MMoFusion: Multi-modal Co-Speech Motion Generation with Diffusion Model
2403.02905
0
0
Abstract
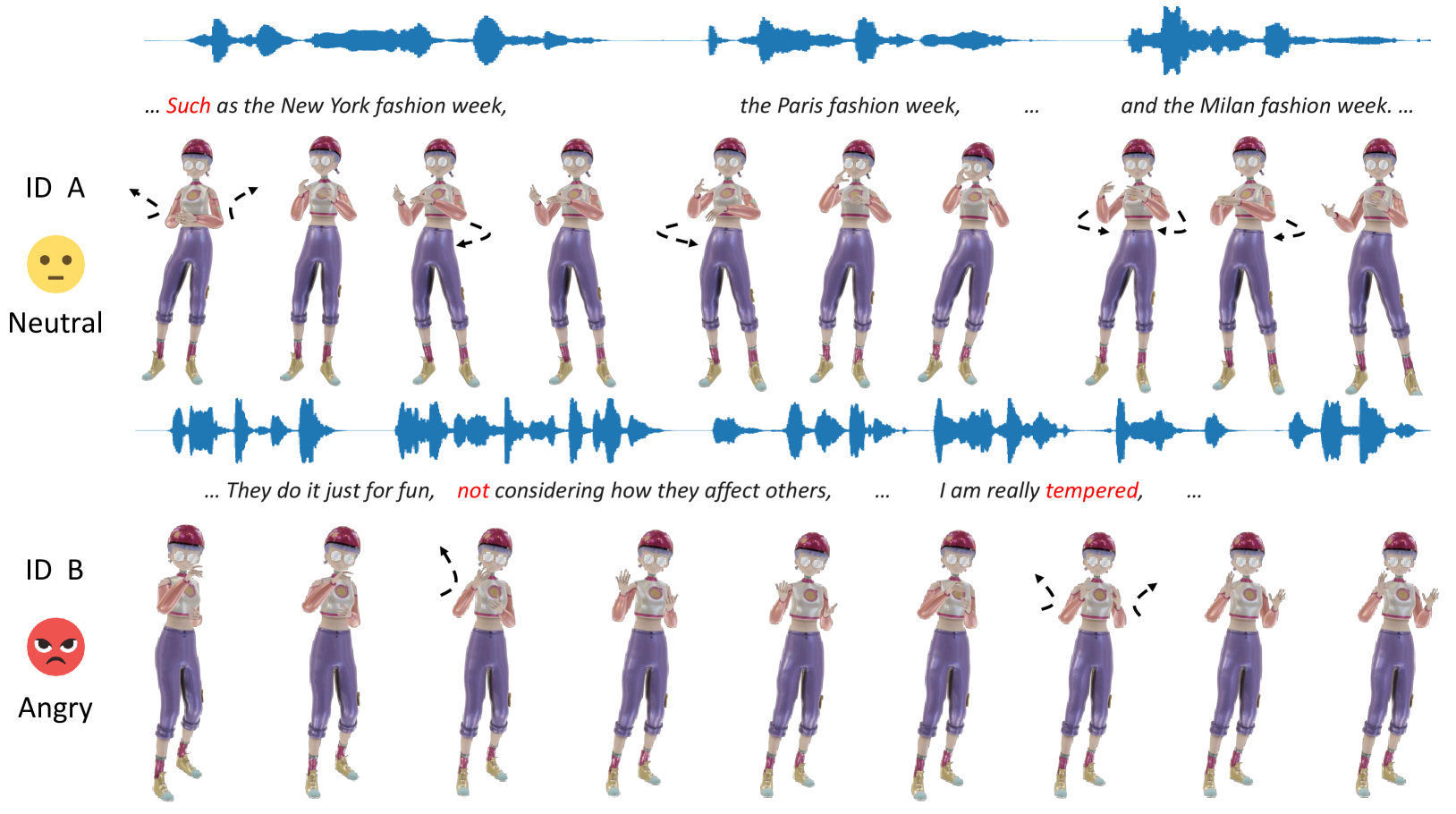
The body movements accompanying speech aid speakers in expressing their ideas. Co-speech motion generation is one of the important approaches for synthesizing realistic avatars. Due to the intricate correspondence between speech and motion, generating realistic and diverse motion is a challenging task. In this paper, we propose MMoFusion, a Multi-modal co-speech Motion generation framework based on the diffusion model to ensure both the authenticity and diversity of generated motion. We propose a progressive fusion strategy to enhance the interaction of inter-modal and intra-modal, efficiently integrating multi-modal information. Specifically, we employ a masked style matrix based on emotion and identity information to control the generation of different motion styles. Temporal modeling of speech and motion is partitioned into style-guided specific feature encoding and shared feature encoding, aiming to learn both inter-modal and intra-modal features. Besides, we propose a geometric loss to enforce the joints' velocity and acceleration coherence among frames. Our framework generates vivid, diverse, and style-controllable motion of arbitrary length through inputting speech and editing identity and emotion. Extensive experiments demonstrate that our method outperforms current co-speech motion generation methods including upper body and challenging full body.
