FFN-SkipLLM: A Hidden Gem for Autoregressive Decoding with Adaptive Feed Forward Skipping
2404.03865
0
0

Abstract
Autoregressive Large Language Models (e.g., LLaMa, GPTs) are omnipresent achieving remarkable success in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges for autoregressive token-by-token generation. To mitigate computation overload incurred during generation, several early-exit and layer-dropping strategies have been proposed. Despite some promising success due to the redundancy across LLMs layers on metrics like Rough-L/BLUE, our careful knowledge-intensive evaluation unveils issues such as generation collapse, hallucination of wrong facts, and noticeable performance drop even at the trivial exit ratio of 10-15% of layers. We attribute these errors primarily to ineffective handling of the KV cache through state copying during early-exit. In this work, we observed the saturation of computationally expensive feed-forward blocks of LLM layers and proposed FFN-SkipLLM, which is a novel fine-grained skip strategy of autoregressive LLMs. More specifically, FFN-SkipLLM is an input-adaptive feed-forward skipping strategy that can skip 25-30% of FFN blocks of LLMs with marginal change in performance on knowledge-intensive generation tasks without any requirement to handle KV cache. Our extensive experiments and ablation across benchmarks like MT-Bench, Factoid-QA, and variable-length text summarization illustrate how our simple and ease-at-use method can facilitate faster autoregressive decoding.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel language model architecture called FFN-SkipLLM (Feed-Forward Network Skipping Large Language Model) that adaptively skips feed-forward network layers during autoregressive decoding for improved efficiency.
- The authors conduct a "knowledge-intensive" evaluation to assess the layer-skipping behavior of FFN-SkipLLM and compare it to other approaches.
- They find that FFN-SkipLLM can achieve significant speedups without sacrificing performance on a range of tasks, making it a promising candidate for deploying large language models on resource-constrained edge devices.
Plain English Explanation
The paper introduces a new type of large language model called FFN-SkipLLM that is designed to be more efficient during the decoding process. Large language models like GPT-3 are powerful but can be computationally expensive to run, especially on devices with limited resources like phones or smart speakers.
The key innovation in FFN-SkipLLM is an "adaptive layer-skipping" mechanism. This means the model can dynamically decide which internal layers it needs to compute during decoding, skipping over some layers entirely when they are not necessary. This allows the model to run faster without sacrificing too much accuracy.
The authors test FFN-SkipLLM extensively and compare it to other efficient language model approaches. They find that it can achieve significant speedups, sometimes running 2-3 times faster than a standard large language model, while maintaining strong performance on a variety of language tasks. This makes FFN-SkipLLM a promising option for deploying powerful language AI on resource-constrained edge devices like smartphones or smart home assistants.
Technical Explanation
The core of the FFN-SkipLLM architecture is an adaptive feed-forward network (FFN) layer-skipping mechanism that allows the model to dynamically decide which internal layers to compute during autoregressive decoding. This is in contrast to prior work that used fixed or coarse-grained layer-skipping.
The authors conduct a "knowledge-intensive" evaluation to assess the layer-skipping behavior of FFN-SkipLLM. This involves probing the model's internal representations to understand which types of inputs trigger more or less layer-skipping. They find that FFN-SkipLLM is able to effectively adapt its computation to the input, skipping more layers for simpler or more repetitive inputs while computing more layers for more complex or ambiguous inputs.
Experiments show that FFN-SkipLLM can achieve significant speedups of 2-3x on autoregressive decoding tasks compared to a standard Transformer-based language model, while maintaining similar or better performance. This makes it a promising candidate for deploying powerful language AI on resource-constrained edge devices.
Critical Analysis
The authors acknowledge that the layer-skipping mechanism in FFN-SkipLLM introduces some additional complexity and overhead compared to a standard Transformer. There may be cases where this overhead offsets the benefits of skipping layers, limiting the speedups that can be achieved.
Additionally, the knowledge-intensive evaluation provides useful insights, but it is unclear how well the layer-skipping behavior will generalize to real-world applications beyond the specific test scenarios. Further research is needed to understand the robustness and limitations of the approach.
That said, the core idea of adaptive layer-skipping is compelling and the empirical results demonstrating significant speed improvements without major accuracy degradation are quite promising. With further refinement and validation, FFN-SkipLLM could be a valuable tool for deploying large language models on resource-constrained edge devices.
Conclusion
The FFN-SkipLLM model proposed in this paper represents an interesting advance in making large language models more efficient for autoregressive decoding. By incorporating an adaptive layer-skipping mechanism, the model is able to achieve significant speed improvements without sacrificing too much accuracy.
