MedVH: Towards Systematic Evaluation of Hallucination for Large Vision Language Models in the Medical Context

0

Sign in to get full access
Overview
- This paper introduces MedVH, a new dataset and benchmarks for systematically evaluating hallucination in large vision-language models in the medical context.
- Hallucination refers to the phenomenon where these models generate plausible-sounding but factually incorrect responses.
- The authors argue that existing hallucination benchmarks do not capture the unique challenges of the medical domain, motivating the creation of MedVH.
- MedVH includes a diverse set of medical images and questions that require models to reason about visual information, medical knowledge, and language understanding.
Plain English Explanation
The paper discusses a new dataset and set of tests called MedVH that are designed to evaluate how well large AI models that work with both text and images can handle the unique challenges of the medical field. These models, known as vision-language models, can sometimes generate responses that sound plausible but are actually incorrect or made up - a phenomenon called "hallucination."
The authors felt that existing hallucination benchmarks didn't capture the specific difficulties of the medical domain, so they created MedVH. This dataset includes a variety of medical images and questions that require the models to draw on both visual information and medical knowledge, as well as strong language understanding skills. By testing the models on this more specialized dataset, the researchers hope to get a better sense of how well these systems can handle real-world medical scenarios without hallucinating incorrect information.
Technical Explanation
The paper introduces MedVH: Towards Systematic Evaluation of Hallucination for Large Vision Language Models in the Medical Context, a new dataset and benchmark for evaluating hallucination in large vision-language models in the medical domain.
The authors argue that existing hallucination benchmarks, such as A Survey of Hallucination in Large Language Models and MedThink: Inducing Medical Knowledge in Large-Scale Visual-Language Models, do not capture the unique challenges of the medical context. To address this, they create MedVH, which includes a diverse set of medical images and questions that require models to reason about visual information, medical knowledge, and language understanding.
The MedVH dataset is constructed by scraping a large corpus of medical images and associated captions from the web. The authors then manually curate a set of questions that target different aspects of medical understanding, such as anatomy, diagnosis, and treatment. These questions are paired with the relevant medical images to create the final benchmark.
The authors evaluate several state-of-the-art vision-language models on the MedVH dataset, including Visual Hallucinations in Multi-Modal Large Language Models and A Hallucination Benchmark for Medical Visual Question Answering. Their results show that these models struggle to provide accurate and factual responses, particularly on questions that require a deep understanding of medical concepts.
Critical Analysis
The MedVH dataset and benchmarks presented in this paper are a valuable contribution to the field of large vision-language models, particularly in the medical domain. The authors rightly identify the limitations of existing hallucination evaluation frameworks and the need for more specialized benchmarks that capture the unique challenges of medical reasoning.
One potential caveat is the reliance on web-scraped data for the MedVH dataset. While this approach allows for the creation of a diverse and large-scale benchmark, there may be biases or inconsistencies in the source material that could affect the validity of the results. The authors acknowledge this and suggest that future work could explore more curated medical datasets.
Additionally, the paper does not delve into the underlying causes of hallucination in the evaluated models. Further research is needed to understand the specific vulnerabilities of these systems and develop more robust approaches to mitigate hallucination, especially in high-stakes domains like healthcare.