Create account to get full access
Overview
- This paper presents a novel method called MMoFusion for generating co-speech motion, which is the synchronized movement of a person's body and hands while speaking.
- The method uses a diffusion model, a type of machine learning model, to generate the motion from a combination of audio and other input data.
- The paper demonstrates that MMoFusion can produce high-quality co-speech motion that is synchronized with the audio and looks natural.
Plain English Explanation
MMoFusion: Multi-modal Co-Speech Motion Generation with Diffusion Model is a new way to create animated characters that move their bodies and hands in a natural, lifelike way while speaking. The key idea is to use a special type of machine learning model called a diffusion model to generate the character's motion from a combination of audio (the speech) and other input data.
Diffusion models work by gradually adding noise to data, then learning how to reverse that process to generate new, realistic-looking data. In this case, the diffusion model learns how to generate natural-looking co-speech motion - the coordinated movement of a character's body and hands as they speak.
The model is trained on examples of real people speaking and moving, so it can capture the subtle connections between the audio and the corresponding body and hand motions. When given new audio input, the diffusion model can then produce a synchronized, realistic animation of a character moving in response to the speech.
This is a significant advance over previous methods, which often struggled to generate co-speech motion that looked truly natural and lifelike. The MMoFusion approach demonstrated in this paper brings us closer to being able to create animated characters that interact with us in a more natural, human-like way.
Technical Explanation
MMoFusion: Multi-modal Co-Speech Motion Generation with Diffusion Model uses a diffusion model architecture to generate co-speech motion - the coordinated movement of a character's body and hands in response to audio input.
The key innovation is the use of a multi-modal input that combines audio features with other relevant data, such as the speaker's facial movements and head pose. This allows the model to capture the complex relationships between the speech and the corresponding body and hand motions.
The diffusion model is trained on a large dataset of real people speaking and moving. It learns to gradually add noise to the input data, then reverse that process to generate new, realistic-looking co-speech motion. This approach enables the model to produce natural, synchronized motion that closely matches the input audio.
The paper demonstrates the effectiveness of the MMoFusion approach through extensive experiments, comparing it to previous state-of-the-art methods for co-speech motion generation. The results show that MMoFusion outperforms these methods in terms of motion quality, synchronization with audio, and overall realism.
Critical Analysis
The MMoFusion approach presented in this paper is a significant advancement in the field of co-speech motion generation. By leveraging the power of diffusion models and multi-modal input, the researchers have been able to generate highly realistic and synchronized motion that looks natural and lifelike.
However, the paper does acknowledge some limitations of the current approach. For example, the model is trained on a relatively narrow dataset of people speaking and moving in specific contexts, which may limit its ability to generalize to more diverse scenarios. Additionally, the computational complexity of the diffusion model may make it challenging to deploy in real-time applications.
Further research could explore ways to shape-condition the motion generation to allow for more personalized or expressive character animations. Additionally, integrating audio-driven gesture generation could potentially enhance the overall realism and expressiveness of the generated co-speech motion.
Overall, the MMoFusion approach represents a significant step forward in the quest to create animated characters that can interact with us in a more natural, human-like way. While there is still room for improvement, this research demonstrates the power of diffusion models and multi-modal input for tackling complex animation challenges.
Conclusion
MMoFusion: Multi-modal Co-Speech Motion Generation with Diffusion Model presents a novel method for generating realistic and synchronized co-speech motion using a diffusion model and multi-modal input. The key innovation is the ability to capture the complex relationships between speech and body/hand movements, enabling the creation of animated characters that interact in a more natural, lifelike way.