This could be an important step towards enabling powerful language AI to run on resource-constrained edge devices like smartphones and smart home assistants. With further research to address the remaining challenges, FFN-SkipLLM and similar approaches could help bring the benefits of large language models to a wider range of real-world applications.
Related Papers
🤯
Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed A Aly, Beidi Chen, Carole-Jean Wu
0
0
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
4/30/2024
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Pengfei Wu, Jiahao Liu, Zhuocheng Gong, Qifan Wang, Jinpeng Li, Jingang Wang, Xunliang Cai, Dongyan Zhao
0
0
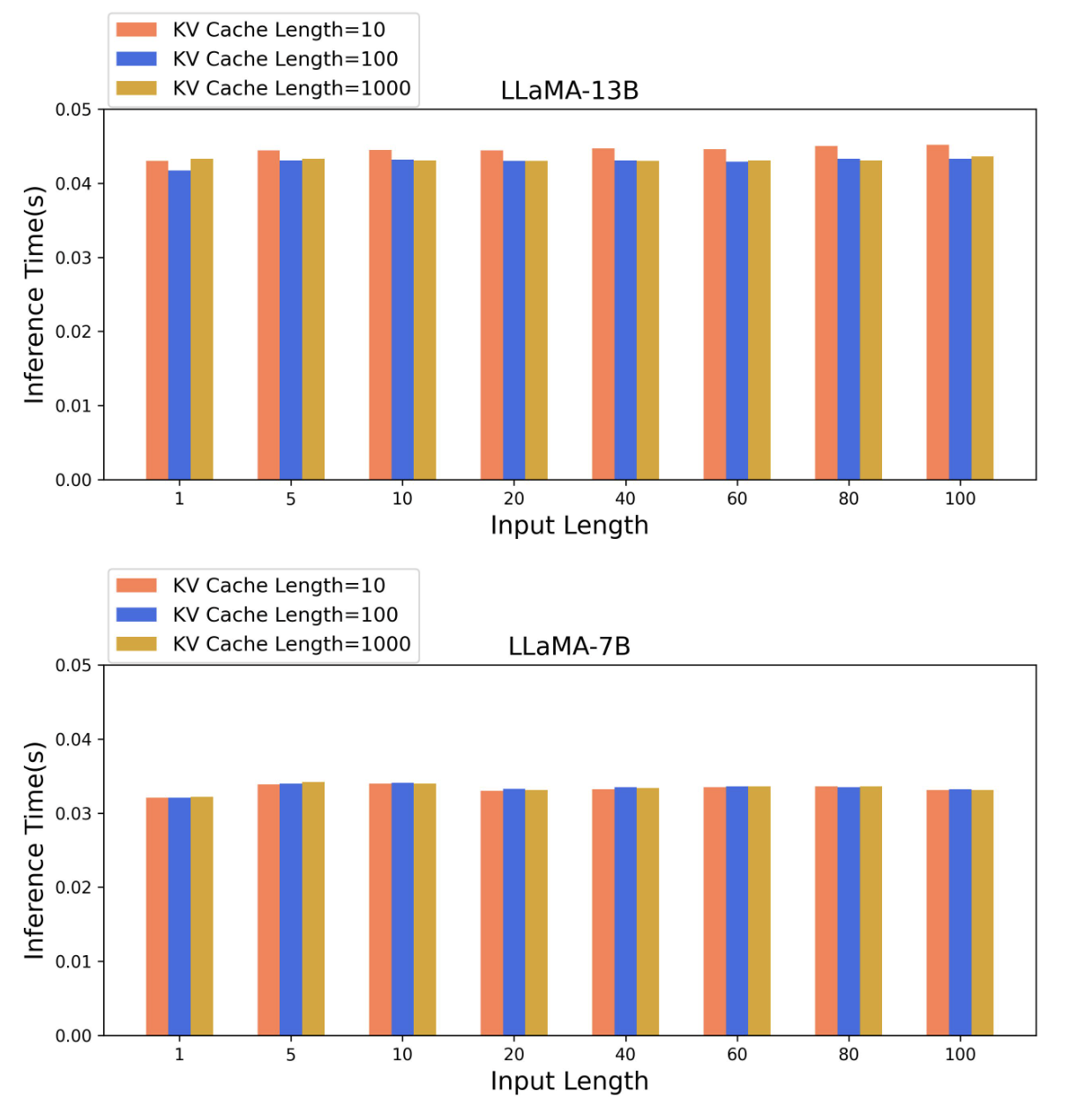
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
4/19/2024
Accelerating Inference in Large Language Models with a Unified Layer Skipping Strategy
Yijin Liu, Fandong Meng, Jie Zhou
0
0
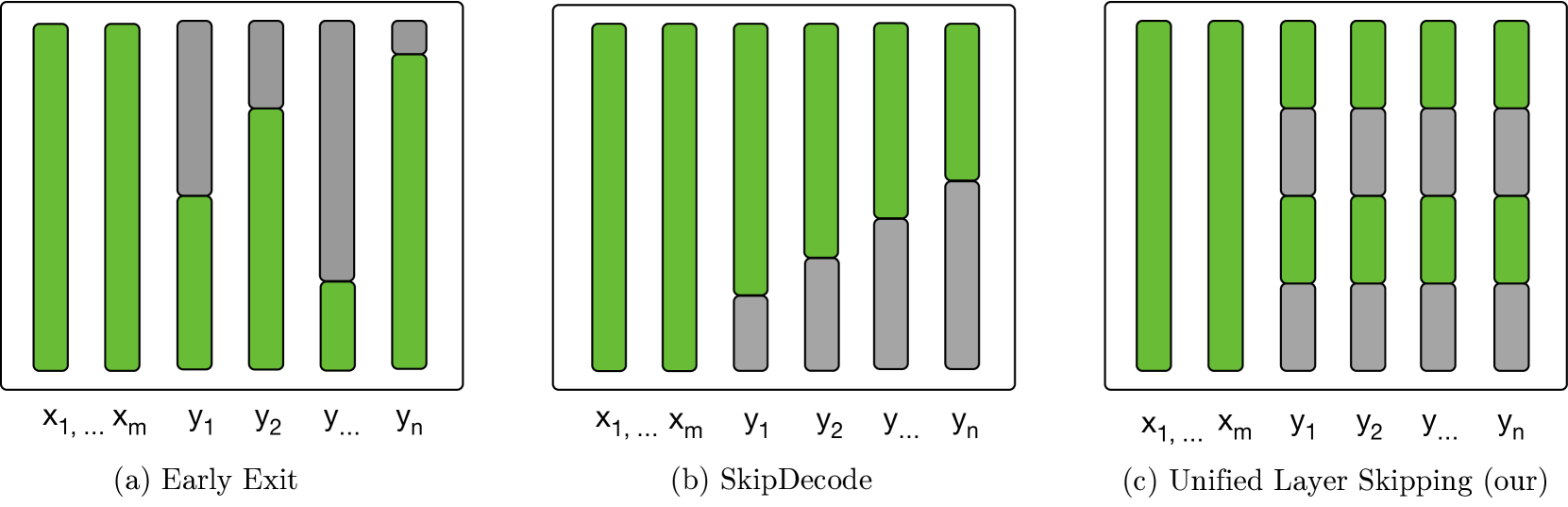
Recently, dynamic computation methods have shown notable acceleration for Large Language Models (LLMs) by skipping several layers of computations through elaborate heuristics or additional predictors. However, in the decoding process of existing approaches, different samples are assigned different computational budgets, which cannot guarantee a stable and precise acceleration effect. Furthermore, existing approaches generally skip multiple contiguous layers at the bottom or top of the layers, leading to a drastic change in the model's layer-wise representations, and thus a consequent performance degeneration. Therefore, we propose a Unified Layer Skipping strategy, which selects the number of layers to skip computation based solely on the target speedup ratio, and then skips the corresponding number of intermediate layer computations in a balanced manner. Since