Model and Feature Diversity for Bayesian Neural Networks in Mutual Learning

0
📈
Sign in to get full access
Overview
• This research paper explores the use of Bayesian neural networks (BNNs) in a mutual learning framework, with a focus on model and feature diversity.
• The paper investigates how the diversity of BNN models and features can impact the performance of mutual learning, which is a technique for training multiple models collaboratively.
Plain English Explanation
The researchers wanted to understand how the variety of Bayesian neural network models and the different types of features they learn can affect the performance of a mutual learning approach. Mutual learning is a way of training multiple models together, where the models learn from each other and improve over time.
Bayesian neural networks are a type of machine learning model that can capture uncertainty in their predictions, which can be useful in many real-world applications. The researchers explored how the diversity, or differences, between these Bayesian models and the features they learn can impact the overall performance of the mutual learning process.
By understanding the role of model and feature diversity, the researchers hope to provide insights that can help improve the effectiveness of mutual learning techniques, particularly when using Bayesian neural networks.
Technical Explanation
The paper investigates the impact of model and feature diversity in Bayesian neural networks (BNNs) within a mutual learning framework. Mutual learning is a technique where multiple models are trained collaboratively, with each model learning from the others to improve its own performance.
The researchers hypothesized that the diversity of BNN models and the features they learn could play a crucial role in the effectiveness of mutual learning. They conducted experiments to analyze how different levels of model and feature diversity affect the performance of the mutual learning process.
The paper presents several key findings:
- Increased model diversity can lead to improved mutual learning performance, as the models can learn complementary information from each other.
- Feature diversity is also important, as models that learn a diverse set of features can provide more valuable information to the other models in the mutual learning process.
- The researchers found that a balance between model and feature diversity is crucial for optimal mutual learning performance, as too much or too little diversity can negatively impact the overall results.
The paper also discusses the implications of these findings and how they can be applied to improve the performance of mutual learning approaches, particularly when using Bayesian neural networks.
Critical Analysis
The paper provides valuable insights into the role of model and feature diversity in Bayesian neural networks within a mutual learning framework. The experimental design and analysis are well-executed, and the findings offer important considerations for researchers and practitioners working with mutual learning techniques.
However, the paper does not extensively explore the potential limitations or caveats of the proposed approach. For example, it would be interesting to see how the findings might be affected by the specific neural network architectures, the choice of Bayesian inference methods, or the characteristics of the datasets used.
Additionally, the paper could have discussed the computational and training overhead associated with maintaining high levels of model and feature diversity, as this could be an important practical concern for real-world applications.
[Further research could also investigate the relationship between model and feature diversity in the context of other types of machine learning models, such as neural additive models or restricted Bayesian neural networks, to provide a more comprehensive understanding of the topic.](https://aimodels.fyi/papers/arxiv/improving-neural-additive-models-bayesian-principles)
Conclusion
This research paper makes a valuable contribution to the understanding of model and feature diversity in Bayesian neural networks within a mutual learning framework. The findings highlight the importance of striking a balance between these two factors to achieve optimal performance in mutual learning approaches.
The insights provided in this paper can inform the design and development of more effective mutual learning systems, particularly in applications where Bayesian neural networks are employed. By considering the role of model and feature diversity, researchers and practitioners can work towards improving the robustness and reliability of machine learning models in a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Model and Feature Diversity for Bayesian Neural Networks in Mutual Learning
Cuong Pham, Cuong C. Nguyen, Trung Le, Dinh Phung, Gustavo Carneiro, Thanh-Toan Do
Bayesian Neural Networks (BNNs) offer probability distributions for model parameters, enabling uncertainty quantification in predictions. However, they often underperform compared to deterministic neural networks. Utilizing mutual learning can effectively enhance the performance of peer BNNs. In this paper, we propose a novel approach to improve BNNs performance through deep mutual learning. The proposed approaches aim to increase diversity in both network parameter distributions and feature distributions, promoting peer networks to acquire distinct features that capture different characteristics of the input, which enhances the effectiveness of mutual learning. Experimental results demonstrate significant improvements in the classification accuracy, negative log-likelihood, and expected calibration error when compared to traditional mutual learning for BNNs.