This research represents a significant advancement in the field of character animation and has the potential to impact a wide range of applications, from interactive virtual assistants to immersive gaming and entertainment experiences. As the technology continues to evolve, we can expect to see even more realistic and expressive animated characters that can engage with us in increasingly natural and meaningful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
0
0
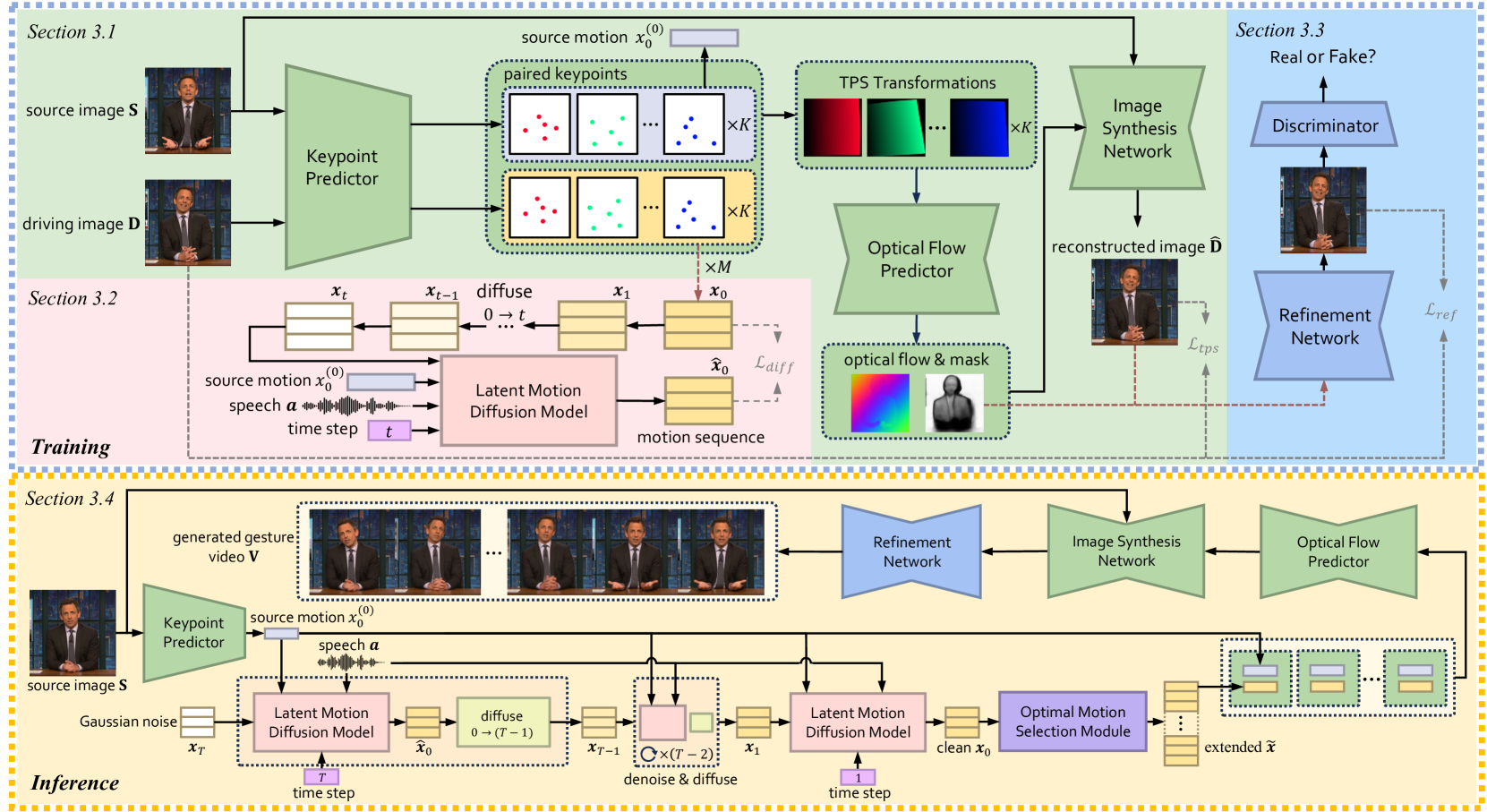
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
4/3/2024
🛸
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
Yiheng Huang, Hui Yang, Chuanchen Luo, Yuxi Wang, Shibiao Xu, Zhaoxiang Zhang, Man Zhang, Junran Peng
0
0
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: https://h-y1heng.github.io/StableMoFusion-page/
5/10/2024

Speech2UnifiedExpressions: Synchronous Synthesis of Co-Speech Affective Face and Body Expressions from Affordable Inputs
Uttaran Bhattacharya, Aniket Bera, Dinesh Manocha
0
0
We present a multimodal learning-based method to simultaneously synthesize co-speech facial expressions and upper-body gestures for digital characters using RGB video data captured using commodity cameras. Our approach learns from sparse face landmarks and upper-body joints, estimated directly from video data, to generate plausible emotive character motions. Given a