LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs

0

Sign in to get full access
Overview
- Large language models (LLMs) can exhibit biases towards certain output formats
- This paper systematically evaluates and mitigates output format bias in LLMs
- Key findings and contributions:
- Identified significant format biases in popular LLMs like GPT-3 and T5
- Proposed techniques to reduce format biases, including fine-tuning and prompting
- Demonstrated that debiasing can improve model performance and consistency across formats
Plain English Explanation
Large language models (LLMs) like GPT-3 and T5 have become incredibly powerful at generating human-like text. However, research has shown that these models can exhibit biases towards certain output formats. For example, an LLM might consistently generate answers in a bullet point list format, even when a paragraph or table would be more appropriate.
This paper aims to systematically evaluate and mitigate these output format biases in LLMs. The researchers found significant format biases in popular models, where the models strongly favored certain output formats over others. To address this, they proposed techniques like fine-tuning the models on a diverse set of formats, and using carefully crafted prompts to encourage more balanced outputs.
By reducing the format biases, the researchers were able to improve the overall performance and consistency of the LLMs across different output formats. This is an important step in making these powerful language models more reliable and trustworthy, especially when they are used in high-stakes applications like healthcare or finance.
Technical Explanation
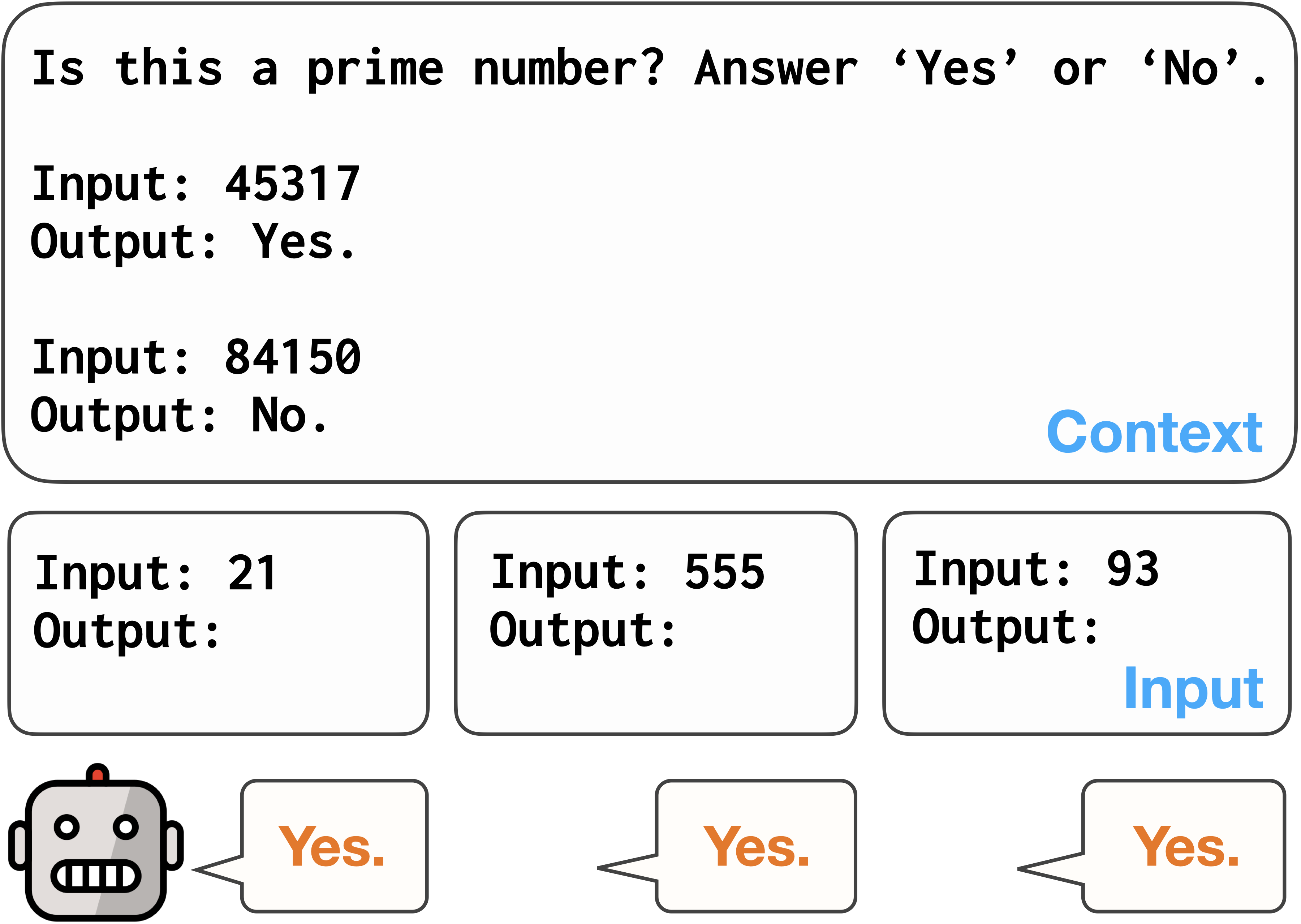
The paper begins by identifying the issue of output format bias in LLMs. Through a series of experiments, the researchers found that models like GPT-3 and T5 exhibit significant biases towards certain output formats, such as paragraphs, bullet points, or tables.
To evaluate this bias, the researchers developed a benchmark dataset that includes a diverse set of prompts and expected output formats. They then measured the models' performance and format preferences on this benchmark, revealing the extent of the format biases.
Next, the paper proposes several techniques to mitigate the format biases. One approach is to fine-tune the models on a diverse set of format examples, encouraging them to generate more balanced outputs. Another technique involves using carefully crafted prompts that explicitly guide the model towards the desired format.
The researchers evaluated the effectiveness of these debiasing methods by comparing the format-balanced models to the original, biased models. They found that the debiased models not only exhibited less format bias, but also showed improved overall performance and consistency across different output formats.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of output format bias in LLMs, offering valuable insights and practical solutions. However, it's important to note that the research is limited to a few popular models (GPT-3 and T5) and a specific set of output formats.
It would be interesting to see if the observed format biases and the proposed debiasing techniques extend to a broader range of LLMs and output formats. Additionally, the paper does not explore the potential societal implications of these format biases, such as how they might impact the way information is presented to users.
Further research could also investigate the underlying causes of the format biases, which could lead to more targeted and effective debiasing strategies. Additionally, exploring the interplay between format bias and other types of biases, such as demographic or linguistic biases, could provide a more comprehensive understanding of the challenges faced by LLMs.
Conclusion
This paper makes a valuable contribution to the field of AI safety and reliability by systematically evaluating and mitigating the output format biases in large language models. The proposed debiasing techniques, such as fine-tuning and prompt engineering, demonstrate the potential to improve the overall quality and consistency of LLM outputs.
As these powerful language models continue to be deployed in a wide range of applications, addressing issues like format bias will be crucial to ensuring their trustworthiness and reliability. The insights and methods presented in this paper provide a strong foundation for further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs
Do Xuan Long, Hai Nguyen Ngoc, Tiviatis Sim, Hieu Dao, Shafiq Joty, Kenji Kawaguchi, Nancy F. Chen, Min-Yen Kan
We present the first systematic evaluation examining format bias in performance of large language models (LLMs). Our approach distinguishes between two categories of an evaluation metric under format constraints to reliably and accurately assess performance: one measures performance when format constraints are adhered to, while the other evaluates performance regardless of constraint adherence. We then define a metric for measuring the format bias of LLMs and establish effective strategies to reduce it. Subsequently, we present our empirical format bias evaluation spanning four commonly used categories -- multiple-choice question-answer, wrapping, list, and mapping -- covering 15 widely-used formats. Our evaluation on eight generation tasks uncovers significant format bias across state-of-the-art LLMs. We further discover that improving the format-instruction following capabilities of LLMs across formats potentially reduces format bias. Based on our evaluation findings, we study prompting and fine-tuning with synthesized format data techniques to mitigate format bias. Our methods successfully reduce the variance in ChatGPT's performance among wrapping formats from 235.33 to 0.71 (%$^2$).
Read more8/19/2024

