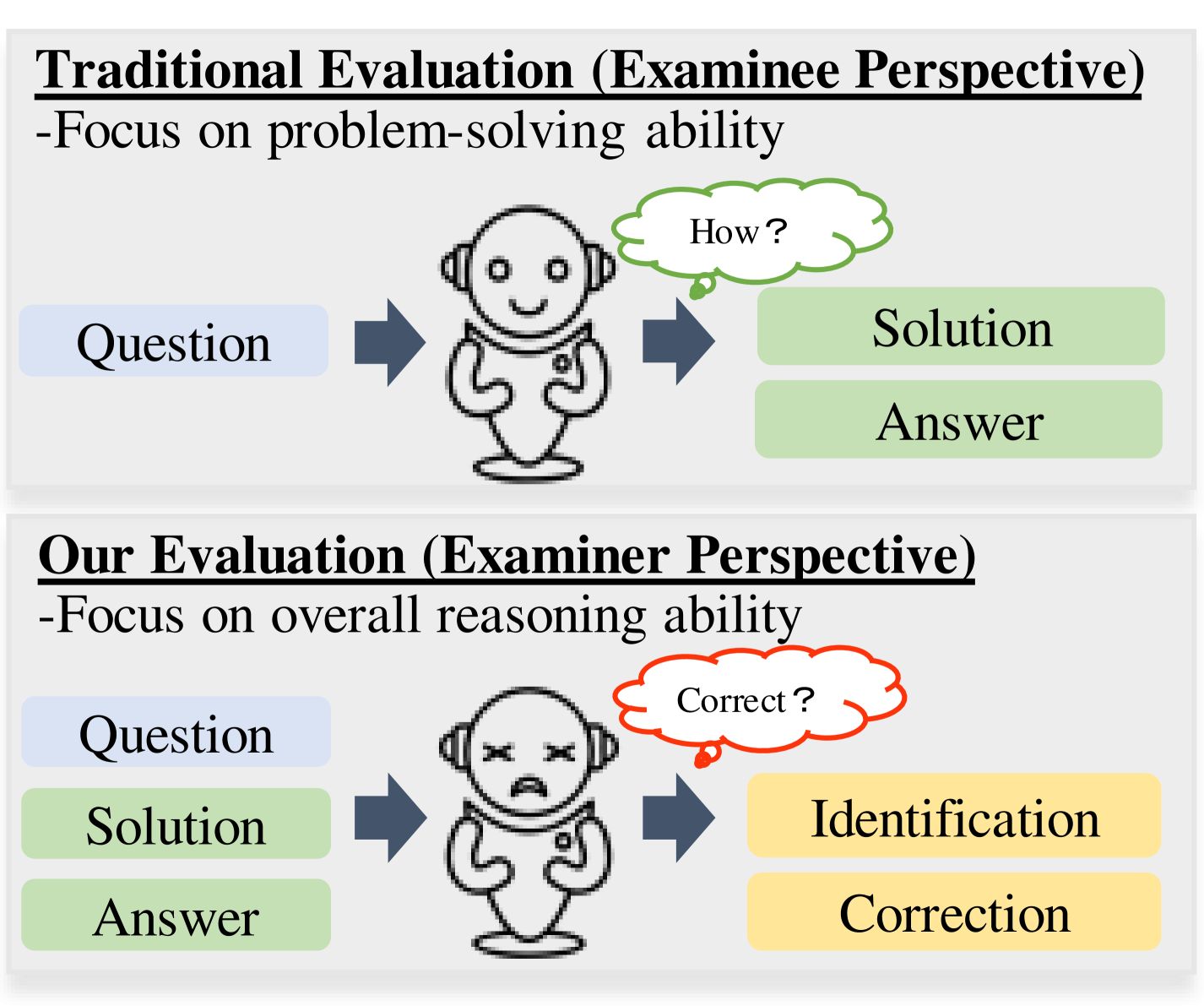
0
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024

0
Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist
Zihao Zhou, Shudong Liu, Maizhen Ning, Wei Liu, Jindong Wang, Derek F. Wong, Xiaowei Huang, Qiufeng Wang, Kaizhu Huang
Exceptional mathematical reasoning ability is one of the key features that demonstrate the power of large language models (LLMs). How to comprehensively define and evaluate the mathematical abilities of LLMs, and even reflect the user experience in real-world scenarios, has emerged as a critical issue. Current benchmarks predominantly concentrate on problem-solving capabilities, which presents a substantial risk of model overfitting and fails to accurately represent genuine mathematical reasoning abilities. In this paper, we argue that if a model really understands a problem, it should be robustly and readily applied across a diverse array of tasks. Motivated by this, we introduce MATHCHECK, a well-designed checklist for testing task generalization and reasoning robustness, as well as an automatic tool to generate checklists efficiently. MATHCHECK includes multiple mathematical reasoning tasks and robustness test types to facilitate a comprehensive evaluation of both mathematical reasoning ability and behavior testing. Utilizing MATHCHECK, we develop MATHCHECK-GSM and MATHCHECK-GEO to assess mathematical textual reasoning and multi-modal reasoning capabilities, respectively, serving as upgraded versions of benchmarks including GSM8k, GeoQA, UniGeo, and Geometry3K. We adopt MATHCHECK-GSM and MATHCHECK-GEO to evaluate over 20 LLMs and 11 MLLMs, assessing their comprehensive mathematical reasoning abilities. Our results demonstrate that while frontier LLMs like GPT-4o continue to excel in various abilities on the checklist, many other model families exhibit a significant decline. Further experiments indicate that, compared to traditional math benchmarks, MATHCHECK better reflects true mathematical abilities and represents mathematical intelligence more linearly, thereby supporting our design. On our MATHCHECK, we can easily conduct detailed behavior analysis to deeply investigate models.
Read more7/12/2024