Mind the Model, Not the Agent: The Primacy Bias in Model-based RL

0
🏋️
Sign in to get full access
Overview
- The paper explores the primacy bias in model-based reinforcement learning (MBRL), which is the tendency of an agent to overfit early data and struggle to learn from new information.
- The researchers find that a simple technique called "world model resetting" can effectively mitigate the primacy bias in MBRL, unlike in the model-free setting where parameter resetting works better.
- The paper applies this method to two different MBRL algorithms, MBPO and DreamerV2, and evaluates it on various continuous control and discrete control tasks.
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or punishments. In model-free reinforcement learning, the agent directly learns the optimal actions to take, while in model-based reinforcement learning, the agent first learns a model of the environment and then uses that model to plan its actions.
One problem that can arise in reinforcement learning is the "primacy bias," where the agent tends to overfit to the initial data it sees and has difficulty learning from new information. Previous research has shown that for model-free reinforcement learning, you can mitigate this primacy bias by "resetting" the agent's parameters, essentially forcing it to start over and learn from scratch.
However, the researchers in this paper find that this parameter resetting approach doesn't work as well for model-based reinforcement learning. Instead, they discover that the primacy bias in MBRL is more closely tied to the model of the environment, rather than the agent itself. To address this, they propose a technique called "world model resetting," where the agent's model of the environment is reset, rather than the agent's parameters.
By applying world model resetting to two different MBRL algorithms, the researchers show that it can significantly improve the algorithms' performance and help them overcome the primacy bias. This is an important finding, as the primacy bias can seriously degrade the performance of MBRL systems in the real world.
Technical Explanation
The researchers begin by observing that resetting the agent's parameters, which is an effective technique for mitigating the primacy bias in model-free reinforcement learning, actually harms the performance of MBRL algorithms. This led them to investigate the nature of the primacy bias in MBRL more closely.
Through their analysis, the researchers find that the primacy bias in MBRL is more closely related to the primacy bias of the world model, which is the agent's internal representation of the environment, rather than the primacy bias of the agent itself. Based on this insight, they propose a technique called "world model resetting," where the agent's world model is reset periodically to prevent it from overfitting to the initial data.
The researchers evaluate their world model resetting approach on two different MBRL algorithms, MBPO and DreamerV2, across a variety of continuous control tasks on MuJoCo and discrete control tasks on the Atari 100k benchmark. The results show that world model resetting can significantly improve the performance of these MBRL algorithms by alleviating the primacy bias.
The paper also provides a guide on how to effectively implement world model resetting, including details on the hyperparameters and implementation details.
Critical Analysis
One potential limitation of the research is that it only explores the primacy bias in the context of MBRL and does not directly compare it to the primacy bias in model-free reinforcement learning. While the researchers cite previous work on mitigating the primacy bias in MFRL, a more direct comparison could have provided additional insights.
Additionally, the paper does not delve into the specific mechanisms by which the primacy bias arises in the world model, nor does it explore potential alternative techniques for addressing this issue beyond the world model resetting approach. Further research in these areas could lead to a deeper understanding of the primacy bias in MBRL.
Overall, the paper presents a novel and valuable contribution to the field of reinforcement learning by shedding light on the primacy bias in the model-based setting and proposing an effective solution to mitigate it. The findings have important implications for improving the real-world performance of MBRL systems.
Conclusion
This paper explores the primacy bias, a common issue in reinforcement learning where an agent tends to overfit to early data and struggle to learn from new information, in the context of model-based reinforcement learning (MBRL). The researchers find that the primacy bias in MBRL is more closely related to the agent's model of the environment, rather than the agent itself.
Based on this insight, the researchers propose a technique called "world model resetting," which effectively mitigates the primacy bias in MBRL. By applying this method to two different MBRL algorithms, they demonstrate significant performance improvements across a variety of continuous control and discrete control tasks.
