LMDX: Language Model-based Document Information Extraction and Localization
2309.10952
3
0
💬
Abstract
Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art and exhibiting emergent capabilities across various tasks. However, their application in extracting information from visually rich documents, which is at the core of many document processing workflows and involving the extraction of key entities from semi-structured documents, has not yet been successful. The main obstacles to adopting LLMs for this task include the absence of layout encoding within LLMs, which is critical for high quality extraction, and the lack of a grounding mechanism to localize the predicted entities within the document. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to reframe the document information extraction task for a LLM. LMDX enables extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. Finally, we apply LMDX to the PaLM 2-S and Gemini Pro LLMs and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
Create account to get full access
Overview
- Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) and exhibited impressive capabilities across various tasks.
- However, extracting information from visually rich documents, a core component of many document processing workflows, has been a challenge for LLMs.
- The main obstacles include the lack of layout encoding within LLMs and the lack of a grounding mechanism to localize the predicted entities within the document.
Plain English Explanation
Language Model-based Document Information Extraction and Localization (LMDX) is a new methodology that aims to address these challenges and enable LLMs to effectively extract information from semi-structured documents. The core idea is to reframe the document information extraction task in a way that allows LLMs to leverage their natural language understanding capabilities while also providing the necessary layout encoding and grounding mechanisms.
LMDX enables the extraction of singular, repeated, and hierarchical entities from documents, both with and without training data. It also provides guarantees for the localization of the extracted entities within the document, which is crucial for many document processing workflows. The researchers applied LMDX to two LLMs, PaLM 2-S and Gemini Pro, and evaluated it on benchmark datasets, setting new state-of-the-art performance and demonstrating the potential for creating high-quality, data-efficient parsers using this approach.
Technical Explanation
The paper introduces LMDX, a methodology that reframes the document information extraction task to enable LLMs to effectively extract and localize key entities from semi-structured documents. The core innovation lies in the way LMDX encodes the document layout and provides a grounding mechanism for the predicted entities.
LMDX first encodes the document layout by using a set of special tokens to represent the various visual elements, such as tables, figures, and text blocks. This layout encoding is then seamlessly integrated into the LLM's input, allowing the model to understand the document structure and leverage it for the extraction task.
To provide the necessary grounding, LMDX uses a unique approach where the model is tasked with generating a "location" output alongside the extracted entity. This location output consists of a series of tokens that correspond to the specific visual elements within the document where the entity is located. This grounding mechanism enables the model to not only extract the relevant information but also localize it within the document.
The researchers evaluated LMDX on the VRDU and CORD benchmarks, using the PaLM 2-S and Gemini Pro LLMs. The results demonstrate that LMDX sets new state-of-the-art performance, showcasing its ability to create high-quality, data-efficient parsers for document information extraction tasks.
Critical Analysis
The paper presents a promising approach to addressing the challenges of using LLMs for document information extraction tasks. The LMDX methodology provides a novel way to encode document layout and ground the extracted entities, which are key requirements for successful application in this domain.
However, the paper does not discuss the potential limitations or caveats of the LMDX approach. For example, it would be valuable to understand how LMDX performs on a wider range of document types and layouts, as the evaluation was limited to the specific VRDU and CORD benchmarks. Additionally, the paper does not explore the model's robustness to noise or variations in the input documents, which is an important consideration for real-world deployment.
Further research could also investigate the generalization capabilities of LMDX, such as its ability to handle novel entity types or adapt to different document processing workflows without extensive fine-tuning. Exploring the interpretability and explainability of the LMDX model's decision-making process could also provide valuable insights for users and developers.
Conclusion
The LMDX methodology represents a significant step forward in enabling LLMs to effectively extract information from visually rich documents. By addressing the key limitations of layout encoding and grounding, LMDX has demonstrated its ability to set new state-of-the-art performance on benchmark datasets, paving the way for the development of high-quality, data-efficient parsers for a wide range of document processing applications.
As LLMs continue to evolve and exhibit increasingly sophisticated capabilities, the insights and techniques presented in this paper could have far-reaching implications for the field of Natural Language Processing and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Generative Information Extraction: A Survey
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, Enhong Chen
0
0
Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
6/5/2024
💬
Learning to Extract Structured Entities Using Language Models
Haolun Wu, Ye Yuan, Liana Mikaelyan, Alexander Meulemans, Xue Liu, James Hensman, Bhaskar Mitra
0
0
Recent advances in machine learning have significantly impacted the field of information extraction, with Language Models (LMs) playing a pivotal role in extracting structured information from unstructured text. Prior works typically represent information extraction as triplet-centric and use classical metrics such as precision and recall for evaluation. We reformulate the task to be entity-centric, enabling the use of diverse metrics that can provide more insights from various perspectives. We contribute to the field by introducing Structured Entity Extraction and proposing the Approximate Entity Set OverlaP (AESOP) metric, designed to appropriately assess model performance. Later, we introduce a new model that harnesses the power of LMs for enhanced effectiveness and efficiency by decomposing the extraction task into multiple stages. Quantitative and human side-by-side evaluations confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.
6/21/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024
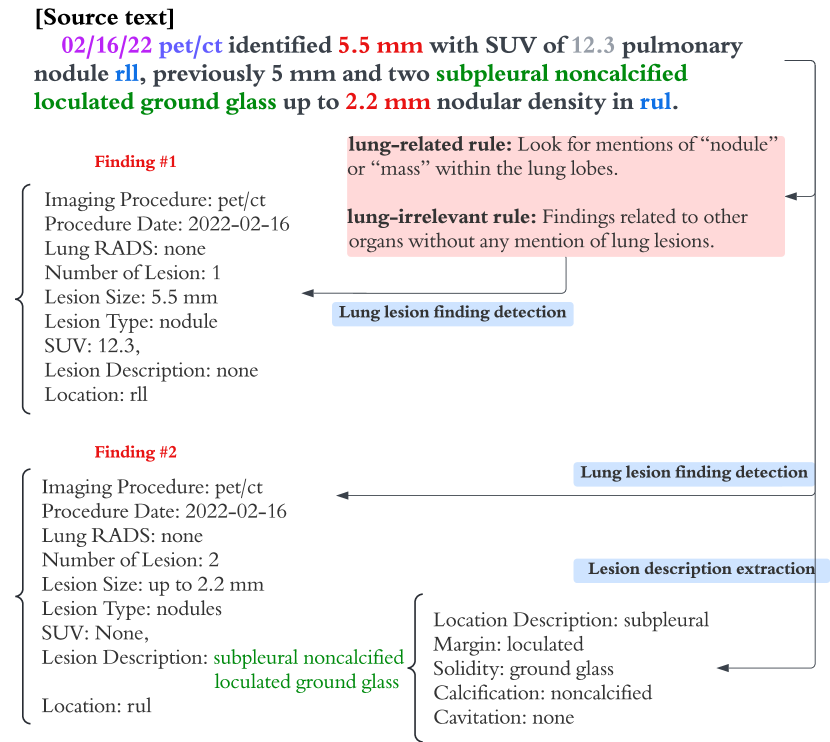
Automated Clinical Data Extraction with Knowledge Conditioned LLMs
Diya Li, Asim Kadav, Aijing Gao, Rui Li, Richard Bourgon
0
0
The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
6/27/2024