Hallucination Mitigation Prompts Long-term Video Understanding

0

Sign in to get full access
Overview
- This research paper explores a novel approach to mitigating hallucination in long-term video understanding tasks.
- The proposed method leverages prompting techniques to improve the performance of large language models in maintaining coherence and consistency over extended video sequences.
- The findings suggest that hallucination mitigation can lead to significant gains in long-term video understanding capabilities, with potential applications in areas like video summarization, question-answering, and task completion.
Plain English Explanation
Hallucination is a common problem in large language models, where the model generates content that is plausible but factually incorrect or inconsistent. This can be particularly challenging when working with long video sequences, where the model needs to maintain a coherent understanding of the events, characters, and context over an extended period.
The researchers in this paper propose a novel approach to address this issue. They use "prompting" techniques, which involve providing the model with additional contextual information or guidance to help it stay on track and avoid hallucination. By carefully crafting these prompts, the researchers were able to significantly improve the model's performance on long-term video understanding tasks, such as summarizing the key events in a video or answering questions about the content.
This is an important advancement, as the ability to reliably understand and reason about long video sequences has many practical applications, from helping virtual assistants carry out complex multi-step tasks to creating more engaging and informative video content summaries. By mitigating hallucination, the researchers have taken a significant step towards improving the long-term video understanding capabilities of large language models.
Technical Explanation
The researchers propose a hallucination mitigation approach for long-term video understanding tasks. They leverage prompting techniques to guide the model's behavior and maintain coherence over extended video sequences.
The key elements of their methodology include:
-
Prompt Engineering: The researchers carefully craft prompts that provide the model with additional context, constraints, or guidance to help it stay focused and avoid hallucination. These prompts can include information about the video's storyline, characters, or broader context.
-
Memory Augmentation: To further enhance the model's ability to maintain a consistent understanding over time, the researchers incorporate memory-augmented neural network architectures, such as MA-LMM, which can better retain and reason about long-term dependencies.
-
Iterative Refinement: The model's outputs are continuously refined through an iterative process, where the model's previous responses are used to update the prompts and guide the subsequent generations, further reducing hallucination.
The researchers evaluate their approach on a range of long-term video understanding tasks, including video summarization, question-answering, and task completion. Their results demonstrate significant improvements in performance and coherence compared to baseline models, highlighting the effectiveness of their hallucination mitigation techniques.
Critical Analysis
The researchers have made a valuable contribution to the field of long-term video understanding, addressing a crucial challenge in the deployment of large language models in real-world applications. However, there are a few areas that could benefit from further exploration:
-
Scalability: While the proposed approach shows promise on the evaluated tasks, it's unclear how well it would scale to even longer or more complex video sequences. The researchers mention the need for further research to understand the limits of their techniques.
-
Generalization: The paper focuses on a specific set of tasks and datasets. It would be interesting to see how well the hallucination mitigation methods generalize to a broader range of long-term video understanding problems, including more open-ended or multi-modal tasks.
-
Interpretability: The prompting and memory augmentation techniques employed in this work can be seen as "black boxes" to some extent. Exploring ways to make the model's reasoning more interpretable could enhance trust and facilitate further improvements.
-
Real-world Deployment: While the research demonstrates significant performance gains in a controlled setting, the challenges of deploying such systems in real-world scenarios, such as handling noisy or incomplete input data, remain an important area for future work.
Overall, this paper presents a promising approach to mitigating hallucination in long-term video understanding, with meaningful implications for a wide range of applications. Continued research in this direction could lead to more robust and reliable large language models capable of consistently understanding and reasoning about complex, extended video content.
Conclusion
This research paper introduces a novel hallucination mitigation approach for improving the long-term video understanding capabilities of large language models. By leveraging prompting techniques and memory-augmented architectures, the researchers were able to significantly enhance the models' ability to maintain coherence and consistency over extended video sequences.
