LTL-Constrained Policy Optimization with Cycle Experience Replay

0

Sign in to get full access
Overview
- This paper introduces a new approach for deep reinforcement learning that incorporates temporal logic constraints to guide the policy optimization process.
- The method, called Deep Policy Optimization with Temporal Logic Constraints (DPOTLC), allows the user to specify high-level goals and constraints using temporal logic, which are then used to shape the policy during training.
- The authors demonstrate the effectiveness of DPOTLC on several benchmark tasks, showing that it can lead to policies that satisfy the given temporal logic specifications while also optimizing for task performance.
Plain English Explanation
The paper presents a new way to train reinforcement learning agents that can follow high-level rules or constraints during their decision-making. In a typical reinforcement learning setup, an agent learns to take actions that maximize some reward signal, without any explicit guidance on the types of behavior that are desired.
However, in many real-world applications, we may want the agent to obey certain rules or specifications, like "always check for obstacles before moving" or "complete task A before starting task B." The DPOTLC method allows the user to encode these types of temporal logic constraints, which are then incorporated into the policy optimization process.
By optimizing the policy to both maximize reward and satisfy the temporal logic constraints, the agent can learn behaviors that balance task performance with adherence to the specified rules. This could be particularly useful in safety-critical domains, where it's important for the agent to behave in ways that are provably safe and reliable.
The authors demonstrate the DPOTLC approach on several benchmark tasks and show that it can lead to policies that satisfy the given temporal logic specifications while also achieving good task performance. This suggests that the method could be a valuable tool for building reinforcement learning agents that can operate reliably and predictably in complex, real-world environments.
Technical Explanation
The DPOTLC method builds on previous work on deterministic policies for constrained reinforcement learning in polynomial time and satisfying temporally extended symbolic constraints safely. The key idea is to augment the standard reinforcement learning objective with an additional term that encourages the policy to satisfy the given temporal logic constraints.
Specifically, the authors use Linear Temporal Logic (LTL) to specify the desired constraints, which allows for the expression of complex temporal relationships between states and actions. They then derive a differentiable reward signal from the LTL formula, which can be optimized alongside the standard task reward during policy training.
The authors also introduce a novel experience replay approach, called CIER, that helps the agent learn more efficiently by prioritizing experiences that are relevant to satisfying the temporal logic constraints.
The effectiveness of DPOTLC is demonstrated on several benchmark tasks, including logical specifications guided dynamic task sampling and stable inverse reinforcement learning. The results show that the approach can lead to policies that satisfy the given temporal logic constraints while also optimizing for task performance.
Critical Analysis
The DPOTLC method represents an important step forward in the field of reinforcement learning, as it provides a principled way to incorporate high-level rules and specifications into the policy optimization process. This could be particularly valuable in safety-critical domains, where it's essential for the agent to behave in a reliable and predictable manner.
However, the authors acknowledge that the approach has some limitations. For example, the reliance on Linear Temporal Logic may limit the expressiveness of the constraints that can be specified, and the differentiable reward signal derived from the LTL formula may not always provide a perfect proxy for the desired behavior.
Additionally, the authors note that the CIER experience replay method, while effective, may introduce some bias into the learning process. It's an open question how this bias might affect the agent's ability to generalize to new situations or handle unexpected events.
Further research may also be needed to understand the scalability of the DPOTLC method to more complex tasks and environments, as well as to explore alternative ways of incorporating temporal logic constraints into the policy optimization process.
Conclusion
The DPOTLC method represents an important advance in the field of reinforcement learning, as it provides a way to explicitly incorporate high-level rules and specifications into the policy optimization process. By allowing the user to specify temporal logic constraints, the method can help train agents that balance task performance with adherence to desired behaviors, which could be particularly valuable in safety-critical domains.
