A Resource Model For Neural Scaling Law

0
Sign in to get full access
Overview
- This paper presents a resource model for understanding neural scaling laws, which describe the empirical relationship between the performance of AI models and their computational resources.
- The authors propose a mathematical framework to capture the fundamental constraints and tradeoffs that govern the scaling of neural networks.
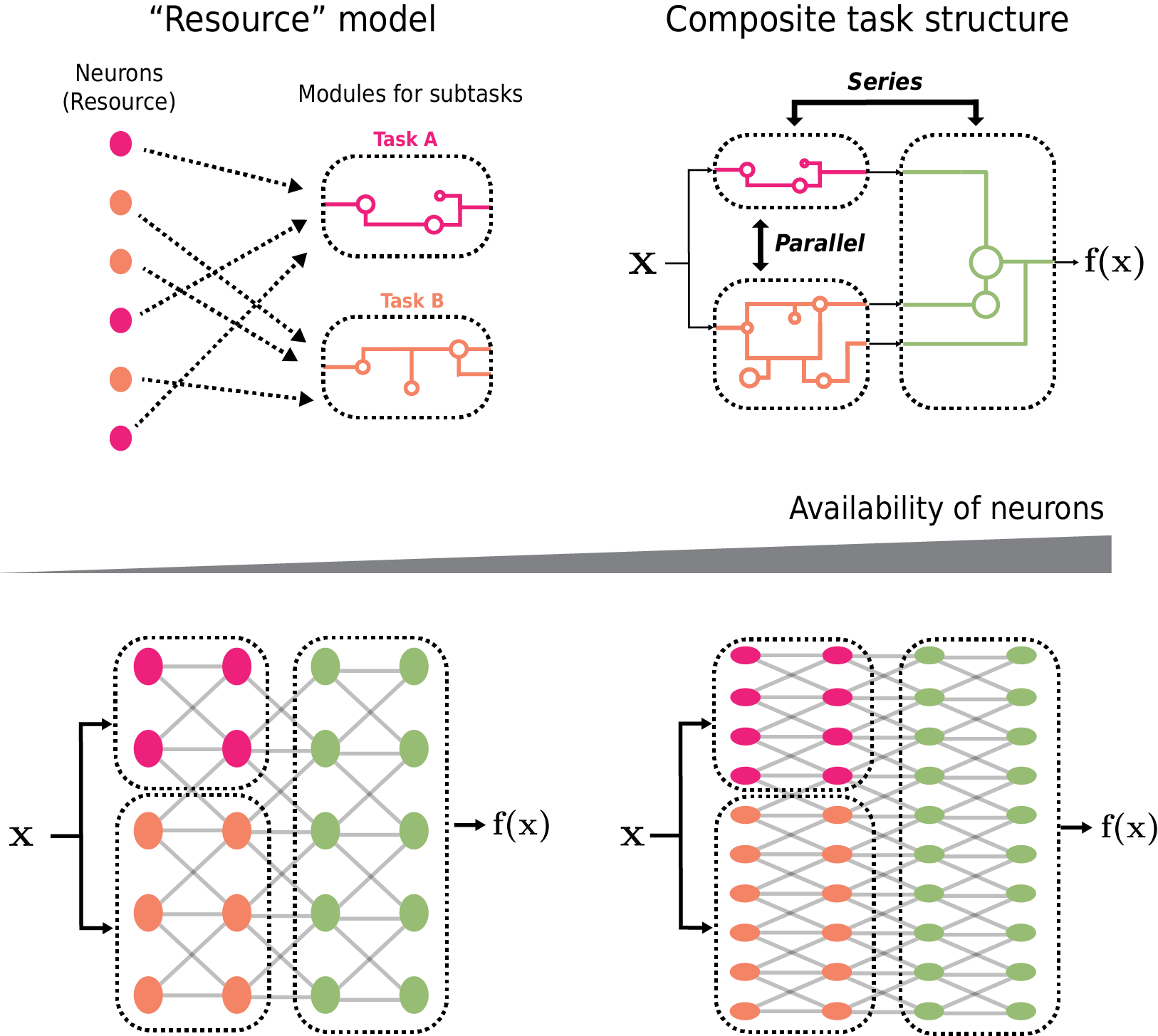
- The model provides insights into the role of neuron redundancy in enabling efficient scaling of composite tasks.
Plain English Explanation
The paper explores the patterns we've observed in how the performance of AI models changes as they are given more computational resources, such as more data, parameters, or compute. These patterns are known as "neural scaling laws." The authors develop a mathematical model to better understand the underlying reasons behind these scaling laws.
Their model focuses on the fundamental constraints and trade-offs that shape how neural networks can be scaled up. For example, there are limits on how much information individual neurons can effectively process, and networks need to balance the specialization of neurons with the redundancy that allows for efficient scaling.
