MFC-Bench: Benchmarking Multimodal Fact-Checking with Large Vision-Language Models

0

Sign in to get full access
Overview
• This paper introduces MFC-Bench, a new benchmark for evaluating multimodal fact-checking with large vision-language models.
• The benchmark includes a diverse dataset of claims, images, and annotations for assessing the performance of models in verifying the truthfulness of claims based on both textual and visual information.
• The paper presents baseline results using state-of-the-art vision-language models and highlights key challenges and opportunities for advancing multimodal fact-checking research.
Plain English Explanation
MFC-Bench is a new dataset and benchmark for testing the ability of AI models to fact-check claims using both text and images. The goal is to develop systems that can analyze a statement or claim and determine if it is true or false, based on the accompanying visual information.
The dataset contains a diverse collection of claims, along with relevant images and annotations about the truthfulness of each claim. Researchers can use this benchmark to evaluate how well different AI models perform at this multimodal fact-checking task. The paper provides baseline results using some of the latest vision-language models, showing both the progress made in this area and the challenges that still remain.
By creating a standardized benchmark, the researchers hope to spur further advancements in developing AI systems that can effectively combine textual and visual information to assess the veracity of online content. This could be an important tool for combating the spread of misinformation, which is often amplified through the use of misleading images and claims.
Technical Explanation
The MFC-Bench dataset was constructed by collecting claims from various sources, such as fact-checking websites and social media. These claims were then paired with relevant images and annotated by human raters as either true, false, or partially true/false. The dataset covers a wide range of topics, including politics, science, health, and current events.
To establish baseline performance, the authors evaluated several state-of-the-art vision-language models on the MFC-Bench dataset, including CLIP, VisualBERT, and ALBEF. The models were fine-tuned on the MFC-Bench training data and their performance was assessed on the test set.
The results showed that while the vision-language models were able to achieve reasonable accuracy on the task, there is still significant room for improvement. The models struggled with certain types of claims, particularly those involving subtle nuances or requiring a deeper understanding of the context. The authors also noted that the performance of the models varied depending on the specific architectural choices and training approaches used.
Critical Analysis
The MFC-Bench dataset and benchmark represent an important step forward in the field of multimodal fact-checking. By providing a standardized dataset and evaluation framework, the authors have created a valuable resource for researchers to assess the capabilities of their models and identify areas for further development.
One potential limitation of the dataset is the subjectivity inherent in the human annotation process. While the authors aimed to ensure consistent and reliable annotations, there may still be some degree of disagreement or bias in how certain claims are labeled. Additionally, the dataset may not fully capture the nuances and complexities of real-world misinformation, which can often involve subtle contextual cues and evolving narratives.
Furthermore, the baseline results presented in the paper suggest that current vision-language models still struggle with certain aspects of multimodal fact-checking, such as understanding the subtle implications of claims or integrating contextual information. Addressing these challenges will likely require advancements in areas like commonsense reasoning, knowledge representation, and multimodal reasoning.
Conclusion
The MFC-Bench dataset and benchmark represent an important step forward in the development of AI systems capable of effectively verifying the truthfulness of online content. By providing a standardized evaluation framework, the authors have created a valuable resource for researchers to assess the capabilities of their models and identify areas for further improvement.
The baseline results presented in the paper highlight both the progress made in multimodal fact-checking and the significant challenges that still remain. Addressing these challenges will likely require advancements in areas like commonsense reasoning, knowledge representation, and multimodal reasoning, as well as the continued development of large-scale vision-language models.
Overall, the MFC-Bench benchmark represents an important contribution to the field of AI-powered fact-checking and could have significant implications for combating the spread of online misinformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MFC-Bench: Benchmarking Multimodal Fact-Checking with Large Vision-Language Models
Shengkang Wang, Hongzhan Lin, Ziyang Luo, Zhen Ye, Guang Chen, Jing Ma
Large vision-language models (LVLMs) have significantly improved multimodal reasoning tasks, such as visual question answering and image captioning. These models embed multimodal facts within their parameters, rather than relying on external knowledge bases to store factual information explicitly. However, the content discerned by LVLMs may deviate from actual facts due to inherent bias or incorrect inference. To address this issue, we introduce MFC-Bench, a rigorous and comprehensive benchmark designed to evaluate the factual accuracy of LVLMs across three tasks: Manipulation, Out-of-Context, and Veracity Classification. Through our evaluation on MFC-Bench, we benchmarked 12 diverse and representative LVLMs, uncovering that current models still fall short in multimodal fact-checking and demonstrate insensitivity to various forms of manipulated content. We hope that MFC-Bench could raise attention to the trustworthy artificial intelligence potentially assisted by LVLMs in the future. The MFC-Bench and accompanying resources are publicly accessible at https://github.com/wskbest/MFC-Bench, contributing to ongoing research in the multimodal fact-checking field.
Read more6/18/2024

