Machine Translation with Large Language Models: Decoder Only vs. Encoder-Decoder

0

Sign in to get full access
Overview
- This paper compares the performance of decoder-only and encoder-decoder models for machine translation using large language models.
- Decoder-only models like GPT-3 are trained on text generation tasks, while encoder-decoder models like Transformer are designed for specific tasks like translation.
- The researchers investigate the strengths and limitations of each approach for machine translation.
Plain English Explanation
The paper examines two different types of large language models and how well they perform on the task of machine translation. Decoder-only models like GPT-3 are trained more generally to generate text, while encoder-decoder models like Transformer are designed specifically for translation between languages.
The researchers wanted to understand the pros and cons of each approach for machine translation. Decoder-only models may have an advantage in flexibility and ability to handle a wide range of language tasks. But encoder-decoder models may be more tailored and effective for the specific translation task. The paper explores the trade-offs and compares the actual performance of these two model types on machine translation benchmarks.
Technical Explanation
The paper investigates the performance of decoder-only language models versus encoder-decoder models for machine translation tasks. Decoder-only models like GPT-3 are trained on general language modeling, while encoder-decoder models like Transformer are designed specifically for translation.
The researchers evaluate both model types on standard machine translation benchmarks. They analyze factors like translation quality, computational efficiency, and ability to handle different language pairs. The results show that decoder-only models can achieve competitive translation performance, but encoder-decoder models still have advantages in certain areas like handling long-range dependencies and more precise translation.
The paper provides insights into the strengths and limitations of these two broad approaches to using large language models for machine translation. It highlights the tradeoffs that must be considered when choosing the appropriate model architecture for a given translation task.
Critical Analysis
The paper offers a balanced and thorough comparison of decoder-only and encoder-decoder models for machine translation. It acknowledges the potential benefits of decoder-only models in terms of flexibility and generalization, while also highlighting the specific advantages of encoder-decoder architectures for the translation task.
One potential limitation is that the analysis is primarily focused on standard benchmarks and does not explore real-world translation use cases in depth. The researchers note that future work could investigate performance on more diverse data sources and application-specific requirements.
Additionally, the paper does not delve deeply into the underlying reasons for the observed performance differences between the two model types. Further research could shed light on the precise architectural and training factors that contribute to the strengths and weaknesses of each approach.
Overall, the paper provides a valuable contribution to understanding the trade-offs involved in leveraging large language models for machine translation. It encourages readers to think critically about model selection and the nuances of applying these powerful AI systems to real-world translation challenges.
Conclusion
This paper offers a comparative analysis of decoder-only and encoder-decoder large language models for the task of machine translation. It examines the relative strengths and limitations of each approach, finding that while decoder-only models can achieve competitive translation performance, encoder-decoder architectures still hold advantages in areas like handling long-range dependencies and producing more precise translations.
The insights from this research can help guide the selection of appropriate language models for different machine translation applications and inspire further work to better understand the fundamental factors driving the performance differences between these two broad model types. As large language models continue to advance, studies like this one will be crucial for unlocking their full potential for high-quality, flexible machine translation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Machine Translation with Large Language Models: Decoder Only vs. Encoder-Decoder
Abhinav P. M., SujayKumar Reddy M, Oswald Christopher
This project, titled Machine Translation with Large Language Models: Decoder-only vs. Encoder-Decoder, aims to develop a multilingual machine translation (MT) model. Focused on Indian regional languages, especially Telugu, Tamil, and Malayalam, the model seeks to enable accurate and contextually appropriate translations across diverse language pairs. By comparing Decoder-only and Encoder-Decoder architectures, the project aims to optimize translation quality and efficiency, advancing cross-linguistic communication tools.The primary objective is to develop a model capable of delivering high-quality translations that are accurate and contextually appropriate. By leveraging large language models, specifically comparing the effectiveness of Decoder-only and Encoder-Decoder architectures, the project seeks to optimize translation performance and efficiency across multilingual contexts. Through rigorous experimentation and analysis, this project aims to advance the field of machine translation, contributing valuable insights into the effectiveness of different model architectures and paving the way for enhanced cross-linguistic communication tools.
