LRM-Zero: Training Large Reconstruction Models with Synthesized Data

0
Sign in to get full access
Overview
- This paper presents a new approach called "LRM-Zero" for training large reconstruction models using synthesized data.
- The key idea is to generate realistic synthetic data that can be used to pre-train a large reconstruction model, which is then fine-tuned on real data.
- This allows the model to learn useful features and capabilities from the synthetic data, before specializing on the target real-world domain.
- The authors demonstrate that this approach can outperform models trained solely on real data, across a range of 3D reconstruction benchmarks.
Plain English Explanation
The paper introduces a new way to train large 3D reconstruction models, which are AI systems that can take 2D images or other inputs and create 3D models of the objects or scenes they depict.
The core insight is that it's often challenging to obtain large, high-quality datasets of 3D data to train these models on. So the researchers developed a method to generate synthetic 3D data that looks and behaves realistically. They then use this synthetic data to pre-train the reconstruction model, before fine-tuning it on smaller real-world datasets.
The key benefit is that the model can learn a lot of useful low-level features and capabilities from the synthetic data, which then gives it a head start when learning from the real data. This allows the model to achieve better performance than if it was trained solely on the limited real-world data.
The authors demonstrate this approach, called "LRM-Zero", on several standard 3D reconstruction benchmarks. They show that it outperforms models trained in the traditional way, highlighting the power of combining synthetic and real data for training large, high-performance 3D reconstruction systems.
Technical Explanation
The paper presents a new technique called "LRM-Zero" for training large reconstruction models, building on prior work like REAL3D, MeshLRM, GS-LRM, M-LRM, and GTR.
The key idea is to pre-train the reconstruction model on synthetic 3D data, which can be generated in large quantities, before fine-tuning it on smaller datasets of real-world 3D data. This allows the model to learn useful features and capabilities from the synthetic data that then give it a head start when learning from the real-world examples.
The authors evaluate this approach on several 3D reconstruction benchmarks, and show that it can outperform models trained solely on real data. They attribute this to the model's ability to learn robust low-level features from the synthetic data that generalize well to real-world scenarios.
Critical Analysis
The paper presents a compelling approach for leveraging synthetic data to improve the performance of large 3D reconstruction models. However, there are a few potential caveats and areas for further research:
-
Fidelity of Synthetic Data: The quality and realism of the generated synthetic data is critical to the success of this approach. The authors do not provide extensive details on their data generation process, so it's unclear how well the synthetic data matches real-world characteristics.
-
Generalization to Diverse Domains: The experiments focus on a limited set of 3D reconstruction benchmarks. It's unclear how well the LRM-Zero approach would generalize to significantly different domains or data distributions.
-
Computational and Memory Efficiency: Training large reconstruction models, even with synthetic data, can be computationally and memory intensive. The paper does not address the resource requirements or scalability of this approach.
-
Real-World Deployment Challenges: While the results are promising in controlled benchmark settings, deploying these large reconstruction models in real-world applications may introduce additional challenges, such as inference speed, robustness to noise or occlusions, and interpretability.
Overall, the LRM-Zero approach represents an interesting and potentially impactful contribution to the field of 3D reconstruction. However, further research is needed to address the limitations and fully understand the broader applicability of this technique.
Conclusion
The LRM-Zero paper presents a novel approach for training large 3D reconstruction models by leveraging synthetic data. By pre-training the model on realistic synthetic data before fine-tuning on real-world examples, the authors demonstrate improved performance across several benchmark tasks.
This work highlights the potential of combining synthetic and real data for training high-capacity machine learning models, particularly in domains where real-world data is scarce or difficult to obtain. If the synthetic data can be generated with sufficient fidelity, this approach could unlock new capabilities for 3D reconstruction and other computer vision applications.
