Logit Calibration and Feature Contrast for Robust Federated Learning on Non-IID Data

0

Sign in to get full access
Overview
- This paper focuses on improving the robustness of federated learning, a machine learning technique used in distributed computing environments where data is stored on multiple devices.
- The researchers propose two key techniques to address the challenges of non-i.i.d. (non-independently and identically distributed) data in federated learning: logit calibration and feature contrast.
- Logit calibration helps to calibrate the output probabilities of the machine learning model, while feature contrast enhances the model's ability to distinguish between different classes of data.
- The authors evaluate their approach on several benchmark datasets and show that it outperforms existing federated learning methods in terms of accuracy and robustness to data distribution shifts.
Plain English Explanation
Federated learning is a way of training machine learning models without gathering all the data in one place. Instead, the model is trained on devices like phones or computers, and only the model updates are shared with a central server. This is useful when the data is sensitive or spread out, like user data on mobile devices.
One challenge with federated learning is that the data on different devices may not be distributed the same way, which can make it harder for the model to learn. The researchers in this paper propose two techniques to address this:
- Logit Calibration: This helps the model produce more accurate probability estimates for its predictions, even when the data is not evenly distributed.
- Feature Contrast: This teaches the model to focus on the important differences between the classes of data, rather than getting confused by unimportant details.
By using these techniques, the researchers were able to train machine learning models that performed better and were more robust to changes in the data distribution, compared to other federated learning methods. This could be useful for applications like federated Bayesian deep learning or adaptive clustered federated learning on non-i.i.d. data.
Technical Explanation
The paper introduces two key techniques to improve the robustness of federated learning on non-i.i.d. data:
-
Logit Calibration: The researchers noted that standard federated learning approaches often produce uncalibrated output probabilities, meaning the model's confidence in its predictions does not always match the true likelihood of the prediction being correct. To address this, they propose a logit calibration method that adjusts the model's output logits (the raw, pre-softmax scores) to better align with the true class probabilities.
-
Feature Contrast: Another challenge with non-i.i.d. data is that the model may focus on spurious correlations or irrelevant features, rather than learning the truly discriminative features for each class. The researchers introduce a feature contrast loss that encourages the model to learn features that better distinguish between the classes, even when the data distributions differ across clients.
The authors evaluate their approach, called Robust Federated Learning (RobustFL), on several benchmark datasets, including CIFAR-10, CIFAR-100, and Federated EMNIST. They compare RobustFL to other federated learning methods, such as FedAvg and Precision-Guided Approach (PGA), and show that it achieves higher accuracy and better robustness to distribution shifts.
Critical Analysis
The paper presents a well-designed study with thorough experiments and analysis. The researchers have identified an important challenge in federated learning and proposed two effective techniques to address it.
One potential limitation is that the evaluation is mostly limited to image classification tasks, and it would be interesting to see how the proposed methods perform on other types of data and tasks, such as language modeling or speech recognition.
Additionally, the authors do not explore the computational or communication overhead of their techniques, which could be an important consideration in real-world federated learning deployments. Further research could investigate the trade-offs between the performance gains and the additional computational/communication requirements.
Finally, while the paper demonstrates the effectiveness of logit calibration and feature contrast, it would be valuable to gain a deeper understanding of the underlying reasons why these techniques improve robustness. A more detailed analysis of the model's behavior and the learned representations could provide additional insights.
Conclusion
This paper presents an important contribution to the field of federated learning, addressing the challenge of non-i.i.d. data distributions. The proposed techniques of logit calibration and feature contrast effectively improve the accuracy and robustness of federated learning models, as demonstrated on several benchmark datasets.
The findings of this research could have significant implications for the deployment of federated learning in real-world applications, where data may be unevenly distributed across devices. The techniques introduced in this paper could be particularly useful for applications like adaptive clustered federated learning or privacy-preserving federated learning, where dealing with non-i.i.d. data is a crucial challenge.
