Model-based Policy Optimization using Symbolic World Model

0

Sign in to get full access
Overview
- This paper presents a model-based policy optimization approach using a symbolic world model.
- The proposed method aims to improve the efficiency and performance of reinforcement learning agents by leveraging a symbolic representation of the environment.
- The researchers explore the use of genetic programming to discover dynamic symbolic policies, which can lead to efficient imitation learning with conservative world models and accelerated learning in model-based deep reinforcement learning.
Plain English Explanation
The paper describes a new approach to reinforcement learning, which is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties. In traditional reinforcement learning, the agent has to explore the environment extensively to learn how to perform well. This can be slow and inefficient.
The researchers in this paper propose using a "symbolic world model" - a mathematical representation of the environment that captures the underlying rules and dynamics. By learning this symbolic model, the agent can plan its actions more effectively, leading to faster and more efficient learning. The key idea is to use genetic programming, a type of evolutionary algorithm, to discover the symbolic policies that govern the agent's behavior.
This approach could be useful in a wide range of applications, from robotics and control systems to game-playing and decision-making. By incorporating a symbolic understanding of the environment, the agent can discover dynamic symbolic policies and make more informed decisions, leading to improved performance and efficiency compared to traditional reinforcement learning methods.
Technical Explanation
The paper presents a model-based policy optimization approach that leverages a symbolic world model. The key components of the proposed method are:
-
Symbolic World Model: The researchers use genetic programming to automatically discover a symbolic representation of the environment's dynamics. This symbolic model captures the underlying rules and relationships governing the environment.
-
Policy Optimization: Instead of directly exploring the environment, the agent uses the symbolic world model to plan its actions and optimize its policy. This allows the agent to learn more efficiently, as it can simulate and evaluate different strategies without the need for extensive trial-and-error.
-
Genetic Programming: The researchers employ genetic programming to evolve the symbolic policies that govern the agent's behavior. This approach allows the policies to be dynamic and adapt to changing environments, unlike traditional reinforcement learning methods.
The authors evaluate their approach on several benchmark tasks and demonstrate that it outperforms traditional model-free and model-based reinforcement learning methods in terms of sample efficiency and final performance.
Critical Analysis
The paper presents a promising approach to improving the efficiency and performance of reinforcement learning agents. The use of a symbolic world model and genetic programming to discover dynamic policies is a unique and interesting concept.
One potential limitation is the reliance on the accuracy of the symbolic world model. If the model does not capture all the relevant dynamics of the environment, it could lead to suboptimal policies. The authors acknowledge this and suggest that further research is needed to improve the robustness of the symbolic model learning process.
Additionally, the paper does not explore the scalability of the proposed method to more complex, high-dimensional environments. The genetic programming approach may face challenges in such settings, and the authors could have discussed potential strategies to address this.
Overall, the research presented in this paper is a valuable contribution to the field of reinforcement learning. The model-based approach and use of symbolic representations are promising directions that warrant further investigation and could lead to significant advancements in the efficiency and performance of reinforcement learning agents.
Conclusion
This paper introduces a novel model-based policy optimization approach that leverages a symbolic world model and genetic programming to discover dynamic policies. By incorporating a symbolic understanding of the environment, the proposed method can improve the efficiency and performance of reinforcement learning agents compared to traditional methods.
The research presented in this paper represents an exciting step forward in the field of reinforcement learning, with potential applications in a wide range of domains. The use of symbolic world models and genetic programming to discover dynamic symbolic policies could lead to more efficient imitation learning and accelerated learning in model-based deep reinforcement learning. Further research is needed to address the limitations and explore the scalability of this approach, but the findings in this paper are a promising step towards more efficient and effective reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Model-based Policy Optimization using Symbolic World Model
Andrey Gorodetskiy, Konstantin Mironov, Aleksandr Panov
The application of learning-based control methods in robotics presents significant challenges. One is that model-free reinforcement learning algorithms use observation data with low sample efficiency. To address this challenge, a prevalent approach is model-based reinforcement learning, which involves employing an environment dynamics model. We suggest approximating transition dynamics with symbolic expressions, which are generated via symbolic regression. Approximation of a mechanical system with a symbolic model has fewer parameters than approximation with neural networks, which can potentially lead to higher accuracy and quality of extrapolation. We use a symbolic dynamics model to generate trajectories in model-based policy optimization to improve the sample efficiency of the learning algorithm. We evaluate our approach across various tasks within simulated environments. Our method demonstrates superior sample efficiency in these tasks compared to model-free and model-based baseline methods.
Read more7/19/2024
📈
0
Model predictive control-based value estimation for efficient reinforcement learning
Qizhen Wu, Kexin Liu, Lei Chen
Reinforcement learning suffers from limitations in real practices primarily due to the number of required interactions with virtual environments. It results in a challenging problem because we are implausible to obtain a local optimal strategy with only a few attempts for many learning methods. Hereby, we design an improved reinforcement learning method based on model predictive control that models the environment through a data-driven approach. Based on the learned environment model, it performs multi-step prediction to estimate the value function and optimize the policy. The method demonstrates higher learning efficiency, faster convergent speed of strategies tending to the local optimal value, and less sample capacity space required by experience replay buffers. Experimental results, both in classic databases and in a dynamic obstacle avoidance scenario for an unmanned aerial vehicle, validate the proposed approaches.