speech audio waveform and a token sequence of the speaker's face landmark motion and body-joint motion computed from a video, our method synthesizes the motion sequences for the speaker's face landmarks and body joints to match the content and the affect of the speech. We design a generator consisting of a set of encoders to transform all the inputs into a multimodal embedding space capturing their correlations, followed by a pair of decoders to synthesize the desired face and pose motions. To enhance the plausibility of synthesis, we use an adversarial discriminator that learns to differentiate between the face and pose motions computed from the original videos and our synthesized motions based on their affective expressions. To evaluate our approach, we extend the TED Gesture Dataset to include view-normalized, co-speech face landmarks in addition to body gestures. We demonstrate the performance of our method through thorough quantitative and qualitative experiments on multiple evaluation metrics and via a user study. We observe that our method results in low reconstruction error and produces synthesized samples with diverse facial expressions and body gestures for digital characters.
6/27/2024
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, Changxing Ding
0
0
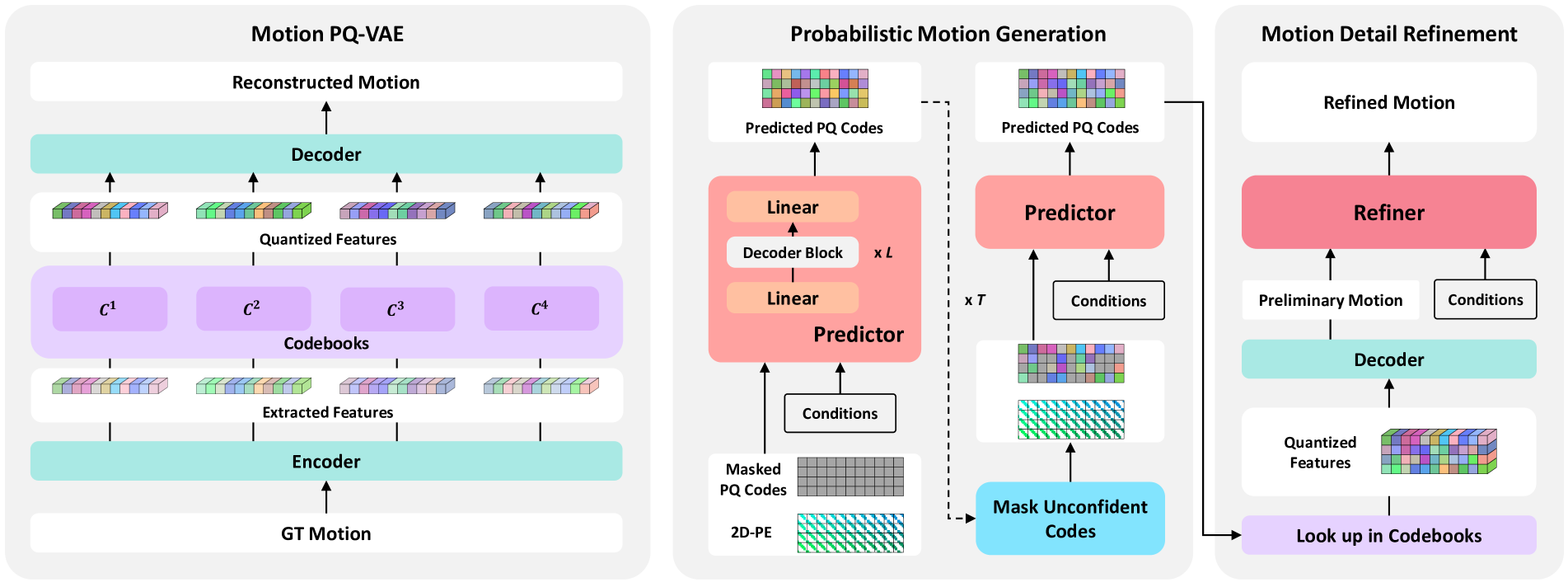
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
4/16/2024