Modular Sentence Encoders: Separating Language Specialization from Cross-Lingual Alignment

0

Sign in to get full access
Overview
- This paper proposes a modular sentence encoder architecture that separates language specialization from cross-lingual alignment.
- The key idea is to disentangle the language-specific and cross-lingual components of sentence representations, allowing for more efficient training and better performance on multilingual tasks.
- The authors evaluate their approach on a range of tasks, including cross-lingual sentence retrieval and natural language inference, and demonstrate improvements over existing methods.
Plain English Explanation
The paper introduces a new way to build sentence encoders - algorithms that convert text into numerical representations that can be used for various language tasks. The main challenge with existing sentence encoders is that they try to do two things at once: specialize for individual languages and align the representations across languages.
The researchers' key insight is that these two goals - language specialization and cross-lingual alignment - may be in tension with each other. So they propose a modular approach that separates these concerns. Their model has one set of components that learn the unique features of each language, and another set of components that work to align the representations across languages.
This separation allows the model to be more efficient in its training and to perform better on tasks that require understanding multiple languages, such as cross-lingual sentence retrieval or multilingual natural language inference. The authors show that their approach outperforms existing methods on a range of such tasks.
The key advantage of this modular design is that it allows the model to specialize in each language without having to also focus on aligning the representations. This can lead to better performance, especially for low-resource languages where alignment is particularly challenging. It also makes the model more interpretable, since the different components have distinct roles.
Technical Explanation
The paper proposes a modular sentence encoder architecture that separates language specialization from cross-lingual alignment. The model consists of three main components:
-
Language-Specific Encoders: These are individual encoders trained on each language to capture the unique features and properties of that language. They learn language-specific representations.
-
Cross-Lingual Aligner: This component takes the language-specific representations and aligns them into a shared cross-lingual space. It learns to map the representations from different languages onto a common semantic space.
-
Task-Specific Head: This is a task-specific module (e.g., for sentence retrieval or natural language inference) that operates on the aligned cross-lingual representations.
The key innovation is that the language-specific encoders and cross-lingual aligner are trained separately, rather than jointly as in previous approaches. This allows the model to specialize in each language without having to also focus on cross-lingual alignment.
The authors evaluate their approach on a range of cross-lingual tasks, including:
- Cross-Lingual Sentence Retrieval: Given a sentence in one language, retrieve the most similar sentence in another language.
- Cross-Lingual Natural Language Inference: Determine whether a premise sentence in one language entails, contradicts, or is neutral with respect to a hypothesis sentence in another language.
They show that their modular approach outperforms existing methods that jointly learn language-specific and cross-lingual components. The separation of concerns allows for more efficient training and better performance, especially on low-resource languages.
Critical Analysis
The modular approach proposed in this paper is a clever way to address the inherent tradeoff between language specialization and cross-lingual alignment in sentence encoders. By disentangling these two concerns, the model can focus on each task independently, leading to better performance.
One potential limitation is that the separate training of the language-specific encoders and cross-lingual aligner may introduce additional complexity and computational overhead. The authors do not provide a detailed analysis of the training time or model size compared to joint approaches.
Additionally, the paper does not explore the interpretability of the individual components in depth. While the modular design promises better interpretability, the authors could have provided more insights into how the language-specific and cross-lingual components behave and interact.
Further research could also investigate the robustness of the modular approach to domain shifts or noisy data, as well as its scalability to a larger number of languages. Exploring ways to dynamically adjust the weighting between language specialization and cross-lingual alignment could also be an interesting direction.
Conclusion
This paper presents a novel modular sentence encoder architecture that separates language specialization from cross-lingual alignment. By disentangling these two concerns, the model can achieve better performance on a range of cross-lingual tasks compared to existing approaches.
The modular design also promises improved interpretability, as the different components have distinct roles and can be analyzed independently. While the paper does not fully explore this aspect, the underlying principles could lead to more transparent and explainable multilingual language models.
Overall, the proposed approach is a significant contribution to the field of multilingual natural language processing, and the authors' insights could inspire further research into more efficient and effective sentence encoding techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Modular Sentence Encoders: Separating Language Specialization from Cross-Lingual Alignment
Yongxin Huang, Kexin Wang, Goran Glavav{s}, Iryna Gurevych
Multilingual sentence encoders are commonly obtained by training multilingual language models to map sentences from different languages into a shared semantic space. As such, they are subject to curse of multilinguality, a loss of monolingual representational accuracy due to parameter sharing. Another limitation of multilingual sentence encoders is the trade-off between monolingual and cross-lingual performance. Training for cross-lingual alignment of sentence embeddings distorts the optimal monolingual structure of semantic spaces of individual languages, harming the utility of sentence embeddings in monolingual tasks. In this work, we address both issues by modular training of sentence encoders, i.e., by separating monolingual specialization from cross-lingual alignment. We first efficiently train language-specific sentence encoders to avoid negative interference between languages (i.e., the curse). We then align all non-English monolingual encoders to the English encoder by training a cross-lingual alignment adapter on top of each, preventing interference with monolingual specialization from the first step. In both steps, we resort to contrastive learning on machine-translated paraphrase data. Monolingual and cross-lingual evaluations on semantic text similarity/relatedness and multiple-choice QA render our modular solution more effective than multilingual sentence encoders, especially benefiting low-resource languages.
