MiniGPT-Reverse-Designing: Predicting Image Adjustments Utilizing MiniGPT-4

0

Sign in to get full access
Overview
- Presents a novel method called "MiniGPT-Reverse-Designing" that utilizes the MiniGPT-4 model to predict image adjustments
- Aims to enable more efficient image editing by predicting the adjustments needed to achieve a desired visual effect
- Builds on recent advancements in large language models and multimodal machine learning
Plain English Explanation
This research proposes a new technique called "MiniGPT-Reverse-Designing" that leverages the power of the MiniGPT-4 model to predict the adjustments needed to modify an image in a desired way. The key idea is to use the language understanding capabilities of large language models, combined with visual information, to determine the specific changes that should be made to an image to achieve a particular look or effect.
For example, if you wanted to make an image look more vibrant and colorful, the model could analyze the image and predict the adjustments (e.g., increasing saturation, adjusting the hue, etc.) that would be needed to produce that result. This could streamline the image editing process and make it more accessible to a wider range of users.
The researchers build on recent advancements in the field of multimodal machine learning, which involves training models to understand and generate both language and visual data. By leveraging these powerful models, the "MiniGPT-Reverse-Designing" approach aims to provide a more efficient and intuitive way to edit and manipulate images.
Technical Explanation
The core of the "MiniGPT-Reverse-Designing" method is the use of the MiniGPT-4 model, which is a large language model with strong multimodal capabilities. The researchers fine-tune this model on a dataset of image-adjustment pairs, where each image is accompanied by the specific adjustments (e.g., changes to brightness, contrast, color balance, etc.) that were made to it.
During the training process, the model learns to associate visual features of the images with the corresponding adjustment operations. Once trained, the model can then be used to predict the adjustments needed to modify a new input image in a desired way, based on natural language descriptions provided by the user.
The researchers also explore ways to further improve the model's performance, such as incorporating additional visual information (e.g., from TinyGPT-V or BlenderAlchemy) and leveraging techniques like vision-language modeling.
Critical Analysis
The paper presents a promising approach for streamlining image editing, but it also acknowledges several limitations and areas for further research. One key challenge is the potential for the model to make inaccurate predictions, especially for complex or subtle image adjustments. The researchers suggest that incorporating more detailed visual information and expanding the training dataset could help improve the model's performance.
Additionally, the paper does not explore the potential biases or fairness issues that could arise from the model's predictions, which is an important consideration for any AI system that is intended to be used by a wide range of users. Further research is needed to understand the model's behavior and ensure that it does not perpetuate or amplify harmful biases.