While the approach has some limitations, the authors' results suggest that it can be an effective tool for building reliable and predictable reinforcement learning agents. As the field of AI continues to evolve, methods like DPOTLC will likely play an increasingly important role in ensuring that these systems can be deployed safely and responsibly in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LTL-Constrained Policy Optimization with Cycle Experience Replay
Ameesh Shah, Cameron Voloshin, Chenxi Yang, Abhinav Verma, Swarat Chaudhuri, Sanjit A. Seshia
Linear Temporal Logic (LTL) offers a precise means for constraining the behavior of reinforcement learning agents. However, in many tasks, LTL is insufficient for task specification; LTL-constrained policy optimization, where the goal is to optimize a scalar reward under LTL constraints, is needed. Prior methods for this constrained problem are restricted to finite state spaces. In this work, we present Cycle Experience Replay (CyclER), a reward-shaping approach to this problem that allows continuous state and action spaces and the use of function approximations. CyclER guides a policy towards satisfaction by encouraging partial behaviors compliant with the LTL constraint, using the structure of the constraint. In doing so, it addresses the optimization challenges stemming from the sparse nature of LTL satisfaction. We evaluate CyclER in three continuous control domains. On these tasks, CyclER outperforms existing reward-shaping methods at finding performant and LTL-satisfying policies.
Read more5/28/2024
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
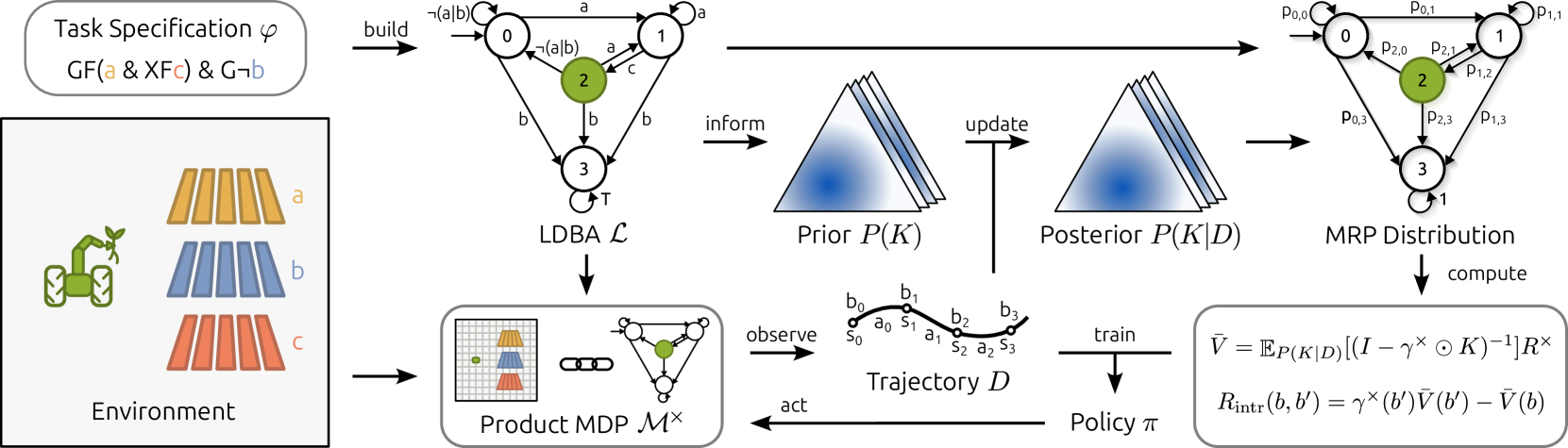
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024
0
Convergence Guarantee of Dynamic Programming for LTL Surrogate Reward
Zetong Xuan, Yu Wang
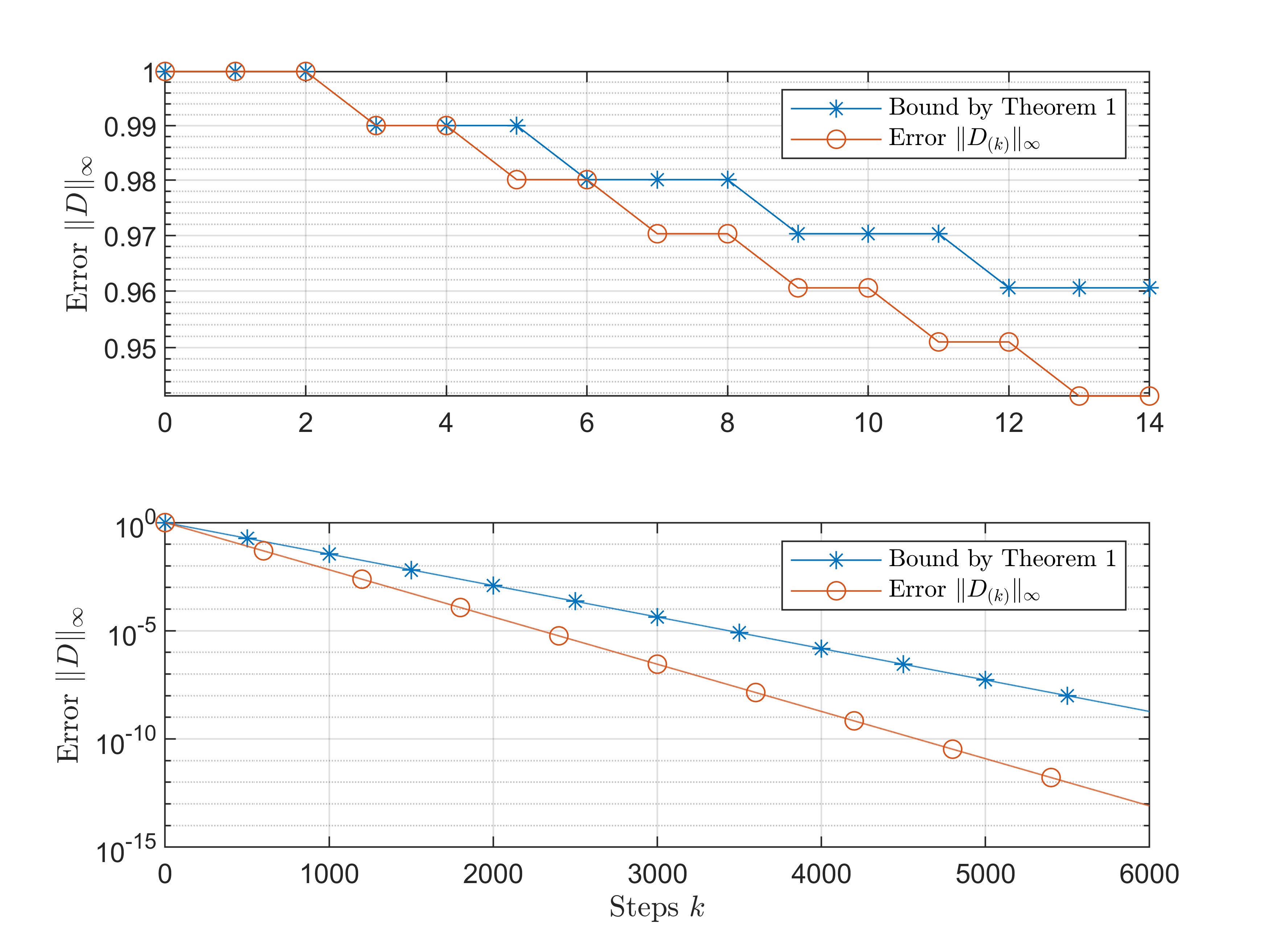
