Scaling Laws of Decoder-Only Models on the Multilingual Machine Translation Task

0
Sign in to get full access
Overview
- This paper examines the scaling behavior of decoder-only language models on the task of multilingual machine translation.
- The researchers train large decoder-only models on a diverse set of languages and measure their translation performance as model size and compute scale.
- The results provide insights into the capabilities and limitations of decoder-only models compared to traditional encoder-decoder architectures for machine translation.
Plain English Explanation
The paper looks at how the performance of language models that only have a decoder (and no encoder) changes as the models get bigger and are trained on more computing power. These decoder-only models are used for the task of multilingual machine translation, which is the process of automatically translating text between multiple languages.
The researchers trained large language models that only have a decoder component on a diverse set of languages. They then measured how well these models could translate between the different languages as the model size and the amount of computing power used to train them increased.
The results provide insights into the capabilities and limitations of decoder-only language models compared to traditional machine translation models that have both an encoder and a decoder. This can help researchers understand when it makes sense to use simpler decoder-only models versus more complex encoder-decoder architectures for different language tasks.
Technical Explanation
The paper investigates the scaling laws of decoder-only language models on the task of multilingual machine translation. The researchers train large decoder-only models on a diverse set of languages and measure their translation performance as a function of model size and compute used during training.
The experiments use a decoder-only model architecture based on the Transformer, which is a popular neural network design for language tasks. The models are trained on a large multilingual dataset covering 100 languages. Translation performance is evaluated using standard metrics like BLEU score.
The results show that decoder-only models can achieve strong multilingual translation capabilities, on par with or exceeding traditional encoder-decoder architectures, as model and compute scale increase. However, the models exhibit some limitations compared to encoder-decoder models, such as poorer performance on low-resource languages.
The scaling laws observed provide insights into the strengths and weaknesses of the decoder-only approach for machine translation. This can help inform decisions about when to use simpler decoder-only models versus more complex encoder-decoder architectures for different language tasks and data regimes.
Critical Analysis
The paper provides a thorough and rigorously designed study of the scaling behavior of decoder-only models for multilingual machine translation. The use of a large and diverse language dataset is a particular strength, allowing the researchers to draw conclusions about a wide range of language pairs.
However, the paper does acknowledge some limitations of the decoder-only approach. The models are shown to struggle more with low-resource languages compared to higher-resource ones. This suggests that for certain applications, an encoder-decoder architecture may still be preferable, especially when dealing with underrepresented languages.
Additionally, the paper does not explore the interpretability or explainability of the decoder-only models. As these models become larger and more powerful, understanding their inner workings and decision-making processes becomes increasingly important, especially for high-stakes applications like translation. Further research in this area could provide valuable insights.
Overall, this paper makes a significant contribution to our understanding of the capabilities and tradeoffs of decoder-only language models for machine translation tasks. The findings can help guide the development of more efficient and effective language models for a variety of applications.
Conclusion
This paper presents a comprehensive study of the scaling behavior of decoder-only language models on the task of multilingual machine translation. The results show that these simpler models can achieve strong translation performance as model size and compute power increase, sometimes even exceeding the capabilities of traditional encoder-decoder architectures.
However, the paper also identifies limitations of the decoder-only approach, particularly for low-resource languages. This suggests that the choice between decoder-only and encoder-decoder models for machine translation should consider the specific language requirements of the application.
