MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
2405.16265
0
0

Abstract
Although Large Language Models (LLMs) achieve remarkable performance across various tasks, they often struggle with complex reasoning tasks, such as answering mathematical questions. Recent efforts to address this issue have primarily focused on leveraging mathematical datasets through supervised fine-tuning or self-improvement techniques. However, these methods often depend on high-quality datasets that are difficult to prepare, or they require substantial computational resources for fine-tuning. Inspired by findings that LLMs know how to produce the right answer but struggle to select the correct reasoning path, we propose a purely inference-based searching method -- MindStar (M*). This method formulates reasoning tasks as searching problems and proposes two search ideas to identify the optimal reasoning paths. We evaluate the M* framework on both the GSM8K and MATH datasets, comparing its performance with existing open and closed-source LLMs. Our results demonstrate that M* significantly enhances the reasoning abilities of open-source models, such as Llama-2-13B and Mistral-7B, and achieves comparable performance to GPT-3.5 and Grok-1, but with substantially reduced model size and computational costs.
Create account to get full access
Overview
- This paper introduces MindStar, a method to enhance the mathematical reasoning capabilities of pre-trained large language models (LLMs) at inference time.
- The key idea is to leverage the inherent knowledge in pre-trained LLMs to improve their ability to solve math-related tasks, without requiring additional training.
- MindStar works by dynamically injecting math-specific reasoning steps into the language model's output, guiding it towards more accurate and interpretable solutions.
Plain English Explanation
MindStar is a technique that can make pre-trained language models better at solving math problems, without having to retrain the models from scratch. Language models are AI systems that can understand and generate human-like text, but they often struggle with complex mathematical reasoning.
The core idea behind MindStar is to tap into the existing knowledge that these language models have already learned, and use that to enhance their math-solving capabilities. It does this by dynamically injecting additional reasoning steps into the model's output, sort of like providing a step-by-step guide to solving the math problem.
This allows the language model to leverage its broad understanding of language and concepts, while also being guided towards more accurate and interpretable solutions for math-related tasks. The end result is an AI system that can better assist humans with math-heavy tasks, without requiring a complete overhaul of the underlying language model.
Technical Explanation
The MindStar approach works by dynamically injecting math-specific reasoning steps into the output of a pre-trained language model during inference time. This is achieved through the use of a math reasoning module that analyzes the input problem, identifies the relevant mathematical concepts, and generates a sequence of reasoning steps to guide the language model towards a more accurate solution.
The math reasoning module is designed to be modular and pluggable, allowing it to be easily integrated with different pre-trained language models. It operates by parsing the input problem, mapping it to relevant mathematical concepts, and then generating a sequence of reasoning steps that can be seamlessly incorporated into the language model's output.
By dynamically injecting these reasoning steps, MindStar is able to leverage the inherent knowledge and broad understanding of the pre-trained language model, while also guiding it towards more accurate and interpretable solutions for math-related tasks. This approach does not require retraining the entire language model, making it a efficient and scalable way to enhance the mathematical reasoning capabilities of large language models.
Critical Analysis
The MindStar approach presents a promising way to improve the mathematical reasoning abilities of pre-trained language models, without the need for extensive retraining. By dynamically injecting math-specific reasoning steps, the method effectively leverages the existing knowledge in the language model while providing targeted guidance for solving math problems.
However, the paper does not address several potential limitations and areas for further research:
-
Generalization Capabilities: The paper does not provide a thorough evaluation of how well the MindStar approach generalizes to a diverse range of math-related tasks and problem types. Further testing on a broader set of benchmarks would be valuable to assess the robustness and versatility of the method.
-
Scalability and Efficiency: While the authors claim that MindStar is an efficient and scalable approach, the paper does not provide detailed performance metrics or comparisons to other math-enhancement techniques, such as MindMerger, InternLM, or JiuZhang30.
-
Interpretability and Transparency: The paper does not delve into the interpretability of the reasoning steps generated by the math reasoning module. Providing more insight into the decision-making process and the ability to understand the model's reasoning could be valuable for end-users and researchers alike.
-
Limitations and Potential Biases: The paper does not discuss any potential limitations or biases that may be introduced by the MindStar approach, such as the impact of the training data used for the math reasoning module or the ability to handle edge cases and uncommon problem types.
Overall, the MindStar approach is a promising step towards enhancing the mathematical reasoning capabilities of pre-trained language models, but further research and evaluation are needed to fully assess its merits and limitations. Comparing it to other approaches in the field and exploring its interpretability and robustness would be valuable next steps.
Conclusion
The MindStar paper presents a novel approach to improving the mathematical reasoning capabilities of pre-trained large language models at inference time, without the need for extensive retraining. By dynamically injecting math-specific reasoning steps into the model's output, MindStar leverages the inherent knowledge and broad understanding of these language models to guide them towards more accurate and interpretable solutions for math-related tasks.
This method offers a scalable and efficient way to enhance the math-solving abilities of AI systems, which can have significant implications for a wide range of applications, from educational tools to decision-support systems. While the paper highlights the promise of the MindStar approach, further research and evaluation are needed to fully assess its capabilities, limitations, and potential biases.
