Modelling Multimodal Integration in Human Concept Processing with Vision-and-Language Models

0
⚙️
Sign in to get full access
Overview
- This paper explores how language and vision can be integrated to model human concept processing.
- The researchers use language-and-vision transformers, a type of deep learning model, to study multimodal integration.
- Experiments are conducted to understand how the model represents and processes concepts that involve both language and visual information.
Plain English Explanation
The researchers in this paper are interested in understanding how humans process concepts that involve both language and visual information. For example, when we think about the concept of a "dog", we rely on both the language we use to describe it and the visual information we have about what dogs look like.
To study this, the researchers use a type of deep learning model called a "language-and-vision transformer". This model is designed to process both language and visual data, much like the human brain does. The researchers conduct experiments to see how this model represents and processes various concepts that have both language and visual components.
By studying how the model integrates language and visual information, the researchers hope to gain insights into the underlying mechanisms of human concept processing. This could have important implications for fields like artificial intelligence, cognitive science, and neuroscience.
Technical Explanation
The paper uses a language-and-vision transformer to study how humans integrate language and visual information when processing concepts. This type of model is designed to process both textual and visual data, allowing it to learn representations that capture the multimodal nature of human cognition.
The researchers conduct experiments where the model is trained on language-and-image datasets and then tested on its ability to perform various tasks, such as classifying images or answering questions about concepts. By analyzing the model's internal representations and decision-making processes, the researchers aim to uncover the underlying principles of multimodal integration in human concept processing.
The findings suggest that the language-and-vision transformer is able to learn rich, aligned visual and linguistic representations that capture the interplay between language and vision in human conceptual knowledge. This provides insights into the cognitive mechanisms involved in multimodal concept processing.
Critical Analysis
The paper presents a promising approach to studying multimodal integration in human concept processing, but it also acknowledges several limitations and areas for further research. For example, the experiments are conducted on relatively simple, curated datasets, and it's unclear how well the findings would generalize to more complex, real-world scenarios.
Additionally, the paper does not delve into the potential ethical implications of this research, such as how these models could be used or misused in applications that involve human-like concept processing. It would be valuable for the authors to address these concerns and discuss responsible development and deployment of such technologies.
Overall, the paper makes a valuable contribution to the understanding of multimodal integration in human cognition, but more work is needed to fully explore the nuances and potential societal impacts of this line of research.
Conclusion
This paper demonstrates the potential of language-and-vision transformers to provide insights into the cognitive mechanisms underlying human concept processing. By studying how these models integrate language and visual information, the researchers gain a better understanding of the interplay between different modalities in the human mind.
The findings have implications for artificial intelligence, as well as fields like cognitive science and neuroscience. The research could inform the development of more human-like AI systems and lead to a deeper understanding of the complexities of human conceptual knowledge.
While the paper presents a promising approach, it also highlights the need for further research to address the limitations and potential ethical concerns. Continued exploration in this area could yield valuable insights and advancements in our understanding of the human mind and its relationship with language and vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Modelling Multimodal Integration in Human Concept Processing with Vision-and-Language Models
Anna Bavaresco, Marianne de Heer Kloots, Sandro Pezzelle, Raquel Fern'andez
Representations from deep neural networks (DNNs) have proven remarkably predictive of neural activity involved in both visual and linguistic processing. Despite these successes, most studies to date concern unimodal DNNs, encoding either visual or textual input but not both. Yet, there is growing evidence that human meaning representations integrate linguistic and sensory-motor information. Here we investigate whether the integration of multimodal information operated by current vision-and-language DNN models (VLMs) leads to representations that are more aligned with human brain activity than those obtained by language-only and vision-only DNNs. We focus on fMRI responses recorded while participants read concept words in the context of either a full sentence or an accompanying picture. Our results reveal that VLM representations correlate more strongly than language- and vision-only DNNs with activations in brain areas functionally related to language processing. A comparison between different types of visuo-linguistic architectures shows that recent generative VLMs tend to be less brain-aligned than previous architectures with lower performance on downstream applications. Moreover, through an additional analysis comparing brain vs. behavioural alignment across multiple VLMs, we show that -- with one remarkable exception -- representations that strongly align with behavioural judgments do not correlate highly with brain responses. This indicates that brain similarity does not go hand in hand with behavioural similarity, and vice versa.
Read more7/26/2024

0
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Vighnesh Subramaniam, Colin Conwell, Christopher Wang, Gabriel Kreiman, Boris Katz, Ignacio Cases, Andrei Barbu
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
Read more6/21/2024
💬
0
Visual representations in the human brain are aligned with large language models
Adrien Doerig, Tim C Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, Ian Charest
The human brain extracts complex information from visual inputs, including objects, their spatial and semantic interrelations, and their interactions with the environment. However, a quantitative approach for studying this information remains elusive. Here, we test whether the contextual information encoded in large language models (LLMs) is beneficial for modelling the complex visual information extracted by the brain from natural scenes. We show that LLM embeddings of scene captions successfully characterise brain activity evoked by viewing the natural scenes. This mapping captures selectivities of different brain areas, and is sufficiently robust that accurate scene captions can be reconstructed from brain activity. Using carefully controlled model comparisons, we then proceed to show that the accuracy with which LLM representations match brain representations derives from the ability of LLMs to integrate complex information contained in scene captions beyond that conveyed by individual words. Finally, we train deep neural network models to transform image inputs into LLM representations. Remarkably, these networks learn representations that are better aligned with brain representations than a large number of state-of-the-art alternative models, despite being trained on orders-of-magnitude less data. Overall, our results suggest that LLM embeddings of scene captions provide a representational format that accounts for complex information extracted by the brain from visual inputs.
Read more7/9/2024
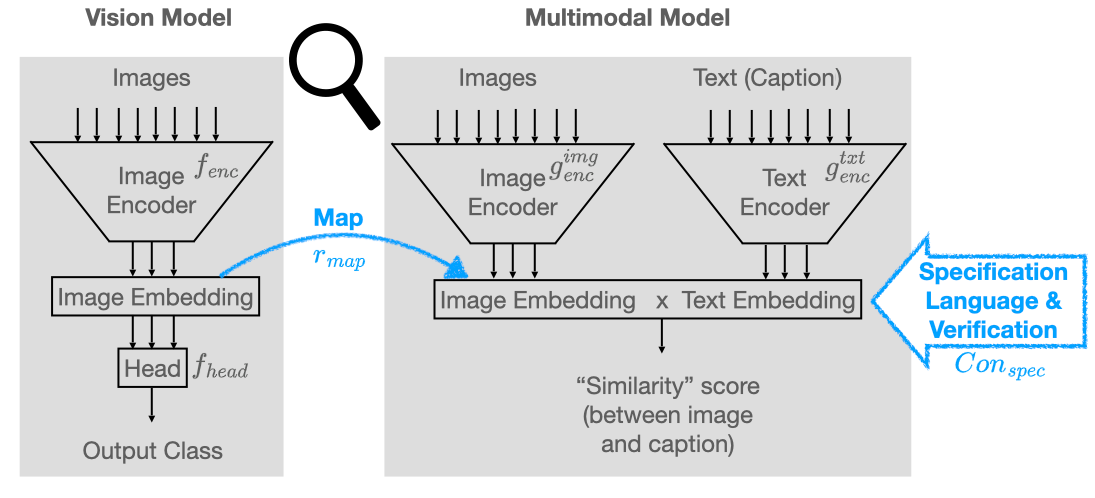
0
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Read more4/12/2024