Read more9/24/2024
0
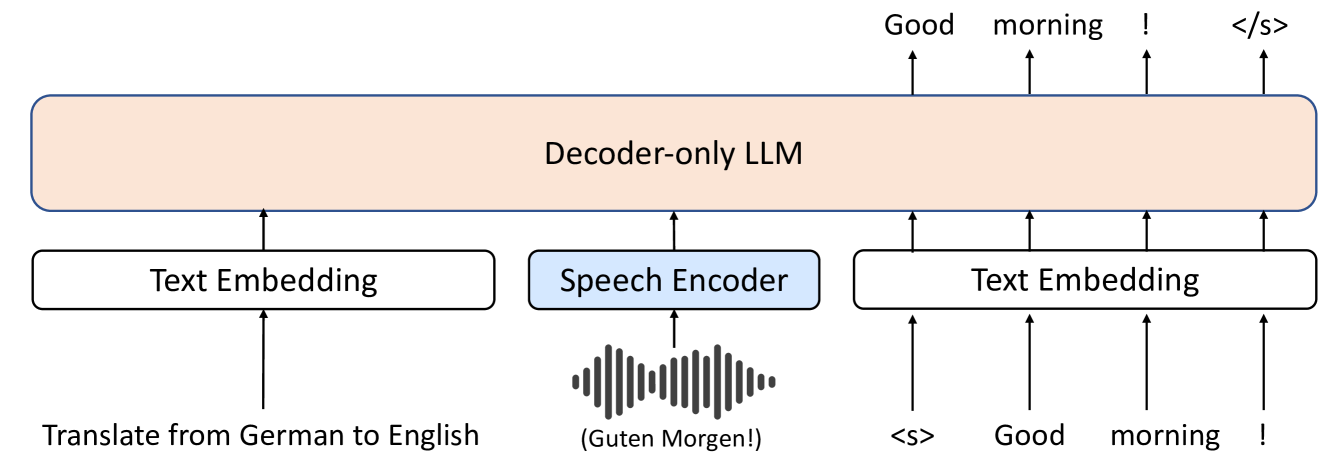
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
Read more7/4/2024

0
Encoder vs Decoder: Comparative Analysis of Encoder and Decoder Language Models on Multilingual NLU Tasks
Dan Saattrup Nielsen, Kenneth Enevoldsen, Peter Schneider-Kamp
This paper explores the performance of encoder and decoder language models on multilingual Natural Language Understanding (NLU) tasks, with a broad focus on Germanic languages. Building upon the ScandEval benchmark, which initially was restricted to evaluating encoder models, we extend the evaluation framework to include decoder models. We introduce a method for evaluating decoder models on NLU tasks and apply it to the languages Danish, Swedish, Norwegian, Icelandic, Faroese, German, Dutch, and English. Through a series of experiments and analyses, we address key research questions regarding the comparative performance of encoder and decoder models, the impact of NLU task types, and the variation across language resources. Our findings reveal that decoder models can achieve significantly better NLU performance than encoder models, with nuances observed across different tasks and languages. Additionally, we investigate the correlation between decoders and task performance via a UMAP analysis, shedding light on the unique capabilities of decoder and encoder models. This study contributes to a deeper understanding of language model paradigms in NLU tasks and provides valuable insights for model selection and evaluation in multilingual settings.