The insights provided by this research can inform the development of more efficient and effective language models for a variety of translation and multilingual tasks. As language models continue to scale, understanding their strengths, weaknesses, and tradeoffs will be crucial for building practical and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Laws of Decoder-Only Models on the Multilingual Machine Translation Task
Gaetan Caillaut, Raheel Qader, Mariam Nakhl'e, Jingshu Liu, Jean-Gabriel Barth'elemy
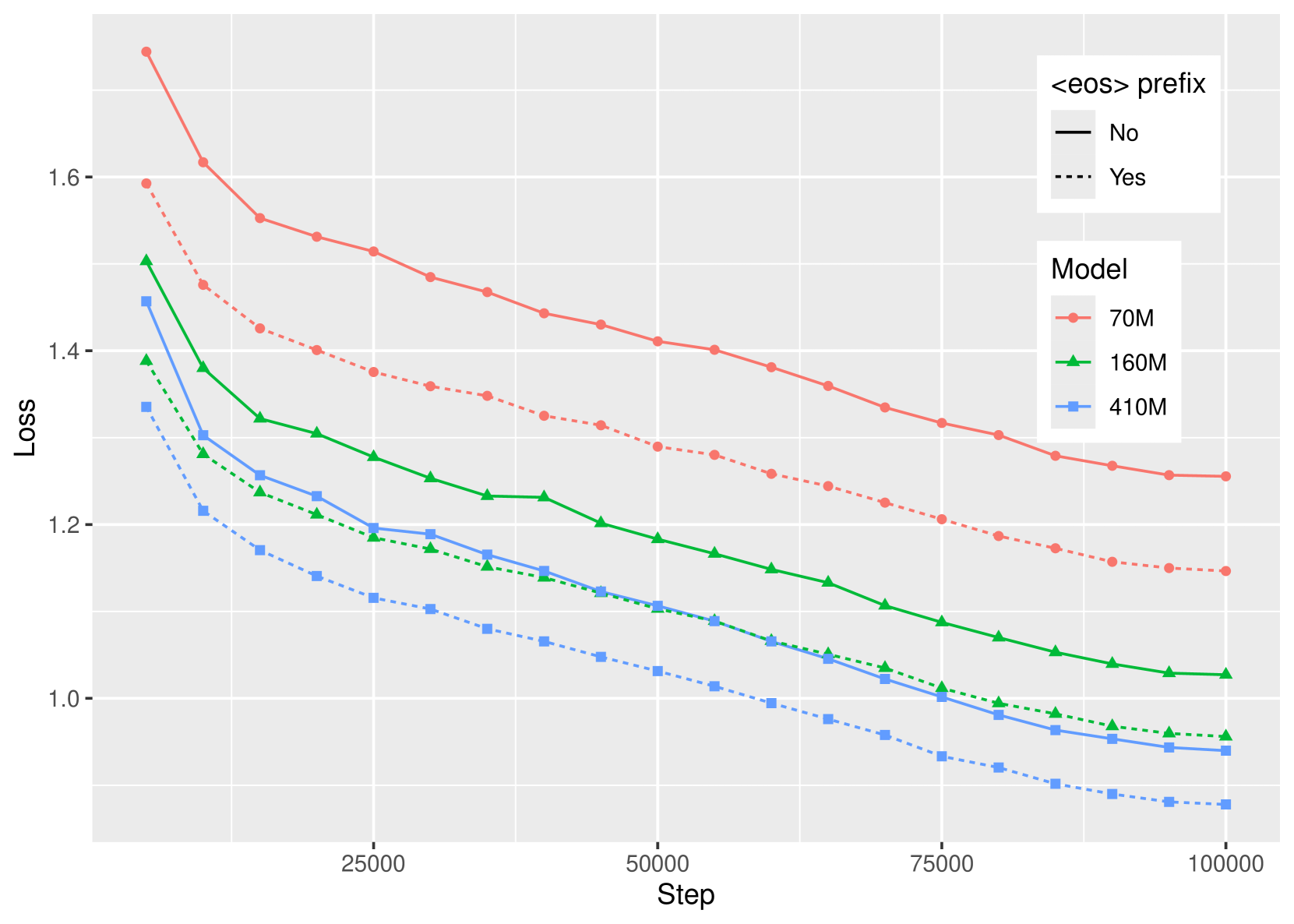
Recent studies have showcased remarkable capabilities of decoder-only models in many NLP tasks, including translation. Yet, the machine translation field has been largely dominated by encoder-decoder models based on the Transformer architecture. As a consequence, scaling laws of encoder-decoder models for neural machine translation have already been well studied, but decoder-only models have received less attention. This work explores the scaling laws of decoder-only models on the multilingual and multidomain translation task. We trained a collection of six decoder-only models, ranging from 70M to 7B parameters, on a sentence-level, multilingual and multidomain dataset. We conducted a series of experiments showing that the loss of decoder-only models can be estimated using a scaling law similar to the one discovered for large language models, but we also show that this scaling law has difficulties to generalize to too large models or to a different data distribution. We also study different scaling methods and show that scaling the depth and the width of a model lead to similar test loss improvements, but with different impact on the model's efficiency.