Overall, this paper advances the state of the art in federated learning and provides a valuable contribution to the ongoing efforts to make machine learning more robust and applicable in distributed computing environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Logit Calibration and Feature Contrast for Robust Federated Learning on Non-IID Data
Yu Qiao, Chaoning Zhang, Apurba Adhikary, Choong Seon Hong
Federated learning (FL) is a privacy-preserving distributed framework for collaborative model training on devices in edge networks. However, challenges arise due to vulnerability to adversarial examples (AEs) and the non-independent and identically distributed (non-IID) nature of data distribution among devices, hindering the deployment of adversarially robust and accurate learning models at the edge. While adversarial training (AT) is commonly acknowledged as an effective defense strategy against adversarial attacks in centralized training, we shed light on the adverse effects of directly applying AT in FL that can severely compromise accuracy, especially in non-IID challenges. Given this limitation, this paper proposes FatCC, which incorporates local logit underline{C}alibration and global feature underline{C}ontrast into the vanilla federated adversarial training (underline{FAT}) process from both logit and feature perspectives. This approach can effectively enhance the federated system's robust accuracy (RA) and clean accuracy (CA). First, we propose logit calibration, where the logits are calibrated during local adversarial updates, thereby improving adversarial robustness. Second, FatCC introduces feature contrast, which involves a global alignment term that aligns each local representation with unbiased global features, thus further enhancing robustness and accuracy in federated adversarial environments. Extensive experiments across multiple datasets demonstrate that FatCC achieves comparable or superior performance gains in both CA and RA compared to other baselines.
Read more4/11/2024
✨
0
FedCCL: Federated Dual-Clustered Feature Contrast Under Domain Heterogeneity
Yu Qiao, Huy Q. Le, Mengchun Zhang, Apurba Adhikary, Chaoning Zhang, Choong Seon Hong
Federated learning (FL) facilitates a privacy-preserving neural network training paradigm through collaboration between edge clients and a central server. One significant challenge is that the distributed data is not independently and identically distributed (non-IID), typically including both intra-domain and inter-domain heterogeneity. However, recent research is limited to simply using averaged signals as a form of regularization and only focusing on one aspect of these non-IID challenges. Given these limitations, this paper clarifies these two non-IID challenges and attempts to introduce cluster representation to address them from both local and global perspectives. Specifically, we propose a dual-clustered feature contrast-based FL framework with dual focuses. First, we employ clustering on the local representations of each client, aiming to capture intra-class information based on these local clusters at a high level of granularity. Then, we facilitate cross-client knowledge sharing by pulling the local representation closer to clusters shared by clients with similar semantics while pushing them away from clusters with dissimilar semantics. Second, since the sizes of local clusters belonging to the same class may differ for each client, we further utilize clustering on the global side and conduct averaging to create a consistent global signal for guiding each local training in a contrastive manner. Experimental results on multiple datasets demonstrate that our proposal achieves comparable or superior performance gain under intra-domain and inter-domain heterogeneity.
Read more9/12/2024
