Visual representations in the human brain are aligned with large language models

0
💬
Sign in to get full access
Overview
- The human brain can extract complex information from visual inputs, including objects, their spatial and semantic relationships, and their interactions with the environment.
- However, a quantitative approach for studying this information has been elusive.
- This paper investigates whether the contextual information encoded in large language models (LLMs) can be used to model the complex visual information extracted by the brain from natural scenes.
Plain English Explanation
The human brain is incredibly skilled at processing visual information. When we look at a scene, we can quickly identify the objects, understand how they are arranged in space, and even grasp the relationships between them and their environment. However, it has been challenging for researchers to develop a quantitative way to study this complex visual processing that occurs in the brain.
In this study, the researchers explored whether the insights captured by large language models (LLMs) could be used to model the brain's representation of visual scenes. LLMs are artificial intelligence systems that have been trained on vast amounts of text data, allowing them to understand the contextual relationships between words and concepts.
The researchers discovered that the embeddings (mathematical representations) of scene captions generated by LLMs could successfully characterize the brain activity evoked by viewing those natural scenes. This means that the way the LLM represents the information in the captions aligns well with how the brain processes the visual information in the scenes.
Furthermore, the researchers found that the LLM representations captured more than just the individual objects in the scenes; they also reflected the complex relationships and interactions between the elements. This suggests that LLMs are able to integrate and represent the rich contextual information that the brain extracts from visual inputs.
Technical Explanation
The researchers used a combination of brain imaging data and large language model (LLM) representations to investigate how the brain encodes complex visual information from natural scenes.
They first showed that LLM embeddings of scene captions could successfully characterize the brain activity evoked by viewing the corresponding natural scenes. This mapping captured the selectivities of different brain areas and was robust enough that accurate scene captions could be reconstructed from the brain activity.
Through carefully designed model comparisons, the researchers then demonstrated that the accuracy of the LLM representations in matching brain representations was due to the models' ability to integrate the complex information contained in the scene captions, beyond what could be captured by individual words alone. This suggests that LLMs are able to encode human-like object concept representations and mirror cognitive language processing.
Finally, the researchers trained deep neural network models to transform image inputs into LLM representations. Remarkably, these networks learned representations that were better aligned with brain representations than a large number of state-of-the-art alternative models, despite being trained on orders-of-magnitude less data. This indicates that the brain-like language processing capabilities of LLMs can be transferred to image-to-text captioning tasks.
Critical Analysis
The paper provides a compelling demonstration of how the contextual information encoded in LLMs can be leveraged to model the complex visual processing that occurs in the human brain. The researchers' careful experimental design and model comparisons lend strong support to their conclusions.
However, it is important to note that this research is limited to the specific task of processing natural scenes. It remains to be seen whether the same LLM-based approach would be effective for modeling the brain's representation of other types of visual inputs, such as abstract or artificial stimuli.
Additionally, the paper does not address the potential biases or limitations that may be present in the LLM representations, which could be reflected in the brain-model alignment. Further investigation into the interpretability and fairness of these LLM-based models would be valuable.
Overall, this study represents an important step forward in understanding the intersection of language, vision, and cognition, and highlights the potential for large language models to serve as powerful tools for modeling and understanding the brain.
Conclusion
This research demonstrates that the contextual information encoded in large language models (LLMs) can be used to effectively model the complex visual information extracted by the human brain from natural scenes. The LLM representations were found to capture more than just individual objects, reflecting the rich relationships and interactions between elements in the scenes.
The ability of LLMs to integrate and represent this complex visual information in a way that aligns with brain activity suggests that these models may be tapping into similar cognitive processing mechanisms as the human brain. This finding has important implications for our understanding of visual perception, language, and the connections between them.
