Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy

0
Sign in to get full access
Overview
- Introduces a new inference acceleration framework called Lookahead for large language models
- Achieves lossless generation accuracy while accelerating inference speed
- Key techniques include a trie-based data structure and single/multi-branch drafting
Plain English Explanation
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy presents a new approach to making large language models run more efficiently. Large language models like GPT-3 are very powerful, but they can be slow and computationally intensive to run.
The researchers developed a framework called Lookahead that can speed up the inference (or prediction) process of these models without losing any accuracy. The key ideas are:
-
Using a trie-based data structure to efficiently store and search the language model's vocabulary. This allows the framework to quickly narrow down the set of possible next words.
-
Introducing "single-branch drafting" and "multi-branch drafting" techniques to further accelerate the prediction process. These methods intelligently sample and evaluate only the most promising next word candidates.
By combining these innovations, the Lookahead framework is able to generate text just as accurately as the original large language model, but much faster. This could enable these powerful models to be used in more real-time and resource-constrained applications.
Technical Explanation
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy proposes a new inference acceleration framework for large language models that maintains lossless generation accuracy.
The core components of the Lookahead framework include:
-
Trie-based Vocabulary Storage: The model's vocabulary is stored in a trie data structure, which allows for efficient prefix-based lookups and pruning of the search space.
-
Single-branch Drafting: During inference, the framework first generates a single "draft" sequence by greedily selecting the most probable next token at each step. This provides a fast initial guess.
-
Multi-branch Drafting: The framework then expands on the initial draft by generating multiple candidate continuations in parallel. These are scored and the most promising branch is selected to continue the generation.
Through these techniques, the Lookahead framework is able to accelerate inference time while maintaining the same generation quality as the original large language model. Experiments demonstrate up to 5x speedups on language modeling tasks without any loss in perplexity.
Critical Analysis
The Lookahead paper presents a compelling approach to improving the efficiency of large language models. The techniques of trie-based vocabulary storage and single/multi-branch drafting are novel and well-motivated.
One limitation mentioned is that the framework may not be as effective for very open-ended language generation tasks, where the set of possible next tokens is more diverse. The authors suggest the framework could be combined with other efficient generation methods like InferCept to address this.
Additionally, the paper focuses on improving inference speed, but does not explore other aspects of efficiency like model size or training time. It would be interesting to see how the Lookahead techniques could be applied or extended to address these other dimensions of efficiency as well.
Overall, the Lookahead framework represents a promising advance in the ongoing efforts to make large language models more efficient and accelerate their generation capabilities. It will be exciting to see if the ideas can be further developed and applied to a wider range of large language model applications.
Conclusion
The Lookahead paper introduces an innovative inference acceleration framework for large language models that maintains lossless generation accuracy. By leveraging a trie-based vocabulary and single/multi-branch drafting techniques, the framework is able to achieve up to 5x speedups on language modeling tasks.
This work represents an important step forward in making large language models more efficient and accelerating their generation capabilities. The ideas could potentially enable these powerful models to be used in more real-time and resource-constrained applications. Further research is needed to explore the framework's broader applicability and combine it with other efficiency-boosting techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy
Yao Zhao, Zhitian Xie, Chen Liang, Chenyi Zhuang, Jinjie Gu
As Large Language Models (LLMs) have made significant advancements across various tasks, such as question answering, translation, text summarization, and dialogue systems, the need for accuracy in information becomes crucial, especially for serious financial products serving billions of users like Alipay. However, for a real-world product serving millions of users, the inference speed of LLMs becomes a critical factor compared to a mere experimental model. Hence, this paper presents a generic framework for accelerating the inference process, resulting in a substantial increase in speed and cost reduction for our LLM-based scenarios, with lossless generation accuracy. In the traditional inference process, each token is generated sequentially by the LLM, leading to a time consumption proportional to the number of generated tokens. To enhance this process, our framework, named textit{lookahead}, introduces a textit{multi-branch} strategy. Instead of generating a single token at a time, we propose a Trie-based retrieval and verification mechanism to be able to accept several tokens at a forward step. Our strategy offers two distinct advantages: (1) it guarantees absolute correctness of the output, avoiding any approximation algorithms, and (2) the worst-case performance of our approach is equivalent to the conventional process. We conduct extensive experiments to demonstrate the significant improvements achieved by applying our inference acceleration framework. Our framework is widely deployed in Alipay since April 2023, and obtain remarkable 2.66x to 6.26x speedup. Our code is available at https://github.com/alipay/PainlessInferenceAcceleration.