Read more6/21/2024
0
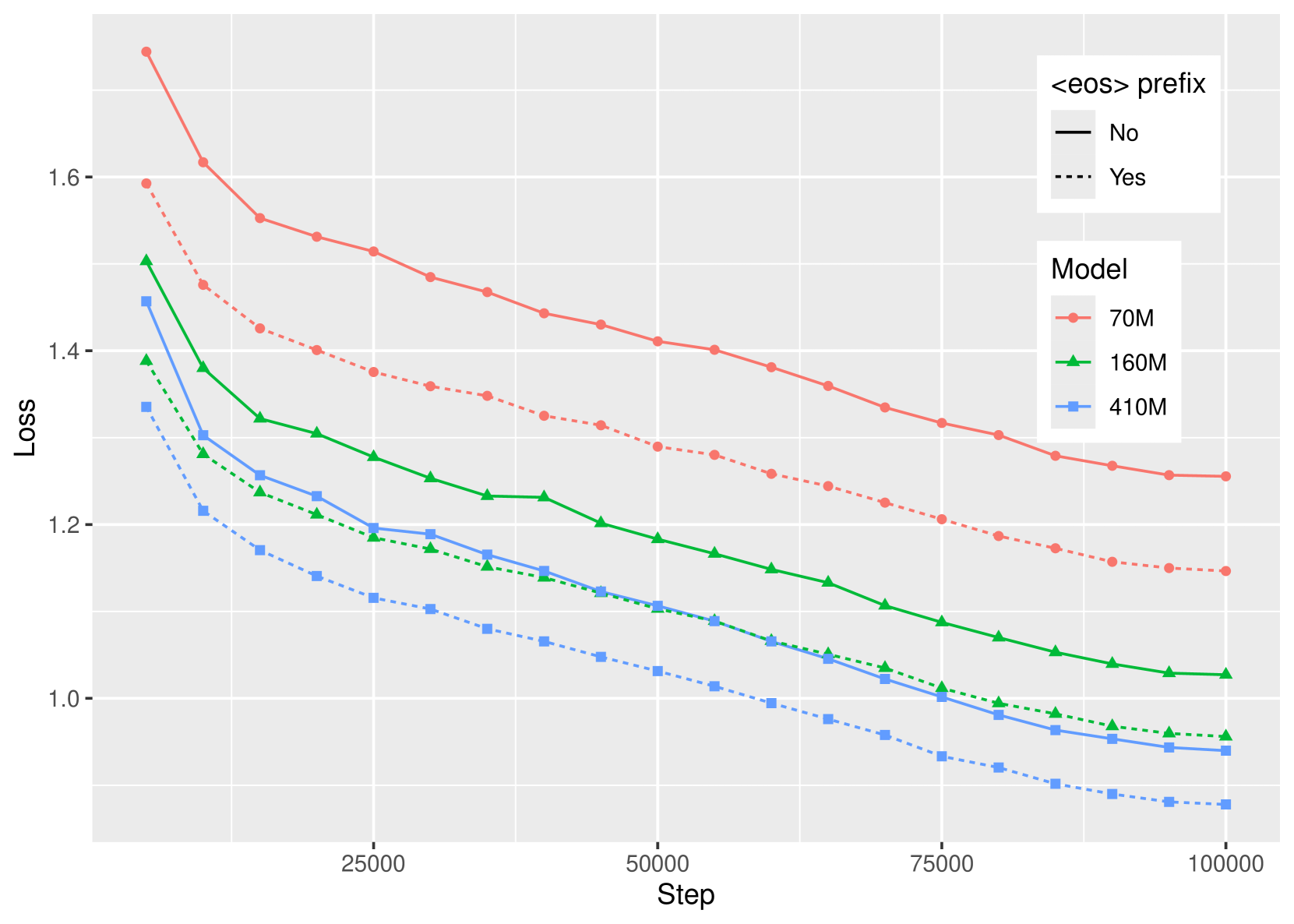
Scaling Laws of Decoder-Only Models on the Multilingual Machine Translation Task
Gaetan Caillaut, Raheel Qader, Mariam Nakhl'e, Jingshu Liu, Jean-Gabriel Barth'elemy
Recent studies have showcased remarkable capabilities of decoder-only models in many NLP tasks, including translation. Yet, the machine translation field has been largely dominated by encoder-decoder models based on the Transformer architecture. As a consequence, scaling laws of encoder-decoder models for neural machine translation have already been well studied, but decoder-only models have received less attention. This work explores the scaling laws of decoder-only models on the multilingual and multidomain translation task. We trained a collection of six decoder-only models, ranging from 70M to 7B parameters, on a sentence-level, multilingual and multidomain dataset. We conducted a series of experiments showing that the loss of decoder-only models can be estimated using a scaling law similar to the one discovered for large language models, but we also show that this scaling law has difficulties to generalize to too large models or to a different data distribution. We also study different scaling methods and show that scaling the depth and the width of a model lead to similar test loss improvements, but with different impact on the model's efficiency.
Read more9/24/2024