MIDGARD: Self-Consistency Using Minimum Description Length for Structured Commonsense Reasoning

0
🚀
Sign in to get full access
Overview
- The paper explores the task of conducting structured reasoning by generating a reasoning graph from natural language input using large language models (LLMs).
- Previous approaches have suffered from error propagation due to the autoregressive nature and single-pass-based decoding, which lack error correction capability.
- The paper proposes a new method called MIDGARD (MInimum Description length Guided Aggregation of Reasoning in Directed acyclic graph) that leverages Minimum Description Length (MDL)-based formulation to identify consistent properties among different graph samples generated by an LLM.
- The method demonstrates superior performance compared to other approaches across various structured reasoning tasks.
Plain English Explanation
Large language models (LLMs) are powerful tools that can understand and generate human-like text. Researchers have explored using LLMs to perform structured reasoning, where the goal is to extract a graph-like representation of the reasoning process from natural language input.
Previous methods for this task have had some issues. They often generate reasoning graphs in a single pass, which can lead to errors that build up and get worse as the graph is created. Additionally, relying on just a single sample of the reasoning graph can cause important elements to be missed.
To address these problems, the researchers in this paper draw inspiration from a technique called "self-consistency" (SC). SC involves generating multiple samples of the reasoning graph and then combining them to get a more accurate final result.
The key innovation in this paper is a new method called MIDGARD that uses a mathematical technique called "Minimum Description Length" (MDL) to identify the most consistent elements across the different graph samples. This helps filter out parts of the graph that are likely to be incorrect, while also filling in missing elements without compromising the overall accuracy.
The researchers show that MIDGARD outperforms other methods across a variety of structured reasoning tasks, such as argument structure extraction, explanation graph generation, and inferring dependencies among actions for everyday tasks. This suggests that their approach is a promising way to enable LLMs to engage in more robust and reliable structured reasoning.
Technical Explanation
The paper tackles the challenge of conducting structured reasoning using large language models (LLMs). The goal is to generate a reasoning graph, which is a graphical representation of the reasoning process, from natural language input.
Previous approaches have explored various prompting schemes, but they suffer from error propagation due to the autoregressive nature and single-pass-based decoding of LLMs. This means that mistakes made early in the process can get amplified as the reasoning graph is constructed, and the models lack the ability to correct these errors.
To address this, the researchers draw inspiration from the concept of self-consistency (SC), which involves generating multiple samples of the reasoning graph and then combining them to get a more accurate final result. However, applying SC to generated graphs poses a substantial challenge.
The researchers propose a new method called MIDGARD (MInimum Description length Guided Aggregation of Reasoning in Directed acyclic graph) that leverages Minimum Description Length (MDL) to identify consistent properties among the different graph samples. The MDL-based formulation helps reject properties that appear in only a few samples, which are likely to be erroneous, while enabling the inclusion of missing elements without compromising precision.
The experimental results show that MIDGARD outperforms other methods across a range of structured reasoning tasks, including argument structure extraction, explanation graph generation, inferring dependency relations among actions for everyday tasks, and semantic graph generation from natural texts.
Critical Analysis
The paper presents a promising approach to enabling large language models (LLMs) to perform more robust and reliable structured reasoning. The MIDGARD method's ability to identify consistent properties across multiple graph samples and filter out likely erroneous elements is a significant advancement over previous techniques.
However, the paper does not discuss the computational complexity and scalability of the MIDGARD approach. As the size and complexity of the reasoning graphs increase, the process of aggregating and analyzing multiple samples could become computationally intensive. The researchers may need to explore ways to optimize the algorithm or develop approximation techniques to make the method more practical for larger-scale applications.
Additionally, the paper focuses on evaluating MIDGARD on specific structured reasoning tasks, but it does not provide a broader analysis of its generalization capabilities. It would be valuable to understand how well the method performs on a wider range of reasoning tasks and whether the benefits observed in the reported experiments extend to other domains.
Finally, the paper does not delve into the potential biases or limitations of the LLMs used in the MIDGARD framework. As with any machine learning-based approach, it is essential to consider the potential for these models to perpetuate or amplify societal biases present in the training data. Further research may be needed to investigate the fairness and robustness of the MIDGARD method in real-world applications.
Conclusion
The paper presents a novel approach called MIDGARD that addresses the limitations of previous methods for conducting structured reasoning using large language models (LLMs). By leveraging Minimum Description Length (MDL) to identify consistent properties across multiple graph samples, MIDGARD demonstrates superior performance on a variety of structured reasoning tasks, including argument structure extraction, explanation graph generation, and semantic graph generation.
This research represents a significant step forward in enabling LLMs to engage in more robust and reliable structured reasoning, which has important implications for a wide range of applications, such as knowledge-guided decision making, language understanding, and task planning. While the paper raises some questions about the scalability and generalization of the MIDGARD approach, the overall findings suggest that this is a promising direction for further research and development in the field of structured reasoning with large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
MIDGARD: Self-Consistency Using Minimum Description Length for Structured Commonsense Reasoning
Inderjeet Nair, Lu Wang
We study the task of conducting structured reasoning as generating a reasoning graph from natural language input using large language models (LLMs). Previous approaches have explored various prompting schemes, yet they suffer from error propagation due to the autoregressive nature and single-pass-based decoding, which lack error correction capability. Additionally, relying solely on a single sample may result in the omission of true nodes and edges. To counter this, we draw inspiration from self-consistency (SC), which involves sampling a diverse set of reasoning chains and taking the majority vote as the final answer. To tackle the substantial challenge of applying SC on generated graphs, we propose MIDGARD (MInimum Description length Guided Aggregation of Reasoning in Directed acyclic graph) that leverages Minimum Description Length (MDL)-based formulation to identify consistent properties among the different graph samples generated by an LLM. This formulation helps reject properties that appear in only a few samples, which are likely to be erroneous, while enabling the inclusion of missing elements without compromising precision. Our method demonstrates superior performance than comparisons across various structured reasoning tasks, including argument structure extraction, explanation graph generation, inferring dependency relations among actions for everyday tasks, and semantic graph generation from natural texts.
Read more6/4/2024

