Massively Multiagent Minigames for Training Generalist Agents

0
🏋️
Sign in to get full access
Overview
- The researchers have created a new reinforcement learning benchmark called "Meta MMO" that is built on top of the existing "Neural MMO" environment.
- Neural MMO is a massively multi-agent environment that has been used in previous NeurIPS competitions.
- Meta MMO expands on Neural MMO by adding several computationally efficient minigames.
- The goal is to explore generalization by learning to play multiple minigames using a single set of weights.
- The researchers have released the environment, baselines, and training code under the MIT license.
- The hope is that Meta MMO will spur further progress on Neural MMO and serve as a useful benchmark for multi-agent generalization.
Plain English Explanation
The researchers have developed a new set of mini-games, called Meta MMO, that can be used to test how well AI systems can learn to play different games using the same underlying model. This builds on an existing environment called Neural MMO, which is a complex virtual world with many different agents interacting with each other.
The key idea is to see if an AI system can learn general skills that allow it to perform well across a variety of mini-games, rather than having to learn a separate model for each game. This could be a useful benchmark for evaluating how well AI agents can generalize their knowledge and capabilities to new situations.
The researchers have made the Meta MMO environment, along with some baseline models and training code, freely available to the research community. They hope this will spur further progress in multi-agent reinforcement learning and help advance the state of the art in large-scale, open-ended AI systems.
Technical Explanation
The core of the Meta MMO environment is the Neural MMO platform, which is a massively multi-agent virtual world that has been the subject of previous NeurIPS competitions. The researchers have expanded on this by adding a collection of computationally efficient minigames that can be used as a reinforcement learning benchmark.
The goal is to test an AI agent's ability to generalize its knowledge and skills across these different minigames. Rather than training a separate model for each game, the researchers want to see if a single set of weights can be learned that allows the agent to perform well on multiple tasks.
To facilitate this, the researchers have designed the minigames to be computationally efficient, allowing for faster training and experimentation. They have also provided baseline models and training code to help other researchers get started with the benchmark.
Critical Analysis
One potential limitation of the Meta MMO benchmark is that the minigames may not fully capture the complexity and dynamic nature of the original Neural MMO environment. While the minigames are designed to be computationally efficient, this could come at the cost of losing some of the richness and realism of the larger virtual world.
Additionally, the researchers acknowledge that generalization across the minigames may not necessarily translate to generalization in the broader multi-agent domain. The skills required to excel at the minigames may be quite different from those needed to navigate the complex social and strategic dynamics of the Neural MMO world.
It will be important for future research to carefully examine the limitations of the Meta MMO benchmark and explore ways to bridge the gap between the minigames and the more comprehensive Neural MMO environment. This could involve developing new techniques for large-scale, open-ended AI systems that can effectively generalize across a wide range of tasks and scenarios.
Conclusion
The Meta MMO benchmark represents an interesting step forward in the development of reinforcement learning environments for evaluating multi-agent systems. By expanding on the existing Neural MMO platform and introducing a collection of computationally efficient minigames, the researchers have created a new tool for exploring generalization in the context of multi-agent reinforcement learning.
If successful, the Meta MMO benchmark could help drive progress in the development of large-scale, open-ended AI systems that can adapt and thrive in complex, dynamic environments. However, it will be important to continue examining the limitations of the benchmark and finding ways to bridge the gap between the minigames and the more comprehensive Neural MMO world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Massively Multiagent Minigames for Training Generalist Agents
Kyoung Whan Choe, Ryan Sullivan, Joseph Su'arez
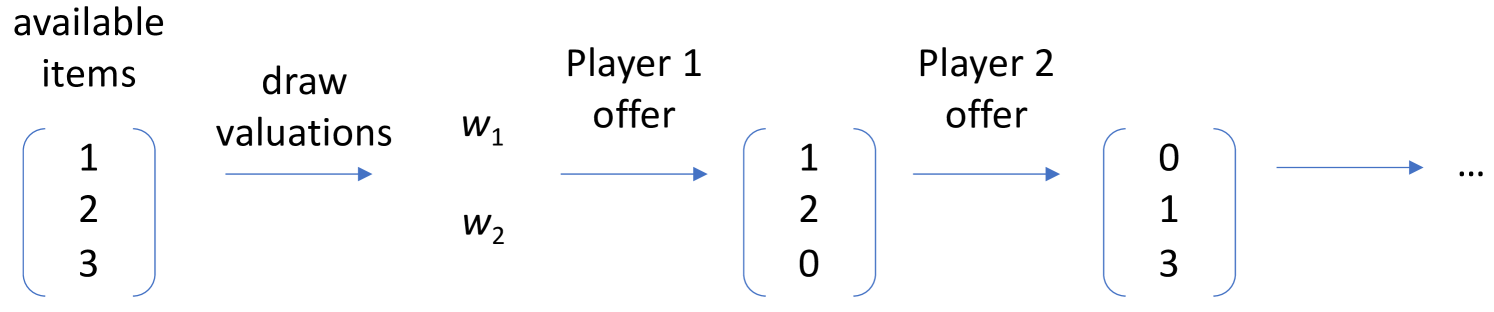
We present Meta MMO, a collection of many-agent minigames for use as a reinforcement learning benchmark. Meta MMO is built on top of Neural MMO, a massively multiagent environment that has been the subject of two previous NeurIPS competitions. Our work expands Neural MMO with several computationally efficient minigames. We explore generalization across Meta MMO by learning to play several minigames with a single set of weights. We release the environment, baselines, and training code under the MIT license. We hope that Meta MMO will spur additional progress on Neural MMO and, more generally, will serve as a useful benchmark for many-agent generalization.
Read more6/10/2024
0
A Meta-Game Evaluation Framework for Deep Multiagent Reinforcement Learning
Zun Li, Michael P. Wellman
Evaluating deep multiagent reinforcement learning (MARL) algorithms is complicated by stochasticity in training and sensitivity of agent performance to the behavior of other agents. We propose a meta-game evaluation framework for deep MARL, by framing each MARL algorithm as a meta-strategy, and repeatedly sampling normal-form empirical games over combinations of meta-strategies resulting from different random seeds. Each empirical game captures both self-play and cross-play factors across seeds. These empirical games provide the basis for constructing a sampling distribution, using bootstrapping, over a variety of game analysis statistics. We use this approach to evaluate state-of-the-art deep MARL algorithms on a class of negotiation games. From statistics on individual payoffs, social welfare, and empirical best-response graphs, we uncover strategic relationships among self-play, population-based, model-free, and model-based MARL methods.We also investigate the effect of run-time search as a meta-strategy operator, and find via meta-game analysis that the search version of a meta-strategy generally leads to improved performance.
Read more5/2/2024