the Unified Layer Skipping strategy is independent of input samples, it naturally supports popular acceleration techniques such as batch decoding and KV caching, thus demonstrating more practicality for real-world applications. Experimental results on two common tasks, i.e., machine translation and text summarization, indicate that given a target speedup ratio, the Unified Layer Skipping strategy significantly enhances both the inference performance and the actual model throughput over existing dynamic approaches.
4/11/2024
Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding
Jie Ou, Yueming Chen, Wenhong Tian
0
0
While Large Language Models (LLMs) have shown remarkable abilities, they are hindered by significant resource consumption and considerable latency due to autoregressive processing. In this study, we introduce Adaptive N-gram Parallel Decoding (ANPD), an innovative and lossless approach that accelerates inference by allowing the simultaneous generation of multiple tokens. ANPD incorporates a two-stage approach: it begins with a rapid drafting phase that employs an N-gram module, which adapts based on the current interactive context, followed by a verification phase, during which the original LLM assesses and confirms the proposed tokens. Consequently, ANPD preserves the integrity of the LLM's original output while enhancing processing speed. We further leverage a multi-level architecture for the N-gram module to enhance the precision of the initial draft, consequently reducing inference latency. ANPD eliminates the need for retraining or extra GPU memory, making it an efficient and plug-and-play enhancement. In our experiments, models such as LLaMA and its fine-tuned variants have shown speed improvements up to 3.67x, validating the effectiveness of our proposed ANPD.
4/16/2024