0
MAGDi: Structured Distillation of Multi-Agent Interaction Graphs Improves Reasoning in Smaller Language Models
Justin Chih-Yao Chen, Swarnadeep Saha, Elias Stengel-Eskin, Mohit Bansal
Multi-agent interactions between Large Language Model (LLM) agents have shown major improvements on diverse reasoning tasks. However, these involve long generations from multiple models across several rounds, making them expensive. Moreover, these multi-agent approaches fail to provide a final, single model for efficient inference. To address this, we introduce MAGDi, a new method for structured distillation of the reasoning interactions between multiple LLMs into smaller LMs. MAGDi teaches smaller models by representing multi-agent interactions as graphs, augmenting a base student model with a graph encoder, and distilling knowledge using three objective functions: next-token prediction, a contrastive loss between correct and incorrect reasoning, and a graph-based objective to model the interaction structure. Experiments on seven widely used commonsense and math reasoning benchmarks show that MAGDi improves the reasoning capabilities of smaller models, outperforming several methods that distill from a single teacher and multiple teachers. Moreover, MAGDi also demonstrates an order of magnitude higher efficiency over its teachers. We conduct extensive analyses to show that MAGDi (1) enhances the generalizability to out-of-domain tasks, (2) scales positively with the size and strength of the base student model, and (3) obtains larger improvements (via our multi-teacher training) when applying self-consistency -- an inference technique that relies on model diversity.
Read more6/11/2024

0
Dynamic Self-Consistency: Leveraging Reasoning Paths for Efficient LLM Sampling
Guangya Wan, Yuqi Wu, Jie Chen, Sheng Li
Self-Consistency (SC) is a widely used method to mitigate hallucinations in Large Language Models (LLMs) by sampling the LLM multiple times and outputting the most frequent solution. Despite its benefits, SC results in significant computational costs proportional to the number of samples generated. Previous early-stopping approaches, such as Early Stopping Self Consistency and Adaptive Consistency, have aimed to reduce these costs by considering output consistency, but they do not analyze the quality of the reasoning paths (RPs) themselves. To address this issue, we propose Reasoning-Aware Self-Consistency (RASC), an innovative early-stopping framework that dynamically adjusts the number of sample generations by considering both the output answer and the RPs from Chain of Thought (CoT) prompting. RASC assigns confidence scores sequentially to the generated samples, stops when certain criteria are met, and then employs weighted majority voting to optimize sample usage and enhance answer reliability. We comprehensively test RASC with multiple LLMs across varied QA datasets. RASC outperformed existing methods and significantly reduces sample usage by an average of 80% while maintaining or improving accuracy up to 5% compared to the original SC
Read more9/2/2024
0
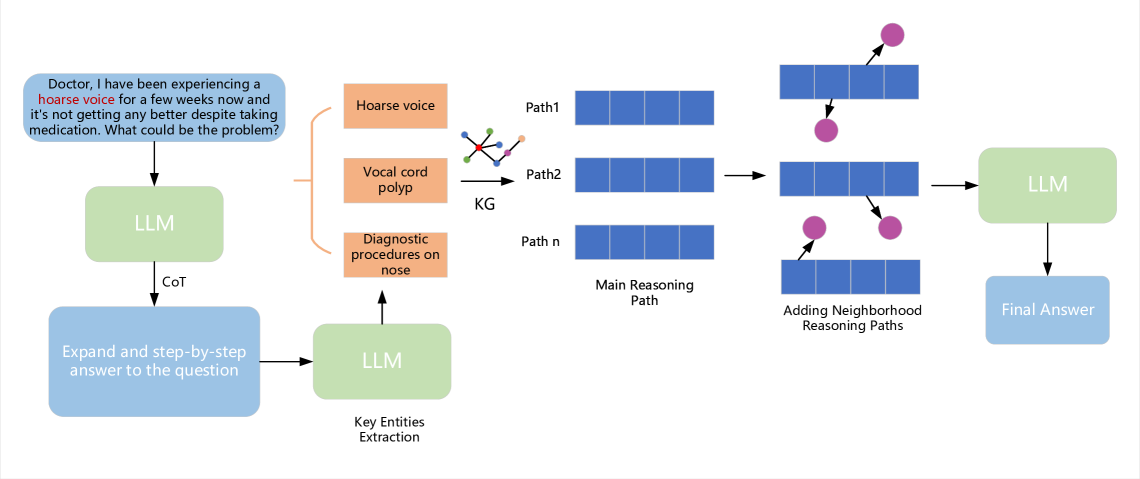
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
Read more4/17/2024