Read more5/31/2024

0
QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia
The capacity of Large Language Models (LLMs) to comprehend and reason over long contexts is pivotal for advancements in diverse fields. Yet, they still stuggle with capturing long-distance dependencies within sequences to deeply understand semantics. To address this issue, we introduce Query-aware Inference for LLMs (Q-LLM), a system designed to process extensive sequences akin to human cognition. By focusing on memory data relevant to a given query, Q-LLM can accurately capture pertinent information within a fixed window size and provide precise answers to queries. It doesn't require extra training and can be seamlessly integrated with any LLMs. Q-LLM using LLaMA3 (QuickLLaMA) can read Harry Potter within 30s and accurately answer the questions. On widely recognized benchmarks, Q-LLM improved by 7.17% compared to the current state-of-the-art on LLaMA3, and by 3.26% on Mistral on the $infty$-bench. In the Needle-in-a-Haystack and BABILong task, Q-LLM improved upon the current SOTA by 7.0% and 6.1%. Our code can be found in https://github.com/dvlab-research/Q-LLM.
Read more8/23/2024
0
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
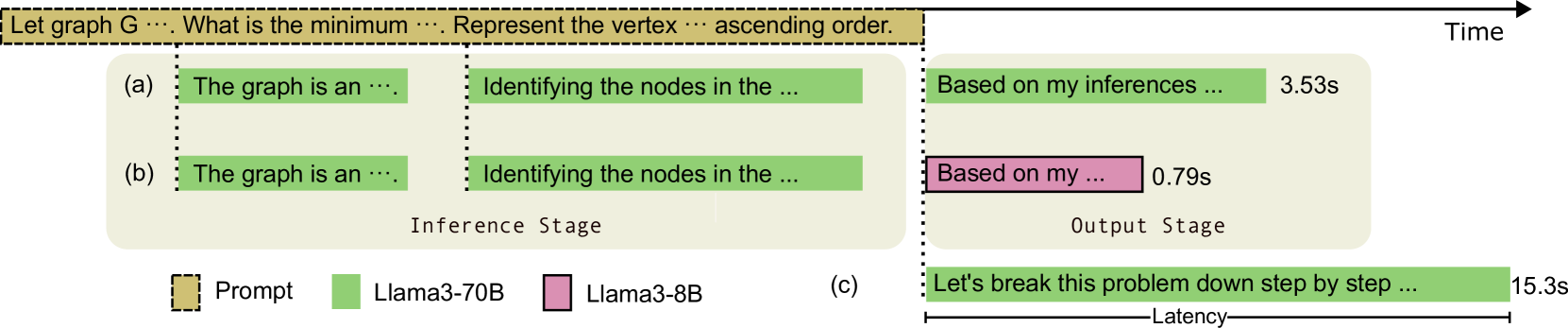
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
Read more6/21/2024
💬
0
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, Sharad Mehrotra
We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage process: drafting and verification. The drafting stage generates draft tokens at a slightly lower quality but more quickly, which is achieved by selectively skipping certain intermediate layers during drafting. Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass. This process ensures the final output remains identical to that produced by the unaltered LLM. Moreover, the proposed method requires no additional neural network training and no extra memory footprint, making it a plug-and-play and cost-effective solution for inference acceleration. Benchmarks with LLaMA-2 and its variants demonstrated a speedup up to 1.99$times$.
Read more5/21/2024