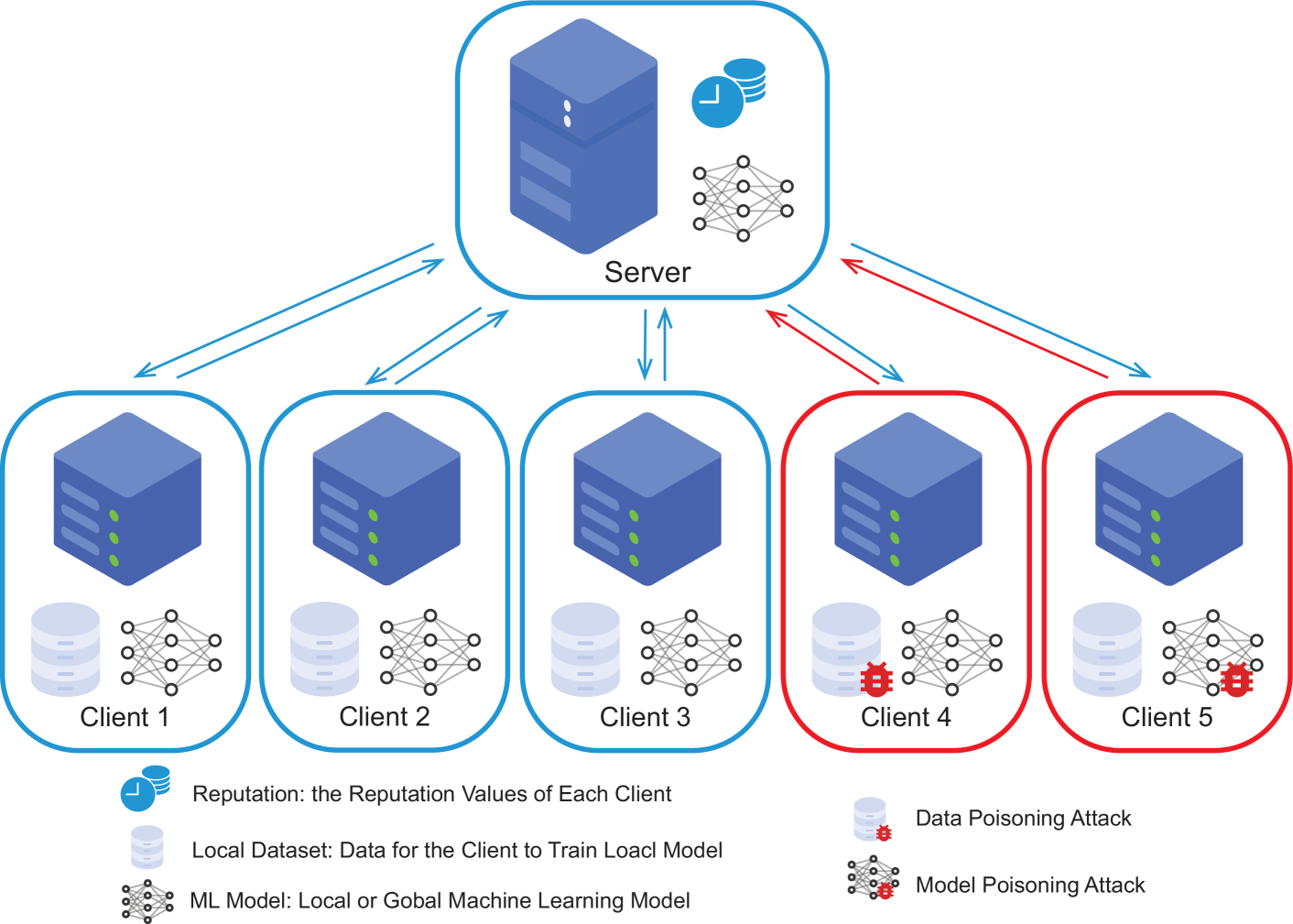
0
Fed-Credit: Robust Federated Learning with Credibility Management
Jiayan Chen, Zhirong Qian, Tianhui Meng, Xitong Gao, Tian Wang, Weijia Jia
Aiming at privacy preservation, Federated Learning (FL) is an emerging machine learning approach enabling model training on decentralized devices or data sources. The learning mechanism of FL relies on aggregating parameter updates from individual clients. However, this process may pose a potential security risk due to the presence of malicious devices. Existing solutions are either costly due to the use of compute-intensive technology, or restrictive for reasons of strong assumptions such as the prior knowledge of the number of attackers and how they attack. Few methods consider both privacy constraints and uncertain attack scenarios. In this paper, we propose a robust FL approach based on the credibility management scheme, called Fed-Credit. Unlike previous studies, our approach does not require prior knowledge of the nodes and the data distribution. It maintains and employs a credibility set, which weighs the historical clients' contributions based on the similarity between the local models and global model, to adjust the global model update. The subtlety of Fed-Credit is that the time decay and attitudinal value factor are incorporated into the dynamic adjustment of the reputation weights and it boasts a computational complexity of O(n) (n is the number of the clients). We conducted extensive experiments on the MNIST and CIFAR-10 datasets under 5 types of attacks. The results exhibit superior accuracy and resilience against adversarial attacks, all while maintaining comparatively low computational complexity. Among these, on the Non-IID CIFAR-10 dataset, our algorithm exhibited performance enhancements of 19.5% and 14.5%, respectively, in comparison to the state-of-the-art algorithm when dealing with two types of data poisoning attacks.
Read more5/21/2024

0
New!FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning
Minxue Tang, Yitu Wang, Jingyang Zhang, Louis DiValentin, Aolin Ding, Amin Hass, Yiran Chen, Hai Helen Li
Federated Learning (FL) provides a strong privacy guarantee by enabling local training across edge devices without training data sharing, and Federated Adversarial Training (FAT) further enhances the robustness against adversarial examples, promoting a step toward trustworthy artificial intelligence. However, FAT requires a large model to preserve high accuracy while achieving strong robustness, and it is impractically slow when directly training with memory-constrained edge devices due to the memory-swapping latency. Moreover, existing memory-efficient FL methods suffer from poor accuracy and weak robustness in FAT because of inconsistent local and global models, i.e., objective inconsistency. In this paper, we propose FedProphet, a novel FAT framework that can achieve memory efficiency, adversarial robustness, and objective consistency simultaneously. FedProphet partitions the large model into small cascaded modules such that the memory-constrained devices can conduct adversarial training module-by-module. A strong convexity regularization is derived to theoretically guarantee the robustness of the whole model, and we show that the strong robustness implies low objective inconsistency in FedProphet. We also develop a training coordinator on the server of FL, with Adaptive Perturbation Adjustment for utility-robustness balance and Differentiated Module Assignment for objective inconsistency mitigation. FedProphet empirically shows a significant improvement in both accuracy and robustness compared to previous memory-efficient methods, achieving almost the same performance of end-to-end FAT with 80% memory reduction and up to 10.8x speedup in training time.
Read more9/16/2024