The findings in this paper have important implications for improving the real-world applicability of MBRL systems, as the primacy bias can seriously degrade their performance. The world model resetting approach provides a simple yet effective solution to this problem, paving the way for more robust and reliable MBRL algorithms in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Mind the Model, Not the Agent: The Primacy Bias in Model-based RL
Zhongjian Qiao, Jiafei Lyu, Xiu Li
The primacy bias in model-free reinforcement learning (MFRL), which refers to the agent's tendency to overfit early data and lose the ability to learn from new data, can significantly decrease the performance of MFRL algorithms. Previous studies have shown that employing simple techniques, such as resetting the agent's parameters, can substantially alleviate the primacy bias in MFRL. However, the primacy bias in model-based reinforcement learning (MBRL) remains unexplored. In this work, we focus on investigating the primacy bias in MBRL. We begin by observing that resetting the agent's parameters harms its performance in the context of MBRL. We further find that the primacy bias in MBRL is more closely related to the primacy bias of the world model instead of the primacy bias of the agent. Based on this finding, we propose textit{world model resetting}, a simple yet effective technique to alleviate the primacy bias in MBRL. We apply our method to two different MBRL algorithms, MBPO and DreamerV2. We validate the effectiveness of our method on multiple continuous control tasks on MuJoCo and DeepMind Control Suite, as well as discrete control tasks on Atari 100k benchmark. The experimental results show that textit{world model resetting} can significantly alleviate the primacy bias in the model-based setting and improve the algorithm's performance. We also give a guide on how to perform textit{world model resetting} effectively.
Read more8/20/2024

0
World Models Increase Autonomy in Reinforcement Learning
Zhao Yang, Thomas M. Moerland, Mike Preuss, Aske Plaat, Edward S. Hu
Reinforcement learning (RL) is an appealing paradigm for training intelligent agents, enabling policy acquisition from the agent's own autonomously acquired experience. However, the training process of RL is far from automatic, requiring extensive human effort to reset the agent and environments. To tackle the challenging reset-free setting, we first demonstrate the superiority of model-based (MB) RL methods in such setting, showing that a straightforward adaptation of MBRL can outperform all the prior state-of-the-art methods while requiring less supervision. We then identify limitations inherent to this direct extension and propose a solution called model-based reset-free (MoReFree) agent, which further enhances the performance. MoReFree adapts two key mechanisms, exploration and policy learning, to handle reset-free tasks by prioritizing task-relevant states. It exhibits superior data-efficiency across various reset-free tasks without access to environmental reward or demonstrations while significantly outperforming privileged baselines that require supervision. Our findings suggest model-based methods hold significant promise for reducing human effort in RL. Website: https://sites.google.com/view/morefree
Read more8/21/2024
🐍
0
Confronting Reward Overoptimization for Diffusion Models: A Perspective of Inductive and Primacy Biases
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Bridging the gap between diffusion models and human preferences is crucial for their integration into practical generative workflows. While optimizing downstream reward models has emerged as a promising alignment strategy, concerns arise regarding the risk of excessive optimization with learned reward models, which potentially compromises ground-truth performance. In this work, we confront the reward overoptimization problem in diffusion model alignment through the lenses of both inductive and primacy biases. We first identify a mismatch between current methods and the temporal inductive bias inherent in the multi-step denoising process of diffusion models, as a potential source of reward overoptimization. Then, we surprisingly discover that dormant neurons in our critic model act as a regularization against reward overoptimization while active neurons reflect primacy bias. Motivated by these observations, we propose Temporal Diffusion Policy Optimization with critic active neuron Reset (TDPO-R), a policy gradient algorithm that exploits the temporal inductive bias of diffusion models and mitigates the primacy bias stemming from active neurons. Empirical results demonstrate the superior efficacy of our methods in mitigating reward overoptimization. Code is avaliable at https://github.com/ZiyiZhang27/tdpo.
Read more6/6/2024
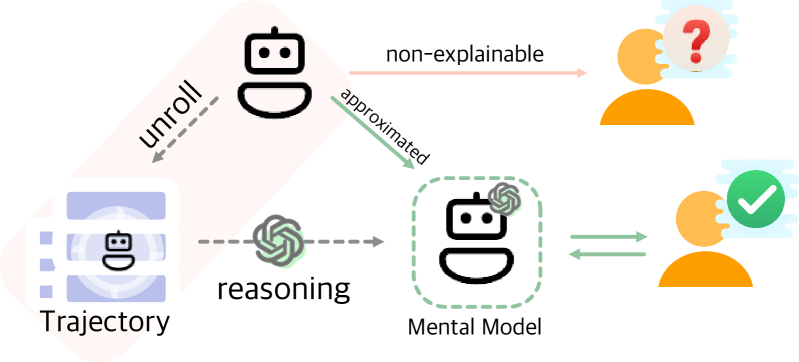
0
Mental Modeling of Reinforcement Learning Agents by Language Models
Wenhao Lu, Xufeng Zhao, Josua Spisak, Jae Hee Lee, Stefan Wermter
Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
Read more6/27/2024