Overall, this paper lays important groundwork for the systematic evaluation of hallucination in medical vision-language models, and the MedVH dataset and benchmarks are a valuable resource for the broader research community.
Conclusion
The MedVH: Towards Systematic Evaluation of Hallucination for Large Vision Language Models in the Medical Context paper introduces a new dataset and set of benchmarks for evaluating hallucination in large vision-language models in the medical context. The authors argue that existing hallucination evaluation frameworks do not capture the unique challenges of the medical domain, and they create MedVH to address this gap.
By testing state-of-the-art models on MedVH, the researchers find that these systems struggle to provide accurate and factual responses, particularly on questions that require a deep understanding of medical concepts. This work highlights the need for more specialized benchmarks and advanced techniques to mitigate hallucination, especially in high-stakes domains like healthcare. The MedVH dataset and benchmarks provide a valuable resource for the broader research community to advance the development of reliable and trustworthy vision-language models for medical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MedVH: Towards Systematic Evaluation of Hallucination for Large Vision Language Models in the Medical Context
Zishan Gu, Changchang Yin, Fenglin Liu, Ping Zhang
Large Vision Language Models (LVLMs) have recently achieved superior performance in various tasks on natural image and text data, which inspires a large amount of studies for LVLMs fine-tuning and training. Despite their advancements, there has been scant research on the robustness of these models against hallucination when fine-tuned on smaller datasets. In this study, we introduce a new benchmark dataset, the Medical Visual Hallucination Test (MedVH), to evaluate the hallucination of domain-specific LVLMs. MedVH comprises five tasks to evaluate hallucinations in LVLMs within the medical context, which includes tasks for comprehensive understanding of textual and visual input, as well as long textual response generation. Our extensive experiments with both general and medical LVLMs reveal that, although medical LVLMs demonstrate promising performance on standard medical tasks, they are particularly susceptible to hallucinations, often more so than the general models, raising significant concerns about the reliability of these domain-specific models. For medical LVLMs to be truly valuable in real-world applications, they must not only accurately integrate medical knowledge but also maintain robust reasoning abilities to prevent hallucination. Our work paves the way for future evaluations of these studies.
Read more7/4/2024
0
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, Lihua Zhang
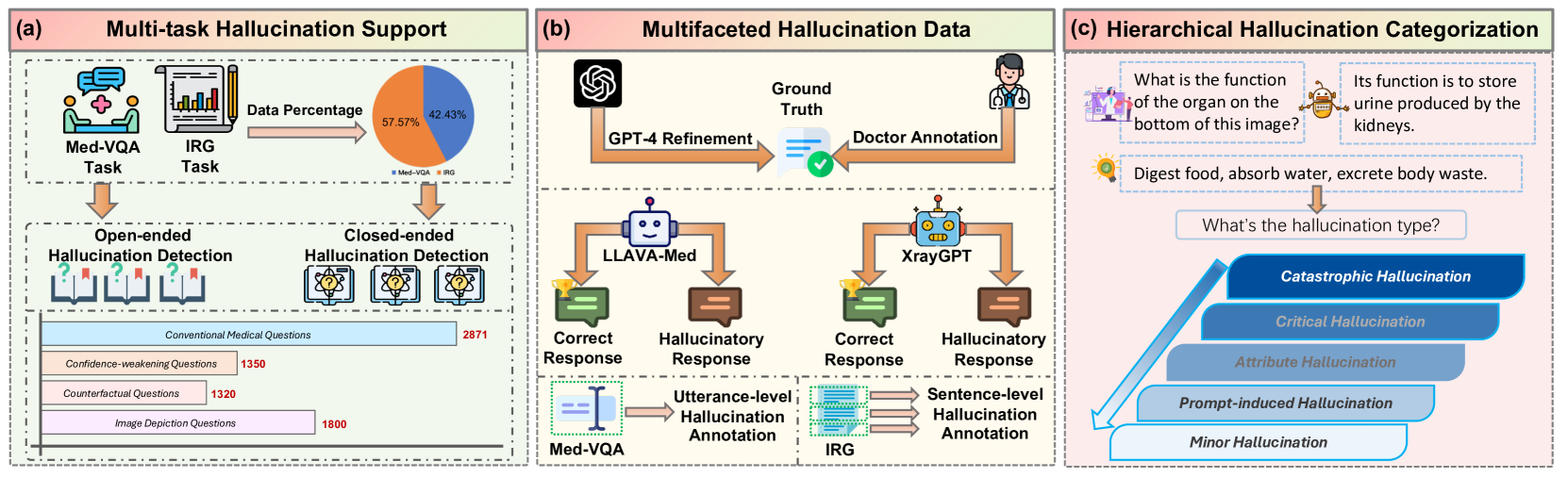
Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.
Read more6/17/2024

0
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Read more5/7/2024

0
MedThink: Inducing Medical Large-scale Visual Language Models to Hallucinate Less by Thinking More
Yue Jiang, Jiawei Chen, Dingkang Yang, Mingcheng Li, Shunli Wang, Tong Wu, Ke Li, Lihua Zhang
When Large Vision Language Models (LVLMs) are applied to multimodal medical generative tasks, they suffer from significant model hallucination issues. This severely impairs the model's generative accuracy, making it challenging for LVLMs to be implemented in real-world medical scenarios to assist doctors in diagnosis. Enhancing the training data for downstream medical generative tasks is an effective way to address model hallucination. Moreover, the limited availability of training data in the medical field and privacy concerns greatly hinder the model's accuracy and generalization capabilities. In this paper, we introduce a method that mimics human cognitive processes to construct fine-grained instruction pairs and apply the concept of chain-of-thought (CoT) from inference scenarios to training scenarios, thereby proposing a method called MedThink. Our experiments on various LVLMs demonstrate that our novel data construction method tailored for the medical domain significantly improves the model's performance in medical image report generation tasks and substantially mitigates the hallucinations. All resources of this work will be released soon.
Read more6/19/2024