0
Multimodal Large Language Models to Support Real-World Fact-Checking
Jiahui Geng, Yova Kementchedjhieva, Preslav Nakov, Iryna Gurevych
Multimodal large language models (MLLMs) carry the potential to support humans in processing vast amounts of information. While MLLMs are already being used as a fact-checking tool, their abilities and limitations in this regard are understudied. Here is aim to bridge this gap. In particular, we propose a framework for systematically assessing the capacity of current multimodal models to facilitate real-world fact-checking. Our methodology is evidence-free, leveraging only these models' intrinsic knowledge and reasoning capabilities. By designing prompts that extract models' predictions, explanations, and confidence levels, we delve into research questions concerning model accuracy, robustness, and reasons for failure. We empirically find that (1) GPT-4V exhibits superior performance in identifying malicious and misleading multimodal claims, with the ability to explain the unreasonable aspects and underlying motives, and (2) existing open-source models exhibit strong biases and are highly sensitive to the prompt. Our study offers insights into combating false multimodal information and building secure, trustworthy multimodal models. To the best of our knowledge, we are the first to evaluate MLLMs for real-world fact-checking.
Read more4/29/2024
0
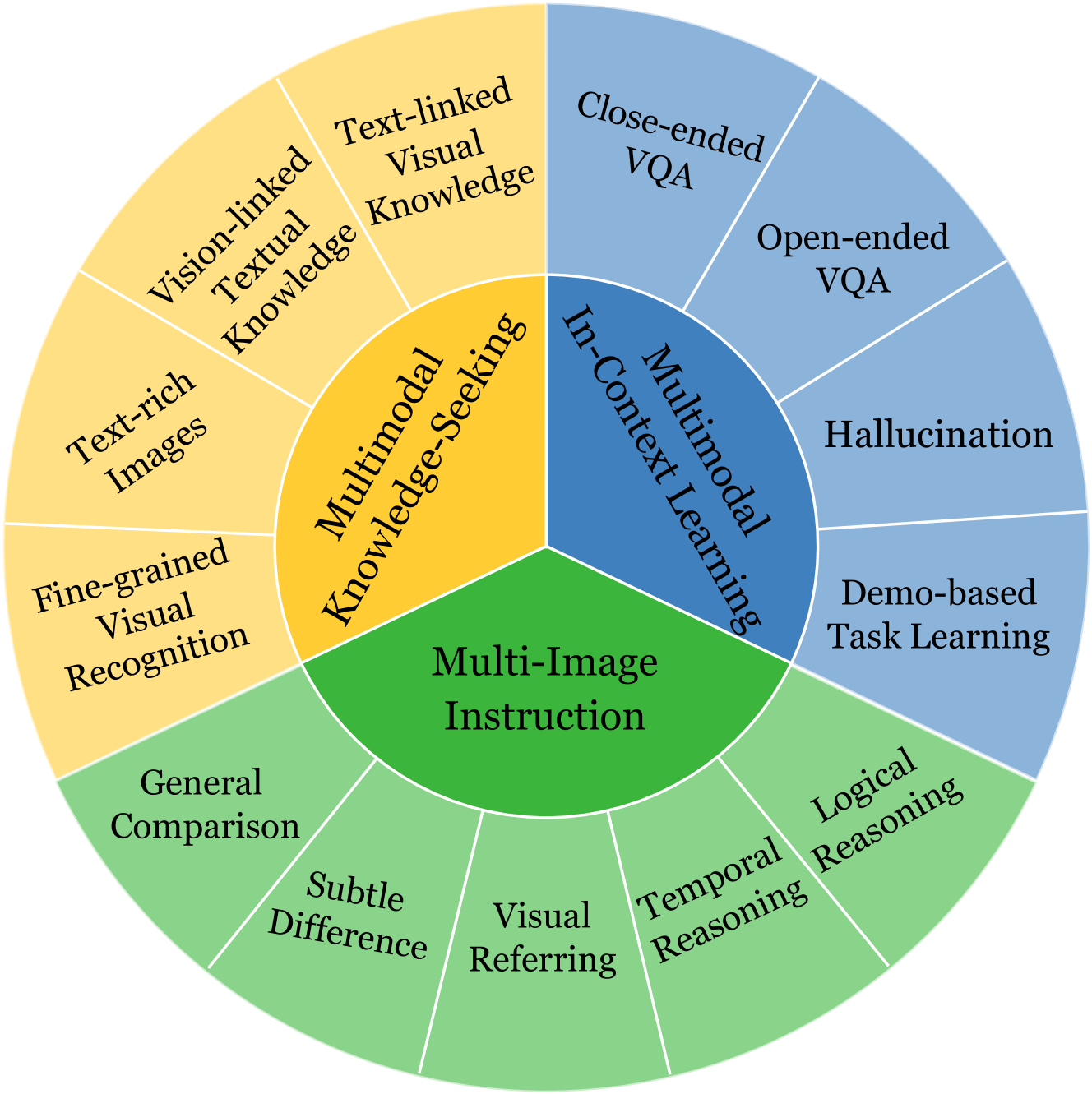
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024