Another area for improvement is the model's interpretability – it would be valuable to provide users with a better understanding of the reasoning behind the model's predictions, to build trust and enable more informed decision-making during the image editing process.
Conclusion
The "MiniGPT-Reverse-Designing" method represents an exciting step forward in the field of image editing, leveraging the power of large language models and multimodal machine learning to streamline the process of modifying images. By predicting the necessary adjustments based on natural language descriptions, this approach has the potential to make image editing more accessible and efficient for a wide range of users.
However, the research also highlights the need for continued development and careful consideration of the potential limitations and ethical implications of such systems. As the field of AI and machine learning continues to advance, it will be important to address these challenges and ensure that these technologies are deployed in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MiniGPT-Reverse-Designing: Predicting Image Adjustments Utilizing MiniGPT-4
Vahid Azizi, Fatemeh Koochaki
Vision-Language Models (VLMs) have recently seen significant advancements through integrating with Large Language Models (LLMs). The VLMs, which process image and text modalities simultaneously, have demonstrated the ability to learn and understand the interaction between images and texts across various multi-modal tasks. Reverse designing, which could be defined as a complex vision-language task, aims to predict the edits and their parameters, given a source image, an edited version, and an optional high-level textual edit description. This task requires VLMs to comprehend the interplay between the source image, the edited version, and the optional textual context simultaneously, going beyond traditional vision-language tasks. In this paper, we extend and fine-tune MiniGPT-4 for the reverse designing task. Our experiments demonstrate the extensibility of off-the-shelf VLMs, specifically MiniGPT-4, for more complex tasks such as reverse designing. Code is available at this href{https://github.com/VahidAz/MiniGPT-Reverse-Designing}
Read more9/2/2024
0
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
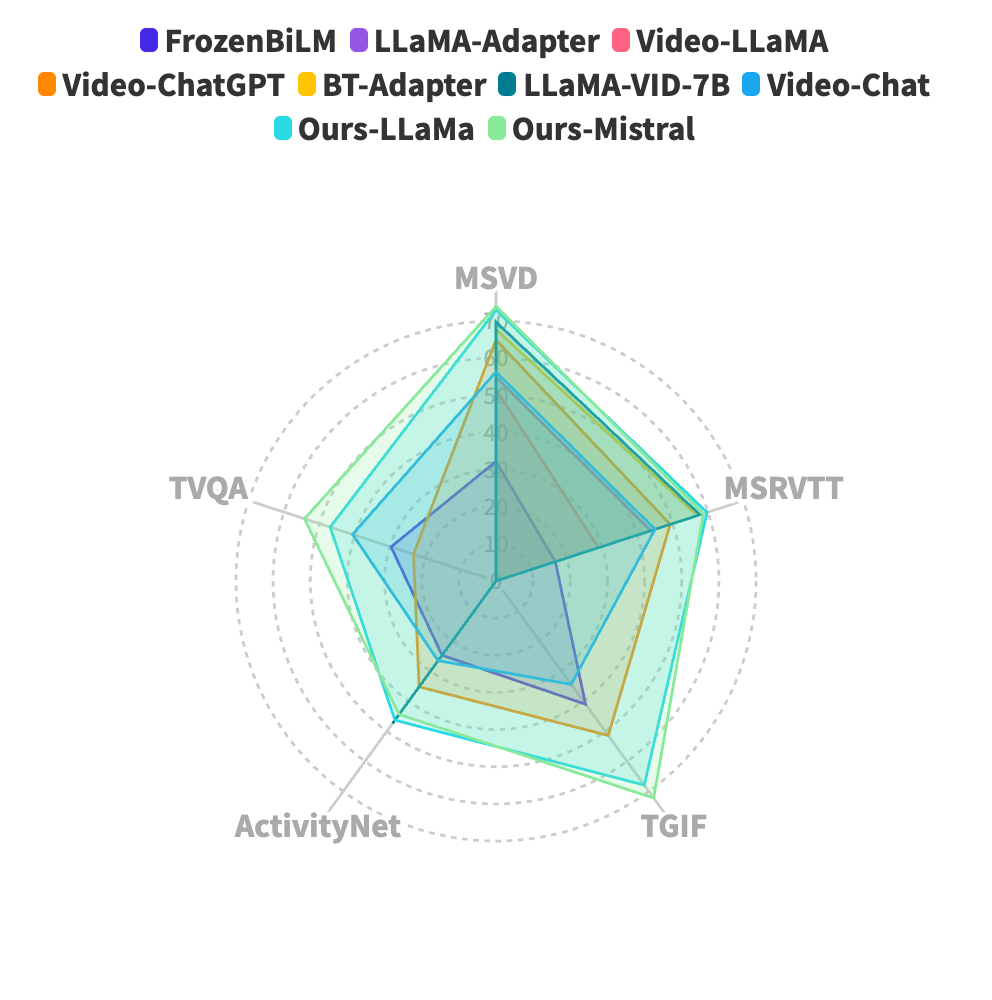
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
Read more4/5/2024

0
Exploiting LMM-based knowledge for image classification tasks
Maria Tzelepi, Vasileios Mezaris
In this paper we address image classification tasks leveraging knowledge encoded in Large Multimodal Models (LMMs). More specifically, we use the MiniGPT-4 model to extract semantic descriptions for the images, in a multimodal prompting fashion. In the current literature, vision language models such as CLIP, among other approaches, are utilized as feature extractors, using only the image encoder, for solving image classification tasks. In this paper, we propose to additionally use the text encoder to obtain the text embeddings corresponding to the MiniGPT-4-generated semantic descriptions. Thus, we use both the image and text embeddings for solving the image classification task. The experimental evaluation on three datasets validates the improved classification performance achieved by exploiting LMM-based knowledge.
Read more6/6/2024
0
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in the supplementary material.
Read more6/24/2024