As the field of natural language processing continues to advance, techniques like MindStar that can bridge the gap between language understanding and mathematical reasoning will become increasingly important in developing AI systems that can truly assist and empower human users across a diverse range of tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems
Nasim Borazjanizadeh, Roei Herzig, Trevor Darrell, Rogerio Feris, Leonid Karlinsky
0
0
Recently, Large Language Models (LLMs) attained impressive performance in math and reasoning benchmarks. However, they still often struggle with logic problems and puzzles that are relatively easy for humans. To further investigate this, we introduce a new benchmark, SearchBench, containing 11 unique search problem types, each equipped with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions. We show that even the most advanced LLMs fail to solve these problems end-to-end in text, e.g. GPT4 solves only 1.4%. SearchBench problems require considering multiple pathways to the solution as well as backtracking, posing a significant challenge to auto-regressive models. Instructing LLMs to generate code that solves the problem helps, but only slightly, e.g., GPT4's performance rises to 11.7%. In this work, we show that in-context learning with A* algorithm implementations enhances performance. The full potential of this promoting approach emerges when combined with our proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, raising GPT-4's performance above 57%.
6/19/2024

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024
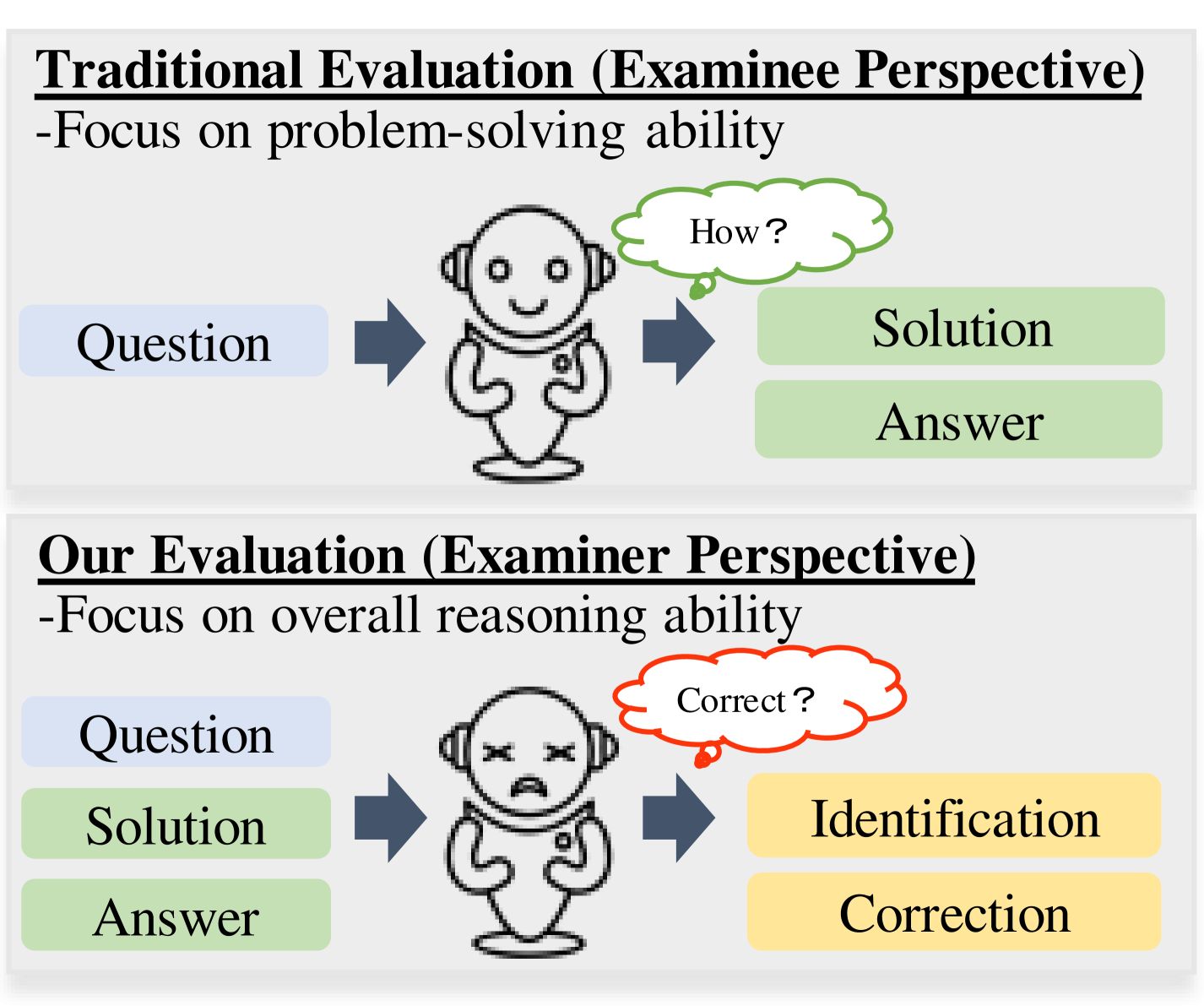
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024