Linear Temporal Logic (LTL) is a formal way of specifying complex objectives for planning problems modeled as Markov Decision Processes (MDPs). The planning problem aims to find the optimal policy that maximizes the satisfaction probability of the LTL objective. One way to solve the planning problem is to use the surrogate reward with two discount factors and dynamic programming, which bypasses the graph analysis used in traditional model-checking. The surrogate reward is designed such that its value function represents the satisfaction probability. However, in some cases where one of the discount factors is set to $1$ for higher accuracy, the computation of the value function using dynamic programming is not guaranteed. This work shows that a multi-step contraction always exists during dynamic programming updates, guaranteeing that the approximate value function will converge exponentially to the true value function. Thus, the computation of satisfaction probability is guaranteed.
Read more8/13/2024

0
A Tighter Convergence Proof of Reverse Experience Replay
Nan Jiang, Jinzhao Li, Yexiang Xue
In reinforcement learning, Reverse Experience Replay (RER) is a recently proposed algorithm that attains better sample complexity than the classic experience replay method. RER requires the learning algorithm to update the parameters through consecutive state-action-reward tuples in reverse order. However, the most recent theoretical analysis only holds for a minimal learning rate and short consecutive steps, which converge slower than those large learning rate algorithms without RER. In view of this theoretical and empirical gap, we provide a tighter analysis that mitigates the limitation on the learning rate and the length of consecutive steps. Furthermore, we show theoretically that RER converges with a larger learning rate and a longer sequence.
Read more9/2/2024