More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs

0

Sign in to get full access
Overview
• This paper explores integrating general capabilities into domain-specific large language models (LLMs) to address the issue of catastrophic forgetting, where models forget previously learned information when fine-tuned on new tasks.
• The researchers propose a novel approach called "Domain-Specific General Capabilities" (DSGC) that allows LLMs to maintain general capabilities while also specializing in specific domains.
Plain English Explanation
• Large language models (LLMs) are incredibly powerful AI systems that can understand and generate human-like text. However, they can struggle with "catastrophic forgetting" - when they are trained on a new task, they often forget what they've learned from previous tasks.
• The researchers in this paper have come up with a new way to solve this problem. Their approach, called "Domain-Specific General Capabilities" (DSGC), allows LLMs to maintain their general knowledge and skills while also specializing in specific domains or tasks.
• This is important because it means LLMs can be customized for different applications, like writing, analysis, or coding, without losing their broad understanding of language and the world. Continual learning in large language models is a key challenge, and this paper proposes a promising solution.
Technical Explanation
• The researchers' DSGC approach involves training LLMs on a diverse set of tasks to build general capabilities, and then fine-tuning them on specific domains while preserving these capabilities.
• This is achieved through a combination of techniques, including cross-domain continual learning, low-parameter LLM adaptation, and online continual learning.
• The researchers evaluate their approach on a range of benchmark tasks, demonstrating the ability of DSGC-trained LLMs to maintain general capabilities while achieving state-of-the-art performance on domain-specific tasks, in contrast to standard fine-tuning approaches that suffer from catastrophic forgetting.
Critical Analysis
• The paper provides a thorough evaluation of the DSGC approach, but does not address potential scalability issues or the computational cost of the training process.
• Additionally, the researchers acknowledge that their method may not be suitable for all types of domain-specific tasks, and further research is needed to understand the limitations and optimal application areas.
• Overall, the DSGC approach is a promising step towards overcoming the challenge of catastrophic forgetting in LLMs and enabling their deployment in a wider range of real-world applications.
Conclusion
• This paper presents a novel approach called "Domain-Specific General Capabilities" (DSGC) that allows large language models to maintain their general knowledge and capabilities while also specializing in specific domains or tasks.
• By combining techniques like cross-domain continual learning and low-parameter adaptation, the DSGC method addresses the problem of catastrophic forgetting, which has been a significant challenge in the field of continual learning for LLMs.
• The researchers' evaluation demonstrates the effectiveness of DSGC in preserving general capabilities while achieving state-of-the-art performance on domain-specific tasks, opening up new possibilities for the deployment of versatile and customizable LLMs in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs
Chengyuan Liu, Yangyang Kang, Shihang Wang, Lizhi Qing, Fubang Zhao, Changlong Sun, Kun Kuang, Fei Wu
The performance on general tasks decreases after Large Language Models (LLMs) are fine-tuned on domain-specific tasks, the phenomenon is known as Catastrophic Forgetting (CF). However, this paper presents a further challenge for real application of domain-specific LLMs beyond CF, called General Capabilities Integration (GCI), which necessitates the integration of both the general capabilities and domain knowledge within a single instance. The objective of GCI is not merely to retain previously acquired general capabilities alongside new domain knowledge, but to harmonize and utilize both sets of skills in a cohesive manner to enhance performance on domain-specific tasks. Taking legal domain as an example, we carefully design three groups of training and testing tasks without lacking practicability, and construct the corresponding datasets. To better incorporate general capabilities across domain-specific scenarios, we introduce ALoRA, which utilizes a multi-head attention module upon LoRA, facilitating direct information transfer from preceding tokens to the current one. This enhancement permits the representation to dynamically switch between domain-specific knowledge and general competencies according to the attention. Extensive experiments are conducted on the proposed tasks. The results exhibit the significance of our setting, and the effectiveness of our method.