While the paper outlines promising results, there are still open questions and areas for further research, such as the generalizability of the approach, the computational efficiency, and the challenges of real-world deployment. Nonetheless, the LRM-Zero method represents an important step forward in the development of large-scale 3D reconstruction models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LRM-Zero: Training Large Reconstruction Models with Synthesized Data
Desai Xie, Sai Bi, Zhixin Shu, Kai Zhang, Zexiang Xu, Yi Zhou, Soren Pirk, Arie Kaufman, Xin Sun, Hao Tan
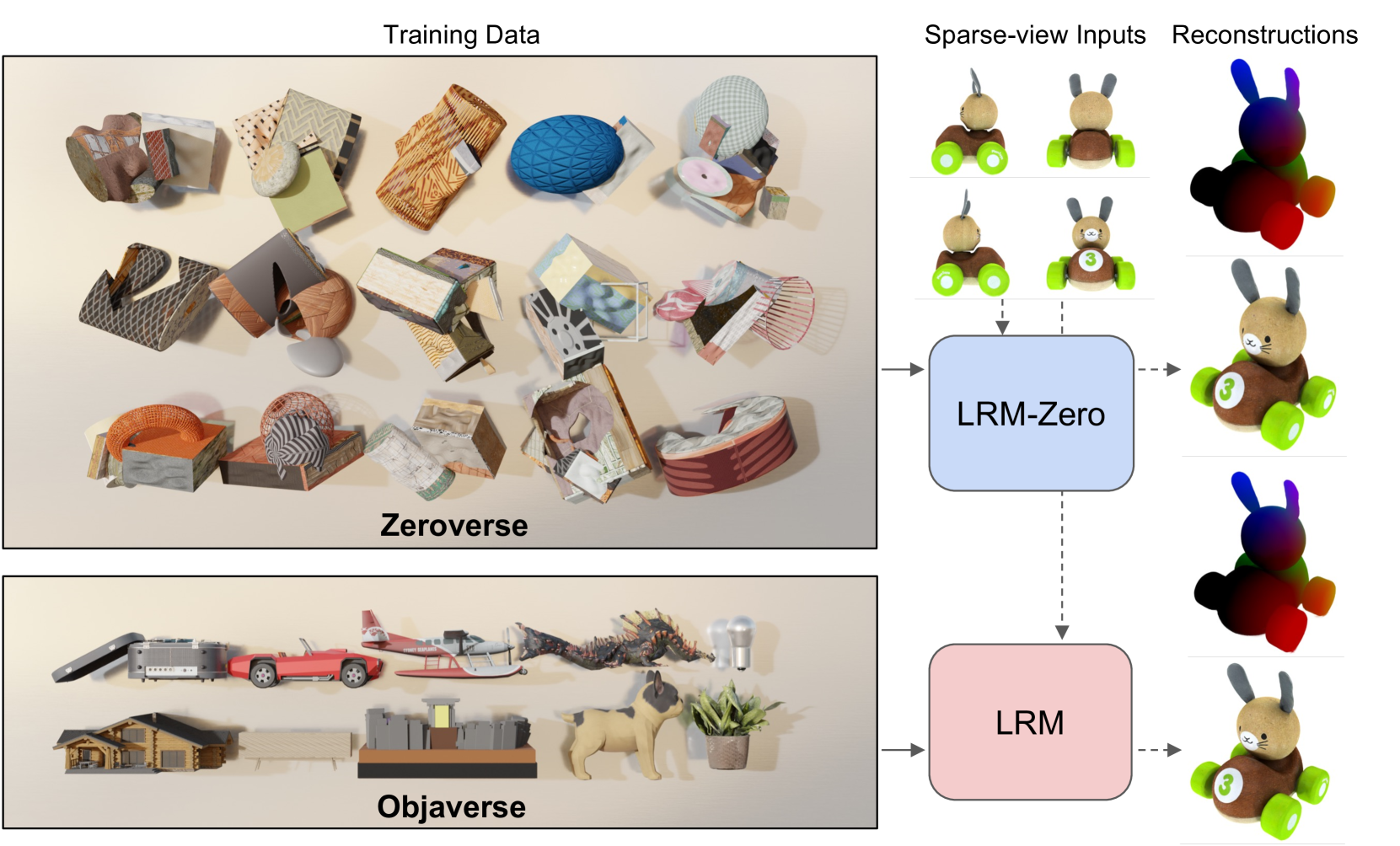
We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: https://desaixie.github.io/lrm-zero/.
Read more6/14/2024
🛠️
0
Real3D: Scaling Up Large Reconstruction Models with Real-World Images
Hanwen Jiang, Qixing Huang, Georgios Pavlakos
The default strategy for training single-view Large Reconstruction Models (LRMs) follows the fully supervised route using large-scale datasets of synthetic 3D assets or multi-view captures. Although these resources simplify the training procedure, they are hard to scale up beyond the existing datasets and they are not necessarily representative of the real distribution of object shapes. To address these limitations, in this paper, we introduce Real3D, the first LRM system that can be trained using single-view real-world images. Real3D introduces a novel self-training framework that can benefit from both the existing synthetic data and diverse single-view real images. We propose two unsupervised losses that allow us to supervise LRMs at the pixel- and semantic-level, even for training examples without ground-truth 3D or novel views. To further improve performance and scale up the image data, we develop an automatic data curation approach to collect high-quality examples from in-the-wild images. Our experiments show that Real3D consistently outperforms prior work in four diverse evaluation settings that include real and synthetic data, as well as both in-domain and out-of-domain shapes. Code and model can be found here: https://hwjiang1510.github.io/Real3D/
Read more6/13/2024
📈
0
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, Zexiang Xu
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
Read more4/19/2024
📈
0
GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
Read more5/1/2024