MicroEmo: Time-Sensitive Multimodal Emotion Recognition with Micro-Expression Dynamics in Video Dialogues

0
👁️
Sign in to get full access
Overview
- This research paper discusses a novel approach to understanding and recognizing emotions through multimodal data.
- The authors propose a framework that integrates visual, textual, and audio information to enable more comprehensive and accurate emotion recognition.
- Key contributions include the development of a large-scale multimodal emotion dataset and the design of a multi-task learning model for joint emotion classification and reasoning.
Plain English Explanation
The paper presents a new way to recognize and understand emotions by combining different types of data. Traditionally, emotion recognition has relied mostly on analyzing text or visual cues like facial expressions. However, the researchers argue that using multiple modalities - such as text, images, and audio - can provide a richer and more accurate understanding of a person's emotional state.
The core idea is to build a system that can process various types of emotional information from different sources. For example, it could look at the words someone uses, their facial expressions, and the tone of their voice to get a more complete picture of how they are feeling.
To do this, the researchers created a large dataset of emotional information spanning different modalities. They then developed a machine learning model that can learn to analyze this multimodal data and make inferences about a person's emotional state. This allows the system to go beyond simply classifying emotions (like "happy" or "sad") and also reason about the underlying causes and context.
The key benefits of this approach are more nuanced and accurate emotion recognition, as well as the ability to understand the reasons and situation behind a person's emotions. This could have important applications in areas like mental health, human-robot interaction, and customer service.
Technical Explanation
The paper introduces a framework called "EmotionLLaMA" that integrates visual, textual, and audio modalities for comprehensive emotion recognition and reasoning. The authors first construct a large-scale multimodal emotion dataset, EmotionLLaMA, which includes images, text, and audio samples labeled with emotion categories and textual descriptions.
They then propose a multi-task learning model that jointly performs emotion classification and emotion reasoning. The model consists of modality-specific encoders (e.g., visual, textual, audio) that extract features from the input data, which are then fused and passed through a shared prediction head. This allows the model to learn cross-modal relationships and jointly optimize for both emotion classification and reasoning.
The key innovation is the incorporation of reasoning capabilities, where the model not only predicts the emotion category but also generates a textual description explaining the underlying emotional context and causes. This is facilitated by a novel reasoning loss function that encourages the model to produce coherent and meaningful explanations.
The authors evaluate their EmotionLLaMA model on several benchmark datasets and demonstrate its superior performance compared to unimodal and other multimodal baselines. They also present qualitative results showcasing the model's ability to provide insightful explanations for its emotion predictions.
Critical Analysis
The research presented in this paper addresses an important challenge in emotion recognition by leveraging multimodal data and incorporating reasoning capabilities. The authors' approach of jointly learning emotion classification and reasoning is a promising direction that can lead to more comprehensive and explainable emotion understanding systems.
One key strength of the paper is the creation of the EmotionLLaMA dataset, which provides a valuable resource for the research community. The dataset's scale and coverage of different modalities are likely to spur further advancements in this area.
However, the paper also acknowledges several limitations and areas for future work. For example, the current model is limited to predicting discrete emotion categories, and the reasoning capabilities could be further enhanced to handle more complex emotional states and contexts. Additionally, the authors note that the performance of the model may be dependent on the quality and diversity of the training data, which could be an area for improvement.
Further research could explore ways to make the emotion recognition and reasoning more robust, personalized, and applicable to real-world scenarios. Investigating the ethical implications of such systems, particularly around privacy and potential biases, would also be an important consideration.
Conclusion
This paper presents a novel multimodal framework for emotion recognition and reasoning, which combines visual, textual, and audio information to enable more comprehensive and explainable emotion understanding. The authors' key contributions include the creation of a large-scale multimodal emotion dataset and the development of a multi-task learning model that jointly performs emotion classification and reasoning.
The proposed approach represents a significant advancement in the field of emotion recognition and has the potential to impact various application domains, such as mental health, human-robot interaction, and customer service. By incorporating reasoning capabilities, the EmotionLLaMA model can provide deeper insights into the emotional states of individuals, leading to more nuanced and context-aware emotional understanding.