Read more10/3/2024
💬
0
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, Yue Zhang
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge. As large language models (LLMs) have demonstrated remarkable performance, it is intriguing to investigate whether CF exists during the continual instruction tuning of LLMs. This study empirically evaluates the forgetting phenomenon in LLMs' knowledge during continual instruction tuning from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments reveal that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b parameters. Moreover, as the model scale increases, the severity of forgetting intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ exhibits less forgetting and retains more knowledge. Interestingly, we also observe that LLMs can mitigate language biases, such as gender bias, during continual fine-tuning. Furthermore, our findings indicate that ALPACA maintains more knowledge and capacity compared to LLAMA during continual fine-tuning, suggesting that general instruction tuning can help alleviate the forgetting phenomenon in LLMs during subsequent fine-tuning processes.
Read more4/3/2024
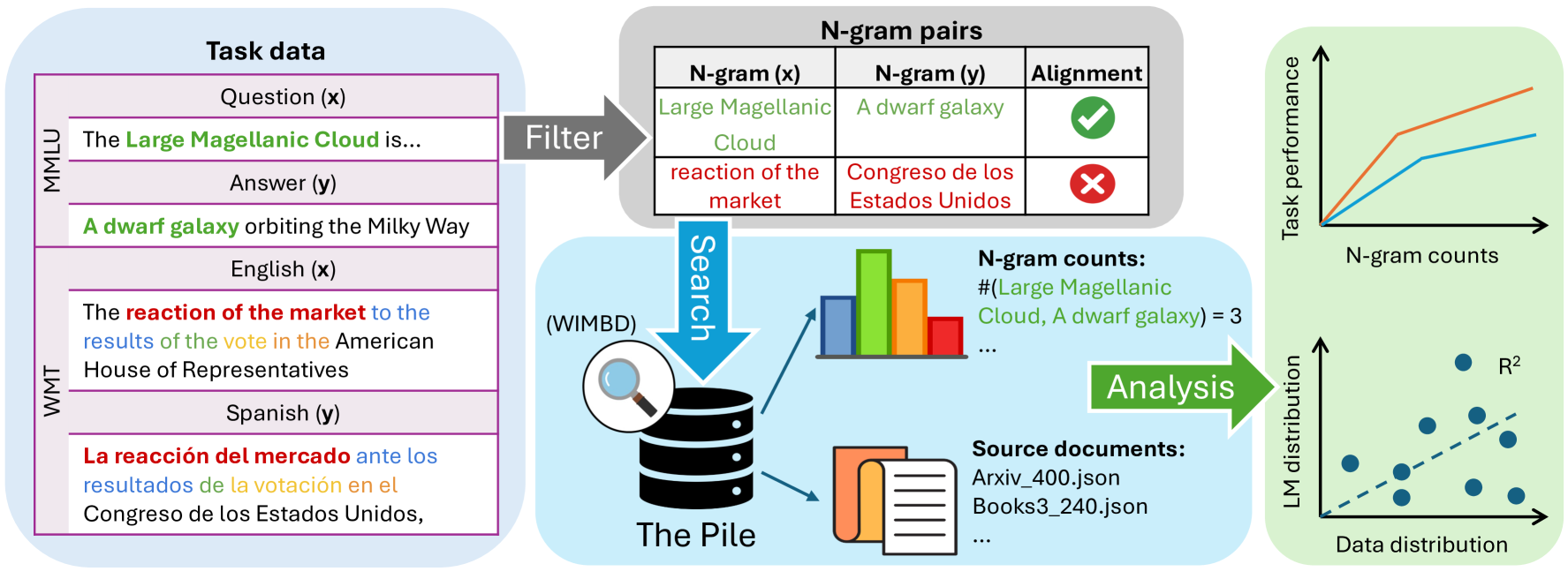
0
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Xinyi Wang, Antonis Antoniades, Yanai Elazar, Alfonso Amayuelas, Alon Albalak, Kexun Zhang, William Yang Wang
The impressive capabilities of large language models (LLMs) have sparked debate over whether these models genuinely generalize to unseen tasks or predominantly rely on memorizing vast amounts of pretraining data. To explore this issue, we introduce an extended concept of memorization, distributional memorization, which measures the correlation between the LLM output probabilities and the pretraining data frequency. To effectively capture task-specific pretraining data frequency, we propose a novel task-gram language model, which is built by counting the co-occurrence of semantically related $n$-gram pairs from task inputs and outputs in the pretraining corpus. Using the Pythia models trained on the Pile dataset, we evaluate three distinct tasks: machine translation, factual question answering, and reasoning. Our findings reveal varying levels of memorization, with the strongest effect observed in factual question answering. Furthermore, while model performance improves across all tasks as LLM size increases, only factual question answering shows an increase in memorization, whereas machine translation and reasoning tasks exhibit greater generalization, producing more novel outputs. This study demonstrates that memorization plays a larger role in simpler, knowledge-intensive tasks, while generalization is the key for harder, reasoning-based tasks, providing a scalable method for analyzing large pretraining corpora in greater depth.
Read more10/4/2024

0
Revisiting Catastrophic Forgetting in Large Language Model Tuning
Hongyu Li, Liang Ding, Meng Fang, Dacheng Tao
Catastrophic Forgetting (CF) means models forgetting previously acquired knowledge when learning new data. It compromises the effectiveness of large language models (LLMs) during fine-tuning, yet the underlying causes have not been thoroughly investigated. This paper takes the first step to reveal the direct link between the flatness of the model loss landscape and the extent of CF in the field of LLMs. Based on this, we introduce the sharpness-aware minimization to mitigate CF by flattening the loss landscape. Experiments on three widely-used fine-tuning datasets, spanning different model scales, demonstrate the effectiveness of our method in alleviating CF. Analyses show that we nicely complement the existing anti-forgetting strategies, further enhancing the resistance of LLMs to CF.
Read more6/10/2024