While this study focused on natural scenes, the potential for LLMs to serve as powerful tools for modeling and understanding the brain's representation of visual information more broadly is an exciting area for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Visual representations in the human brain are aligned with large language models
Adrien Doerig, Tim C Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, Ian Charest
The human brain extracts complex information from visual inputs, including objects, their spatial and semantic interrelations, and their interactions with the environment. However, a quantitative approach for studying this information remains elusive. Here, we test whether the contextual information encoded in large language models (LLMs) is beneficial for modelling the complex visual information extracted by the brain from natural scenes. We show that LLM embeddings of scene captions successfully characterise brain activity evoked by viewing the natural scenes. This mapping captures selectivities of different brain areas, and is sufficiently robust that accurate scene captions can be reconstructed from brain activity. Using carefully controlled model comparisons, we then proceed to show that the accuracy with which LLM representations match brain representations derives from the ability of LLMs to integrate complex information contained in scene captions beyond that conveyed by individual words. Finally, we train deep neural network models to transform image inputs into LLM representations. Remarkably, these networks learn representations that are better aligned with brain representations than a large number of state-of-the-art alternative models, despite being trained on orders-of-magnitude less data. Overall, our results suggest that LLM embeddings of scene captions provide a representational format that accounts for complex information extracted by the brain from visual inputs.
Read more7/9/2024

0
LLM4Brain: Training a Large Language Model for Brain Video Understanding
Ruizhe Zheng, Lichao Sun
Decoding visual-semantic information from brain signals, such as functional MRI (fMRI), across different subjects poses significant challenges, including low signal-to-noise ratio, limited data availability, and cross-subject variability. Recent advancements in large language models (LLMs) show remarkable effectiveness in processing multimodal information. In this study, we introduce an LLM-based approach for reconstructing visual-semantic information from fMRI signals elicited by video stimuli. Specifically, we employ fine-tuning techniques on an fMRI encoder equipped with adaptors to transform brain responses into latent representations aligned with the video stimuli. Subsequently, these representations are mapped to textual modality by LLM. In particular, we integrate self-supervised domain adaptation methods to enhance the alignment between visual-semantic information and brain responses. Our proposed method achieves good results using various quantitative semantic metrics, while yielding similarity with ground-truth information.
Read more9/27/2024
⚙️
0
Modelling Multimodal Integration in Human Concept Processing with Vision-and-Language Models
Anna Bavaresco, Marianne de Heer Kloots, Sandro Pezzelle, Raquel Fern'andez
Representations from deep neural networks (DNNs) have proven remarkably predictive of neural activity involved in both visual and linguistic processing. Despite these successes, most studies to date concern unimodal DNNs, encoding either visual or textual input but not both. Yet, there is growing evidence that human meaning representations integrate linguistic and sensory-motor information. Here we investigate whether the integration of multimodal information operated by current vision-and-language DNN models (VLMs) leads to representations that are more aligned with human brain activity than those obtained by language-only and vision-only DNNs. We focus on fMRI responses recorded while participants read concept words in the context of either a full sentence or an accompanying picture. Our results reveal that VLM representations correlate more strongly than language- and vision-only DNNs with activations in brain areas functionally related to language processing. A comparison between different types of visuo-linguistic architectures shows that recent generative VLMs tend to be less brain-aligned than previous architectures with lower performance on downstream applications. Moreover, through an additional analysis comparing brain vs. behavioural alignment across multiple VLMs, we show that -- with one remarkable exception -- representations that strongly align with behavioural judgments do not correlate highly with brain responses. This indicates that brain similarity does not go hand in hand with behavioural similarity, and vice versa.
Read more7/26/2024
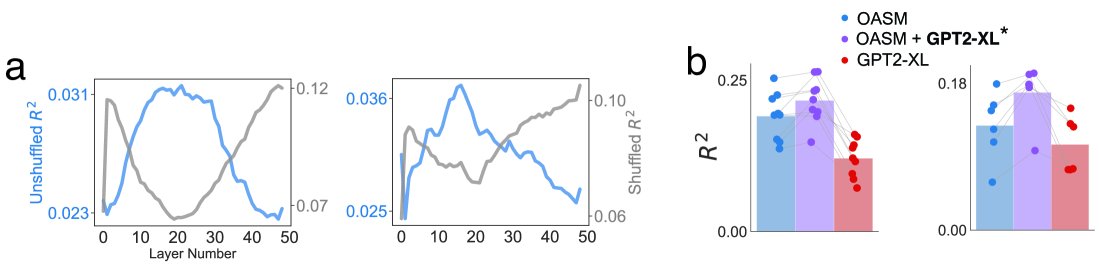
0
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, Jonathan C. Kao
Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called brain score. Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
Read more6/24/2024