0
Constrained Meta Agnostic Reinforcement Learning
Karam Daaboul, Florian Kuhm, Tim Joseph, J. Marius Zoellner
Meta-Reinforcement Learning (Meta-RL) aims to acquire meta-knowledge for quick adaptation to diverse tasks. However, applying these policies in real-world environments presents a significant challenge in balancing rapid adaptability with adherence to environmental constraints. Our novel approach, Constraint Model Agnostic Meta Learning (C-MAML), merges meta learning with constrained optimization to address this challenge. C-MAML enables rapid and efficient task adaptation by incorporating task-specific constraints directly into its meta-algorithm framework during the training phase. This fusion results in safer initial parameters for learning new tasks. We demonstrate the effectiveness of C-MAML in simulated locomotion with wheeled robot tasks of varying complexity, highlighting its practicality and robustness in dynamic environments.
Read more6/21/2024

0
A Blockchain-based Reliable Federated Meta-learning for Metaverse: A Dual Game Framework
Emna Baccour, Aiman Erbad, Amr Mohamed, Mounir Hamdi, Mohsen Guizani
The metaverse, envisioned as the next digital frontier for avatar-based virtual interaction, involves high-performance models. In this dynamic environment, users' tasks frequently shift, requiring fast model personalization despite limited data. This evolution consumes extensive resources and requires vast data volumes. To address this, meta-learning emerges as an invaluable tool for metaverse users, with federated meta-learning (FML), offering even more tailored solutions owing to its adaptive capabilities. However, the metaverse is characterized by users heterogeneity with diverse data structures, varied tasks, and uneven sample sizes, potentially undermining global training outcomes due to statistical difference. Given this, an urgent need arises for smart coalition formation that accounts for these disparities. This paper introduces a dual game-theoretic framework for metaverse services involving meta-learners as workers to manage FML. A blockchain-based cooperative coalition formation game is crafted, grounded on a reputation metric, user similarity, and incentives. We also introduce a novel reputation system based on users' historical contributions and potential contributions to present tasks, leveraging correlations between past and new tasks. Finally, a Stackelberg game-based incentive mechanism is presented to attract reliable workers to participate in meta-learning, minimizing users' energy costs, increasing payoffs, boosting FML efficacy, and improving metaverse utility. Results show that our dual game framework outperforms best-effort, random, and non-uniform clustering schemes - improving training performance by up to 10%, cutting completion times by as much as 30%, enhancing metaverse utility by more than 25%, and offering up to 5% boost in training efficiency over non-blockchain systems, effectively countering misbehaving users.
Read more8/9/2024