Read more9/24/2024

0
Machine Translation with Large Language Models: Decoder Only vs. Encoder-Decoder
Abhinav P. M., SujayKumar Reddy M, Oswald Christopher
This project, titled Machine Translation with Large Language Models: Decoder-only vs. Encoder-Decoder, aims to develop a multilingual machine translation (MT) model. Focused on Indian regional languages, especially Telugu, Tamil, and Malayalam, the model seeks to enable accurate and contextually appropriate translations across diverse language pairs. By comparing Decoder-only and Encoder-Decoder architectures, the project aims to optimize translation quality and efficiency, advancing cross-linguistic communication tools.The primary objective is to develop a model capable of delivering high-quality translations that are accurate and contextually appropriate. By leveraging large language models, specifically comparing the effectiveness of Decoder-only and Encoder-Decoder architectures, the project seeks to optimize translation performance and efficiency across multilingual contexts. Through rigorous experimentation and analysis, this project aims to advance the field of machine translation, contributing valuable insights into the effectiveness of different model architectures and paving the way for enhanced cross-linguistic communication tools.
Read more9/24/2024
0
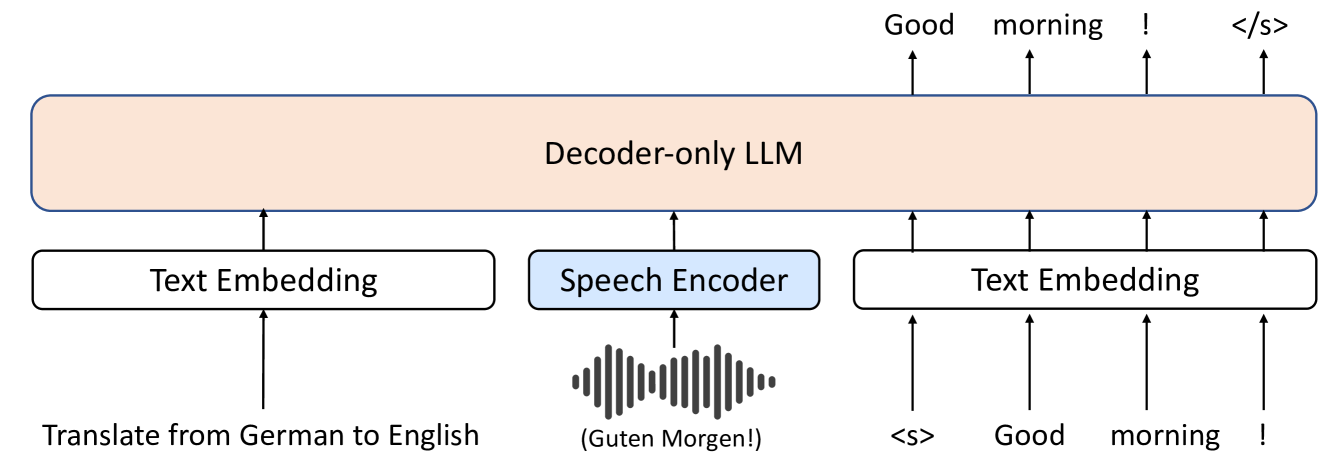
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
Read more7/4/2024
👨🏫
0
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
Read more5/24/2024