By capturing these key factors in their model, the authors gain insights into why neural networks exhibit the particular scaling behaviors we see in practice. Notably, they show how neuron redundancy plays an important role in enabling efficient scaling when tackling complex, "composite" tasks that require combining multiple sub-skills.
The paper provides a theoretical foundation for understanding the scaling of AI systems, which has important implications for predicting model performance, explaining observed scaling laws, and engineering more scalable AI architectures in the future.
Technical Explanation
The authors propose a resource model for neural networks that captures the key constraints and trade-offs governing their scaling behavior. The model considers factors such as the information processing capacity of individual neurons, the specialization and redundancy of neurons, and the complexity of the task being learned.
Mathematically, the model represents the performance of a neural network as a function of its computational resources (e.g., number of parameters, amount of training data). By incorporating the relevant physical and informational constraints, the authors are able to derive scaling laws that match empirical observations.
For single tasks, the model shows that performance scales sublinearly with resources, due to diminishing returns as network size increases. However, for "composite" tasks that require integrating multiple sub-skills, the authors demonstrate that neuron redundancy can enable more efficient scaling, with performance scaling closer to linearly.
This theoretical work provides a framework for understanding the origins of neural scaling laws and offers insights into how to [engineer AI systems that can benefit from more compute.
Critical Analysis
The resource model presented in this paper offers a principled approach to analyzing neural scaling laws, but it also has some limitations. The authors make simplifying assumptions, such as considering only feedforward neural networks and assuming uniform neuron properties. Real-world neural networks can exhibit more complex architectures and heterogeneous neuron characteristics.
Additionally, the model does not fully account for factors like the role of task-specific inductive biases, the impact of network depth, or the effects of different training regimes. Extending the model to capture these additional elements could further improve its predictive power and provide even deeper insights.
That said, the authors acknowledge these limitations and highlight opportunities for future research to build upon their work. The fundamental concepts and mathematical framework laid out in this paper provide a solid foundation for continued exploration of neural scaling phenomena.
Conclusion
This paper presents a resource model that sheds light on the underlying factors governing the scaling behavior of neural networks. By capturing key constraints and trade-offs, the model offers a principled explanation for empirically observed neural scaling laws.
The insights gained from this work have important implications for the field of AI. The model can help predict the performance of AI systems as they are scaled up, explain the origins of scaling laws, and guide the development of more scalable AI architectures in the future. By shedding light on the fundamental principles underlying neural scaling, this research represents a step towards a deeper understanding of the potential and limitations of large-scale AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Resource Model For Neural Scaling Law
Jinyeop Song, Ziming Liu, Max Tegmark, Jeff Gore
Neural scaling laws characterize how model performance improves as the model size scales up. Inspired by empirical observations, we introduce a resource model of neural scaling. A task is usually composite hence can be decomposed into many subtasks, which compete for resources (measured by the number of neurons allocated to subtasks). On toy problems, we empirically find that: (1) The loss of a subtask is inversely proportional to its allocated neurons. (2) When multiple subtasks are present in a composite task, the resources acquired by each subtask uniformly grow as models get larger, keeping the ratios of acquired resources constants. We hypothesize these findings to be generally true and build a model to predict neural scaling laws for general composite tasks, which successfully replicates the neural scaling law of Chinchilla models reported in arXiv:2203.15556. We believe that the notion of resource used in this paper will be a useful tool for characterizing and diagnosing neural networks.
Read more5/16/2024
0
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
Read more6/26/2024
0
Neural Scaling Laws on Graphs
Jingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, Jiliang Tang
Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the scaling properties of deep graph models have not been systematically investigated, casting doubt on the feasibility of achieving large graph models through enlarging the model and dataset sizes. In this work, we delve into neural scaling laws on graphs from both model and data perspectives. We first verify the validity of such laws on graphs, establishing formulations to describe the scaling behaviors. For model scaling, we investigate the phenomenon of scaling law collapse and identify overfitting as the potential reason. Moreover, we reveal that the model depth of deep graph models can impact the model scaling behaviors, which differ from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively metric the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of edges as the metric to address the irregular graph sizes. We further demonstrate the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an essential step toward large graph models.
Read more6/11/2024

0
Information-Theoretic Foundations for Neural Scaling Laws
Hong Jun Jeon, Benjamin Van Roy
Neural scaling laws aim to characterize how out-of-sample error behaves as a function of model and training dataset size. Such scaling laws guide allocation of a computational resources between model and data processing to minimize error. However, existing theoretical support for neural scaling laws lacks rigor and clarity, entangling the roles of information and optimization. In this work, we develop rigorous information-theoretic foundations for neural scaling laws. This allows us to characterize scaling laws for data generated by a two-layer neural network of infinite width. We observe that the optimal relation between data and model size is linear, up to logarithmic factors, corroborating large-scale empirical investigations. Concise yet general results of the kind we establish may bring clarity to this topic and inform future investigations.
Read more7/2/2024