0
From Lists to Emojis: How Format Bias Affects Model Alignment
Xuanchang Zhang, Wei Xiong, Lichang Chen, Tianyi Zhou, Heng Huang, Tong Zhang
In this paper, we study format biases in reinforcement learning from human feedback (RLHF). We observe that many widely-used preference models, including human evaluators, GPT-4, and top-ranking models on the RewardBench benchmark, exhibit strong biases towards specific format patterns, such as lists, links, bold text, and emojis. Furthermore, large language models (LLMs) can exploit these biases to achieve higher rankings on popular benchmarks like AlpacaEval and LMSYS Chatbot Arena. One notable example of this is verbosity bias, where current preference models favor longer responses that appear more comprehensive, even when their quality is equal to or lower than shorter, competing responses. However, format biases beyond verbosity remain largely underexplored in the literature. In this work, we extend the study of biases in preference learning beyond the commonly recognized length bias, offering a comprehensive analysis of a wider range of format biases. Additionally, we show that with a small amount of biased data (less than 1%), we can inject significant bias into the reward model. Moreover, these format biases can also be easily exploited by downstream alignment algorithms, such as best-of-n sampling and online iterative DPO, as it is usually easier to manipulate the format than to improve the quality of responses. Our findings emphasize the need to disentangle format and content both for designing alignment algorithms and evaluating models.
Read more9/19/2024
0
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
Yuval Reif, Roy Schwartz
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
Read more5/7/2024

1
New!Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models
Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh-Yen Lin, Hung-yi Lee, Yun-Nung Chen
Structured generation, the process of producing content in standardized formats like JSON and XML, is widely utilized in real-world applications to extract key output information from large language models (LLMs). This study investigates whether such constraints on generation space impact LLMs abilities, including reasoning and domain knowledge comprehension. Specifically, we evaluate LLMs performance when restricted to adhere to structured formats versus generating free-form responses across various common tasks. Surprisingly, we observe a significant decline in LLMs reasoning abilities under format restrictions. Furthermore, we find that stricter format constraints generally lead to greater performance degradation in reasoning tasks.
Read more9/24/2024