Read more4/12/2024
🌀
0
Efficient Imitation Learning with Conservative World Models
Victor Kolev, Rafael Rafailov, Kyle Hatch, Jiajun Wu, Chelsea Finn
We tackle the problem of policy learning from expert demonstrations without a reward function. A central challenge in this space is that these policies fail upon deployment due to issues of distributional shift, environment stochasticity, or compounding errors. Adversarial imitation learning alleviates this issue but requires additional on-policy training samples for stability, which presents a challenge in realistic domains due to inefficient learning and high sample complexity. One approach to this issue is to learn a world model of the environment, and use synthetic data for policy training. While successful in prior works, we argue that this is sub-optimal due to additional distribution shifts between the learned model and the real environment. Instead, we re-frame imitation learning as a fine-tuning problem, rather than a pure reinforcement learning one. Drawing theoretical connections to offline RL and fine-tuning algorithms, we argue that standard online world model algorithms are not well suited to the imitation learning problem. We derive a principled conservative optimization bound and demonstrate empirically that it leads to improved performance on two very challenging manipulation environments from high-dimensional raw pixel observations. We set a new state-of-the-art performance on the Franka Kitchen environment from images, requiring only 10 demos on no reward labels, as well as solving a complex dexterity manipulation task.
Read more8/19/2024
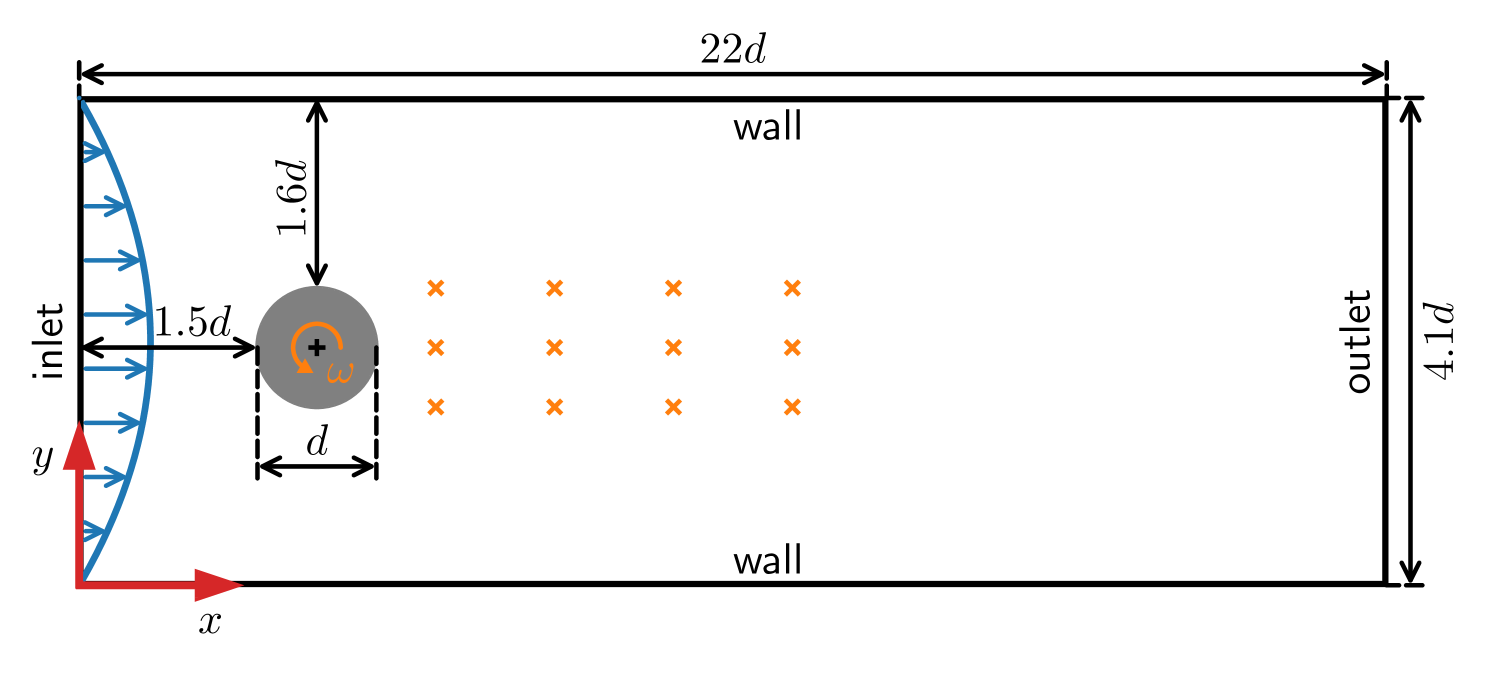
0
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
Read more4/11/2024