Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing

1

Sign in to get full access
Overview
- This research paper introduces Magpie, a scalable method for synthesizing high-quality instruction data by prompting aligned large language models (LLMs) with nothing.
- Magpie aims to address the challenge of obtaining sufficient high-quality instruction data to train instruction-following AI systems, a key requirement for developing safe and capable AI assistants.
- The paper demonstrates that Magpie can produce large, diverse datasets of instructional text that rival the quality of human-written data, without the need for expensive data collection or curation efforts.
Plain English Explanation
Imagine you wanted to build an AI assistant that could follow complex instructions, like a digital personal assistant that could help you with tasks around the house. To train such an AI, you'd need a large dataset of high-quality instructions that cover a wide range of topics. However, collecting and curating this kind of data from humans can be incredibly time-consuming and expensive.
The Magpie method offers a solution to this problem. By prompting language models that have already been trained to be helpful and aligned with human values, Magpie can generate large, diverse datasets of instructional text that rival the quality of human-written data. This is done without the need for expensive data collection or curation efforts.
The key insight behind Magpie is that by carefully prompting these pre-trained, aligned language models, you can coax them to generate highly relevant and coherent instructions from scratch, on a wide variety of topics. This allows you to quickly and scalably create the kind of high-quality instructional data needed to train capable AI assistants, without relying solely on human-written examples.
Technical Explanation
The Magpie method works by leveraging aligned large language models (LLMs) that have been pre-trained to be helpful and follow instructions. By prompting these models with carefully crafted prompts, the authors demonstrate that Magpie can generate large, diverse datasets of high-quality instructional text without the need for expensive data collection or curation efforts.
The key innovation of Magpie is its prompt engineering approach. The authors develop prompting strategies that elicit coherent, relevant, and diverse instructions from the aligned LLMs. These prompts are designed to guide the models to generate instructions that cover a wide range of topics and tasks, while maintaining high quality and adhering to desired properties, such as safety and helpfulness.
Through extensive experiments, the authors show that the instructional data generated by Magpie rivals the quality of human-written data, as evaluated by both automated metrics and human raters. They also demonstrate that models trained on Magpie-generated data can achieve strong performance on instruction-following tasks, comparable to or exceeding models trained on human-written data.
The Magpie method builds upon and complements other recent research on instruction data synthesis, simulator-augmented instruction alignment, and scaling instructions from the web, showcasing the potential of prompt-based data synthesis to address the challenge of obtaining high-quality instruction data for training capable AI assistants.
Critical Analysis
The Magpie method represents a promising approach to synthesizing high-quality instruction data, but it is not without its limitations. The authors acknowledge that the generated instructions may not always be 100% accurate or consistent, and that further research is needed to improve the reliability and robustness of the generated data.
Additionally, the authors note that the Magpie method relies on the availability of pre-trained, aligned LLMs, which may not be readily accessible to all researchers and developers. The broader challenge of aligning large language models with human values remains an active area of research.
It is also important to consider potential biases and safety concerns that may arise from the Magpie-generated data, as with any synthetic data generation approach. The authors suggest that further work is needed to ensure the generated instructions adhere to desired properties, such as safety and ethics, and to address potential misuse or unintended consequences.
Despite these limitations, the Magpie method represents a significant step forward in the quest to obtain high-quality instruction data for training capable AI assistants. As the field of AI continues to advance, innovative approaches like Magpie will likely play an increasingly important role in addressing the data challenges faced by researchers and developers.
Conclusion
The Magpie method introduced in this research paper offers a scalable and cost-effective approach to synthesizing high-quality instruction data for training instruction-following AI systems. By leveraging pre-trained, aligned large language models and carefully crafted prompting strategies, Magpie can generate large, diverse datasets of instructional text that rival the quality of human-written data.
This breakthrough has important implications for the development of safe and capable AI assistants, as it addresses a key challenge in obtaining the necessary instructional data to train such systems. The Magpie method complements other ongoing research in the field, showcasing the potential of prompt-based data synthesis to accelerate progress in AI development and deployment.
While the Magpie method has some limitations and areas for further research, it represents a significant step forward in the quest to build AI systems that can reliably understand and follow complex instructions, ultimately enhancing their ability to assist and collaborate with humans in meaningful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, Bill Yuchen Lin
High-quality instruction data is critical for aligning large language models (LLMs). Although some models, such as Llama-3-Instruct, have open weights, their alignment data remain private, which hinders the democratization of AI. High human labor costs and a limited, predefined scope for prompting prevent existing open-source data creation methods from scaling effectively, potentially limiting the diversity and quality of public alignment datasets. Is it possible to synthesize high-quality instruction data at scale by extracting it directly from an aligned LLM? We present a self-synthesis method for generating large-scale alignment data named Magpie. Our key observation is that aligned LLMs like Llama-3-Instruct can generate a user query when we input only the left-side templates up to the position reserved for user messages, thanks to their auto-regressive nature. We use this method to prompt Llama-3-Instruct and generate 4 million instructions along with their corresponding responses. We perform a comprehensive analysis of the extracted data and select 300K high-quality instances. To compare Magpie data with other public instruction datasets, we fine-tune Llama-3-8B-Base with each dataset and evaluate the performance of the fine-tuned models. Our results indicate that in some tasks, models fine-tuned with Magpie perform comparably to the official Llama-3-8B-Instruct, despite the latter being enhanced with 10 million data points through supervised fine-tuning (SFT) and subsequent feedback learning. We also show that using Magpie solely for SFT can surpass the performance of previous public datasets utilized for both SFT and preference optimization, such as direct preference optimization with UltraFeedback. This advantage is evident on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
Read more6/13/2024
1
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
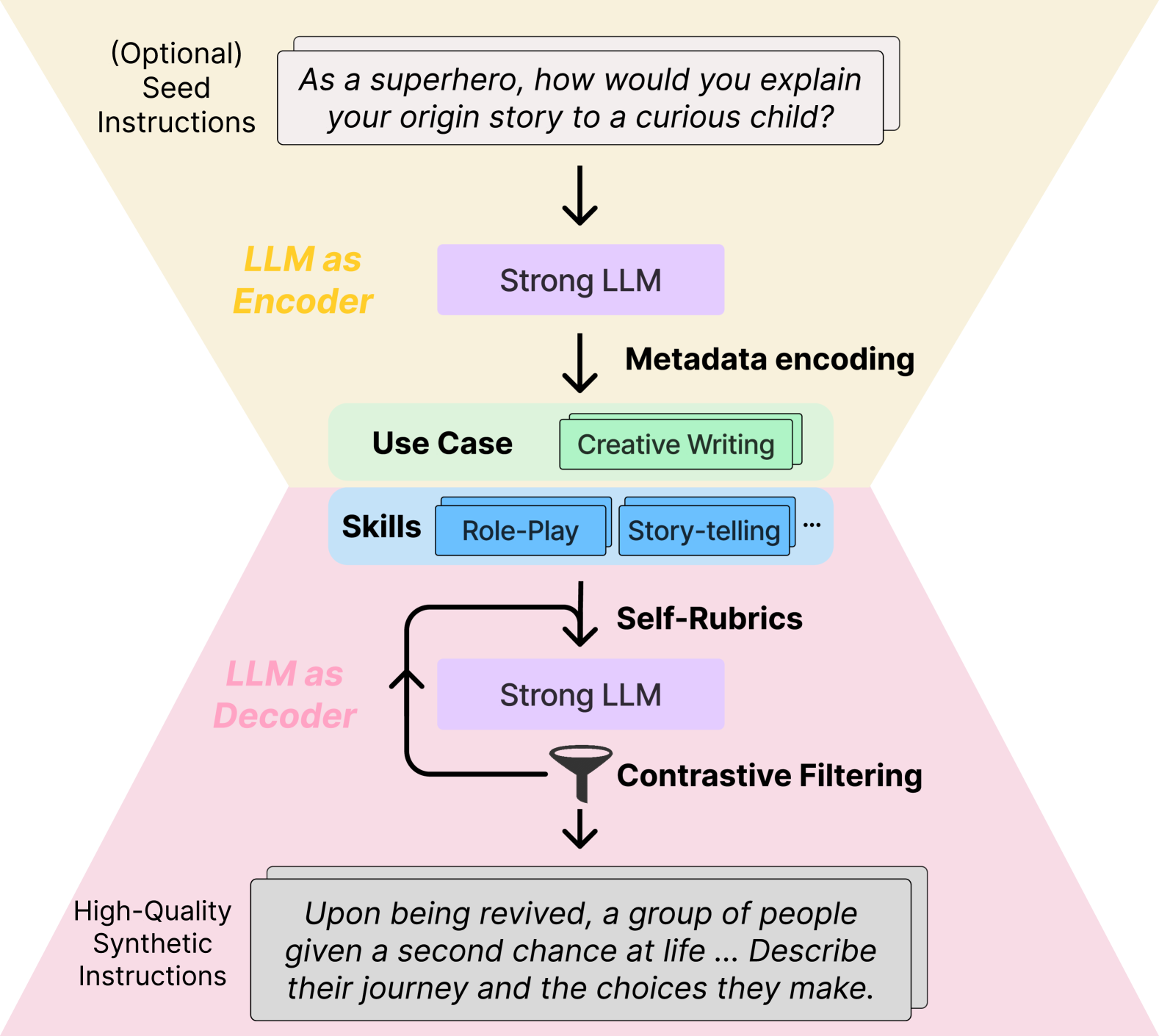
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Read more4/10/2024