While the paper highlights several promising aspects of the research, it also identifies areas for further exploration, such as enhancing the model's handling of complex emotional states and addressing potential biases in the training data. As the field of multimodal emotion recognition continues to evolve, this work serves as an important step towards more robust and explainable emotion understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
MicroEmo: Time-Sensitive Multimodal Emotion Recognition with Micro-Expression Dynamics in Video Dialogues
Liyun Zhang
Multimodal Large Language Models (MLLMs) have demonstrated remarkable multimodal emotion recognition capabilities, integrating multimodal cues from visual, acoustic, and linguistic contexts in the video to recognize human emotional states. However, existing methods ignore capturing local facial features of temporal dynamics of micro-expressions and do not leverage the contextual dependencies of the utterance-aware temporal segments in the video, thereby limiting their expected effectiveness to a certain extent. In this work, we propose MicroEmo, a time-sensitive MLLM aimed at directing attention to the local facial micro-expression dynamics and the contextual dependencies of utterance-aware video clips. Our model incorporates two key architectural contributions: (1) a global-local attention visual encoder that integrates global frame-level timestamp-bound image features with local facial features of temporal dynamics of micro-expressions; (2) an utterance-aware video Q-Former that captures multi-scale and contextual dependencies by generating visual token sequences for each utterance segment and for the entire video then combining them. Preliminary qualitative experiments demonstrate that in a new Explainable Multimodal Emotion Recognition (EMER) task that exploits multi-modal and multi-faceted clues to predict emotions in an open-vocabulary (OV) manner, MicroEmo demonstrates its effectiveness compared with the latest methods.
Read more7/25/2024
0
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
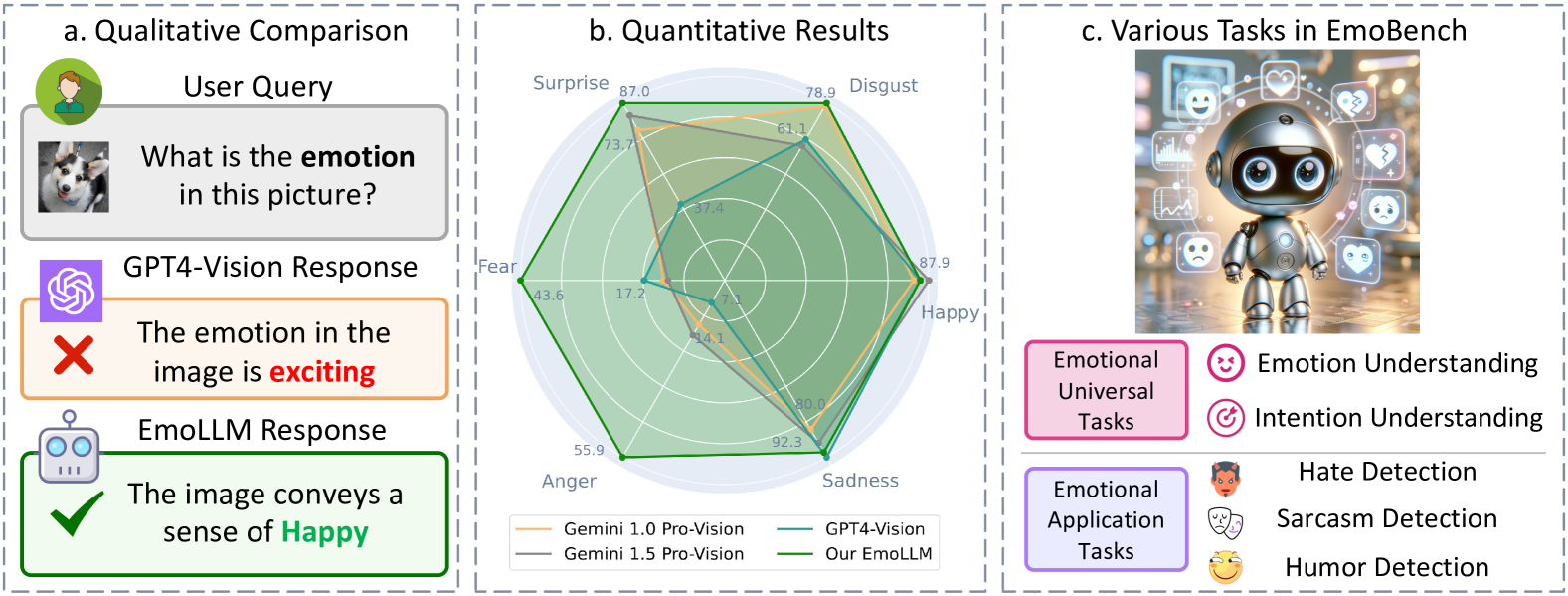
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
Read more7/2/2024
👁️
0
Video Emotion Open-vocabulary Recognition Based on Multimodal Large Language Model
Mengying Ge, Dongkai Tang, Mingyang Li
Multimodal emotion recognition is a task of great concern. However, traditional data sets are based on fixed labels, resulting in models that often focus on main emotions and ignore detailed emotional changes in complex scenes. This report introduces the solution of using MLLMs technology to generate open-vocabulary emotion labels from a video. The solution includes the use of framework, data generation and processing, training methods, results generation and multi-model co-judgment. In the MER-OV (Open-Word Emotion Recognition) of the MER2024 challenge, our method achieved significant advantages, leading to its superior capabilities in complex emotion computation.
Read more8/23/2024

4
EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Linrui Tian, Qi Wang, Bang Zhang, Liefeng Bo
In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
Read more8/7/2024