Read more7/4/2024
0
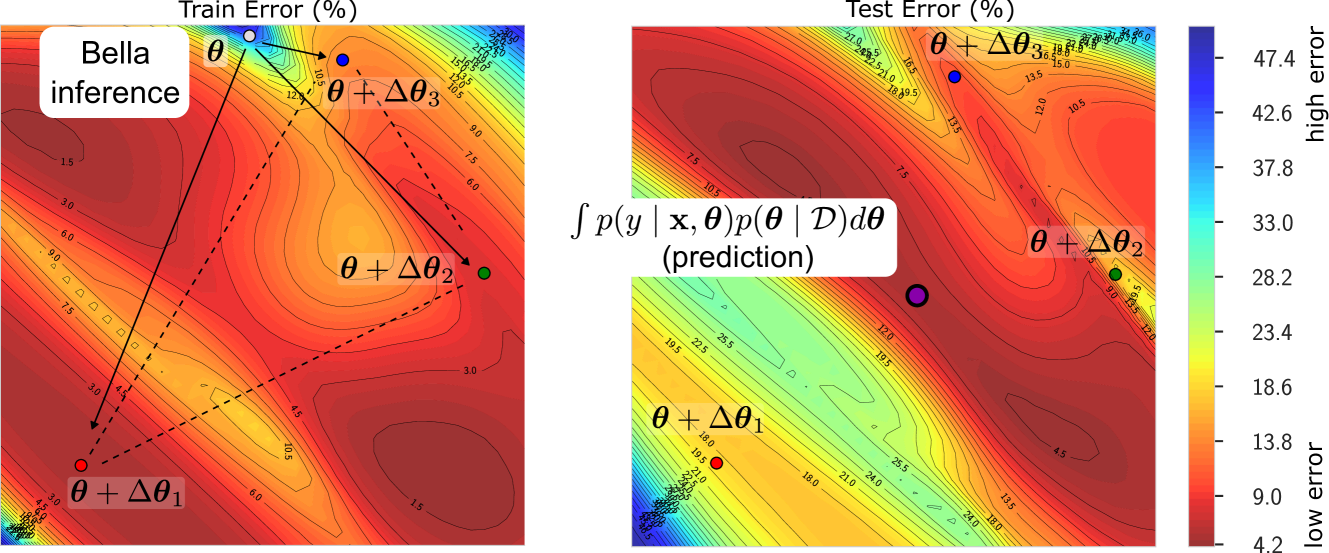
Bayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks
Bao Gia Doan, Afshar Shamsi, Xiao-Yu Guo, Arash Mohammadi, Hamid Alinejad-Rokny, Dino Sejdinovic, Damith C. Ranasinghe, Ehsan Abbasnejad
Computational complexity of Bayesian learning is impeding its adoption in practical, large-scale tasks. Despite demonstrations of significant merits such as improved robustness and resilience to unseen or out-of-distribution inputs over their non- Bayesian counterparts, their practical use has faded to near insignificance. In this study, we introduce an innovative framework to mitigate the computational burden of Bayesian neural networks (BNNs). Our approach follows the principle of Bayesian techniques based on deep ensembles, but significantly reduces their cost via multiple low-rank perturbations of parameters arising from a pre-trained neural network. Both vanilla version of ensembles as well as more sophisticated schemes such as Bayesian learning with Stein Variational Gradient Descent (SVGD), previously deemed impractical for large models, can be seamlessly implemented within the proposed framework, called Bayesian Low-Rank LeArning (Bella). In a nutshell, i) Bella achieves a dramatic reduction in the number of trainable parameters required to approximate a Bayesian posterior; and ii) it not only maintains, but in some instances, surpasses the performance of conventional Bayesian learning methods and non-Bayesian baselines. Our results with large-scale tasks such as ImageNet, CAMELYON17, DomainNet, VQA with CLIP, LLaVA demonstrate the effectiveness and versatility of Bella in building highly scalable and practical Bayesian deep models for real-world applications.
Read more8/27/2024
📊
0
Incorporating Unlabelled Data into Bayesian Neural Networks
Mrinank Sharma, Tom Rainforth, Yee Whye Teh, Vincent Fortuin
Conventional Bayesian Neural Networks (BNNs) are unable to leverage unlabelled data to improve their predictions. To overcome this limitation, we introduce Self-Supervised Bayesian Neural Networks, which use unlabelled data to learn models with suitable prior predictive distributions. This is achieved by leveraging contrastive pretraining techniques and optimising a variational lower bound. We then show that the prior predictive distributions of self-supervised BNNs capture problem semantics better than conventional BNN priors. In turn, our approach offers improved predictive performance over conventional BNNs, especially in low-budget regimes.
Read more9/2/2024
0
Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize
Tianren Zhang, Chujie Zhao, Guanyu Chen, Yizhou Jiang, Feng Chen
Learning representations that generalize under distribution shifts is critical for building robust machine learning models. However, despite significant efforts in recent years, algorithmic advances in this direction have been limited. In this work, we seek to understand the fundamental difficulty of out-of-distribution generalization with deep neural networks. We first empirically show that perhaps surprisingly, even allowing a neural network to explicitly fit the representations obtained from a teacher network that can generalize out-of-distribution is insufficient for the generalization of the student network. Then, by a theoretical study of two-layer ReLU networks optimized by stochastic gradient descent (SGD) under a structured feature model, we identify a fundamental yet unexplored feature learning proclivity of neural networks, feature contamination: neural networks can learn uncorrelated features together with predictive features, resulting in generalization failure under distribution shifts. Notably, this mechanism essentially differs from the prevailing narrative in the literature that attributes the generalization failure to spurious correlations. Overall, our results offer new insights into the non-linear feature learning dynamics of neural networks and highlight the necessity of considering inductive biases in out-of-distribution generalization.
Read more6/7/2024