0
Better Alignment with Instruction Back-and-Forth Translation
Thao Nguyen, Jeffrey Li, Sewoong Oh, Ludwig Schmidt, Jason Weston, Luke Zettlemoyer, Xian Li
We propose a new method, instruction back-and-forth translation, to construct high-quality synthetic data grounded in world knowledge for aligning large language models (LLMs). Given documents from a web corpus, we generate and curate synthetic instructions using the backtranslation approach proposed by Li et al.(2023a), and rewrite the responses to improve their quality further based on the initial documents. Fine-tuning with the resulting (backtranslated instruction, rewritten response) pairs yields higher win rates on AlpacaEval than using other common instruction datasets such as Humpback, ShareGPT, Open Orca, Alpaca-GPT4 and Self-instruct. We also demonstrate that rewriting the responses with an LLM outperforms direct distillation, and the two generated text distributions exhibit significant distinction in embedding space. Further analysis shows that our backtranslated instructions are of higher quality than other sources of synthetic instructions, while our responses are more diverse and complex than those obtained from distillation. Overall we find that instruction back-and-forth translation combines the best of both worlds -- making use of the information diversity and quantity found on the web, while ensuring the quality of the responses which is necessary for effective alignment.
Read more8/15/2024
🖼️
0
Aligners: Decoupling LLMs and Alignment
Lilian Ngweta, Mayank Agarwal, Subha Maity, Alex Gittens, Yuekai Sun, Mikhail Yurochkin
Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We use the same synthetic data to train inspectors, binary miss-alignment classification models to guide a squad of multiple aligners. Our empirical results demonstrate consistent improvements when applying aligner squad to various LLMs, including chat-aligned models, across several instruction-following and red-teaming datasets.
Read more6/18/2024