Read more7/23/2024
✨
0
Linear Cross-Lingual Mapping of Sentence Embeddings
Oleg Vasilyev, Fumika Isono, John Bohannon
Semantics of a sentence is defined with much less ambiguity than semantics of a single word, and we assume that it should be better preserved by translation to another language. If multilingual sentence embeddings intend to represent sentence semantics, then the similarity between embeddings of any two sentences must be invariant with respect to translation. Based on this suggestion, we consider a simple linear cross-lingual mapping as a possible improvement of the multilingual embeddings. We also consider deviation from orthogonality conditions as a measure of deficiency of the embeddings.
Read more6/28/2024
💬
0
Improving In-context Learning of Multilingual Generative Language Models with Cross-lingual Alignment
Chong Li, Shaonan Wang, Jiajun Zhang, Chengqing Zong
Multilingual generative models obtain remarkable cross-lingual in-context learning capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages and learn isolated distributions of multilingual sentence representations, which may hinder knowledge transfer across languages. To bridge this gap, we propose a simple yet effective cross-lingual alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns outputs by following cross-lingual instructions in the target language. Experimental results show that even with less than 0.1 {textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative language models and mitigates the performance gap. Further analyses reveal that it results in a better internal multilingual representation distribution of multilingual models.
Read more6/13/2024
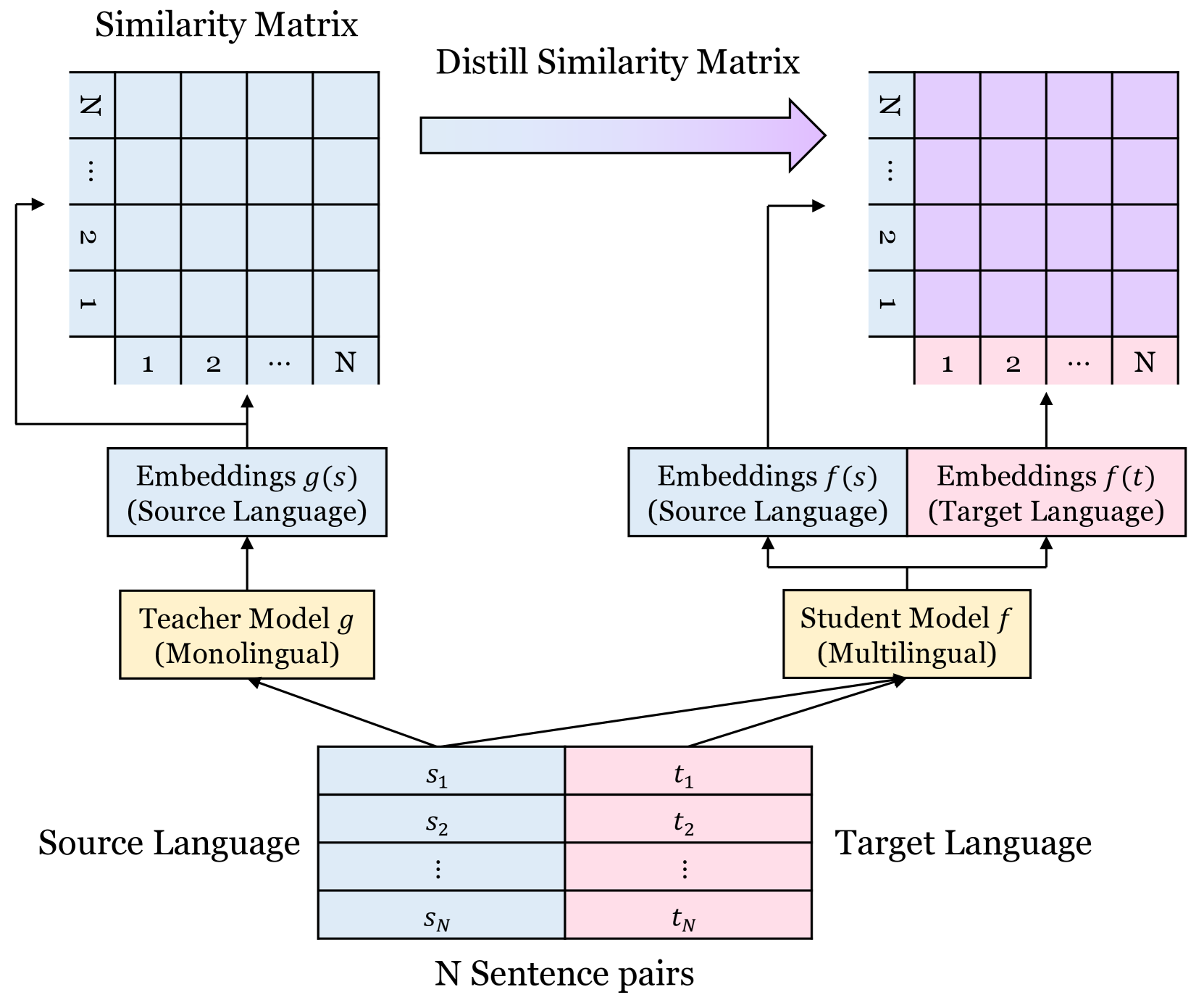
0
Improving Multi-lingual Alignment Through Soft Contrastive Learning
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Read more5/29/2024