The findings suggest that hallucination mitigation is a crucial step in unlocking the full potential of large language models for a variety of video-related applications, from video summarization and question-answering to multi-step task completion and efficient video content analysis. As the field continues to evolve, further research in this direction could lead to more reliable and trustworthy large language models capable of truly long-term video understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hallucination Mitigation Prompts Long-term Video Understanding
Yiwei Sun, Zhihang Liu, Chuanbin Liu, Bowei Pu, Zhihan Zhang, Hongtao Xie
Recently, multimodal large language models have made significant advancements in video understanding tasks. However, their ability to understand unprocessed long videos is very limited, primarily due to the difficulty in supporting the enormous memory overhead. Although existing methods achieve a balance between memory and information by aggregating frames, they inevitably introduce the severe hallucination issue. To address this issue, this paper constructs a comprehensive hallucination mitigation pipeline based on existing MLLMs. Specifically, we use the CLIP Score to guide the frame sampling process with questions, selecting key frames relevant to the question. Then, We inject question information into the queries of the image Q-former to obtain more important visual features. Finally, during the answer generation stage, we utilize chain-of-thought and in-context learning techniques to explicitly control the generation of answers. It is worth mentioning that for the breakpoint mode, we found that image understanding models achieved better results than video understanding models. Therefore, we aggregated the answers from both types of models using a comparison mechanism. Ultimately, We achieved 84.2% and 62.9% for the global and breakpoint modes respectively on the MovieChat dataset, surpassing the official baseline model by 29.1% and 24.1%. Moreover the proposed method won the third place in the CVPR LOVEU 2024 Long-Term Video Question Answering Challenge. The code is avaiable at https://github.com/lntzm/CVPR24Track-LongVideo
Read more6/18/2024
0
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
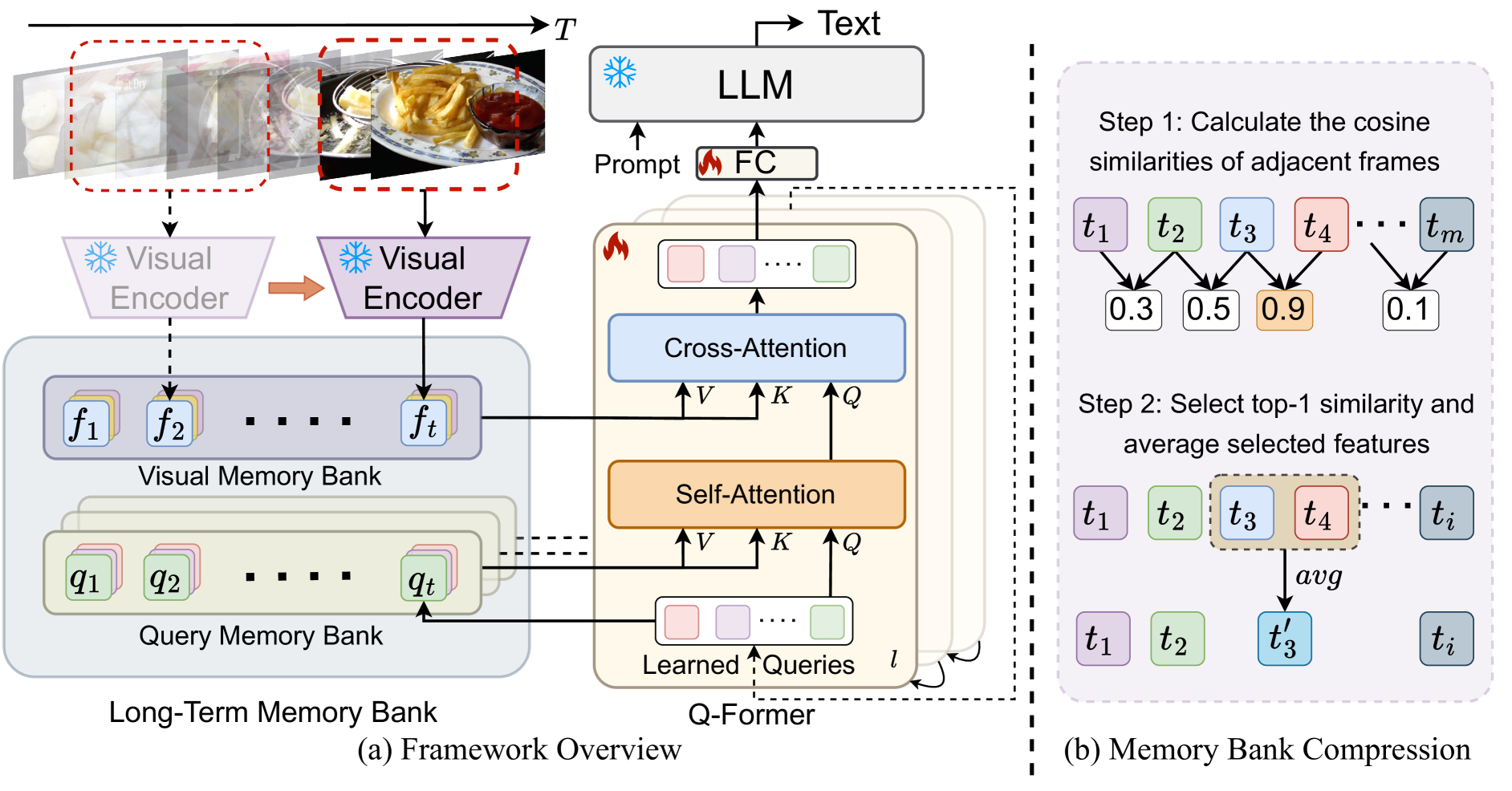
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Read more4/9/2024
0
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
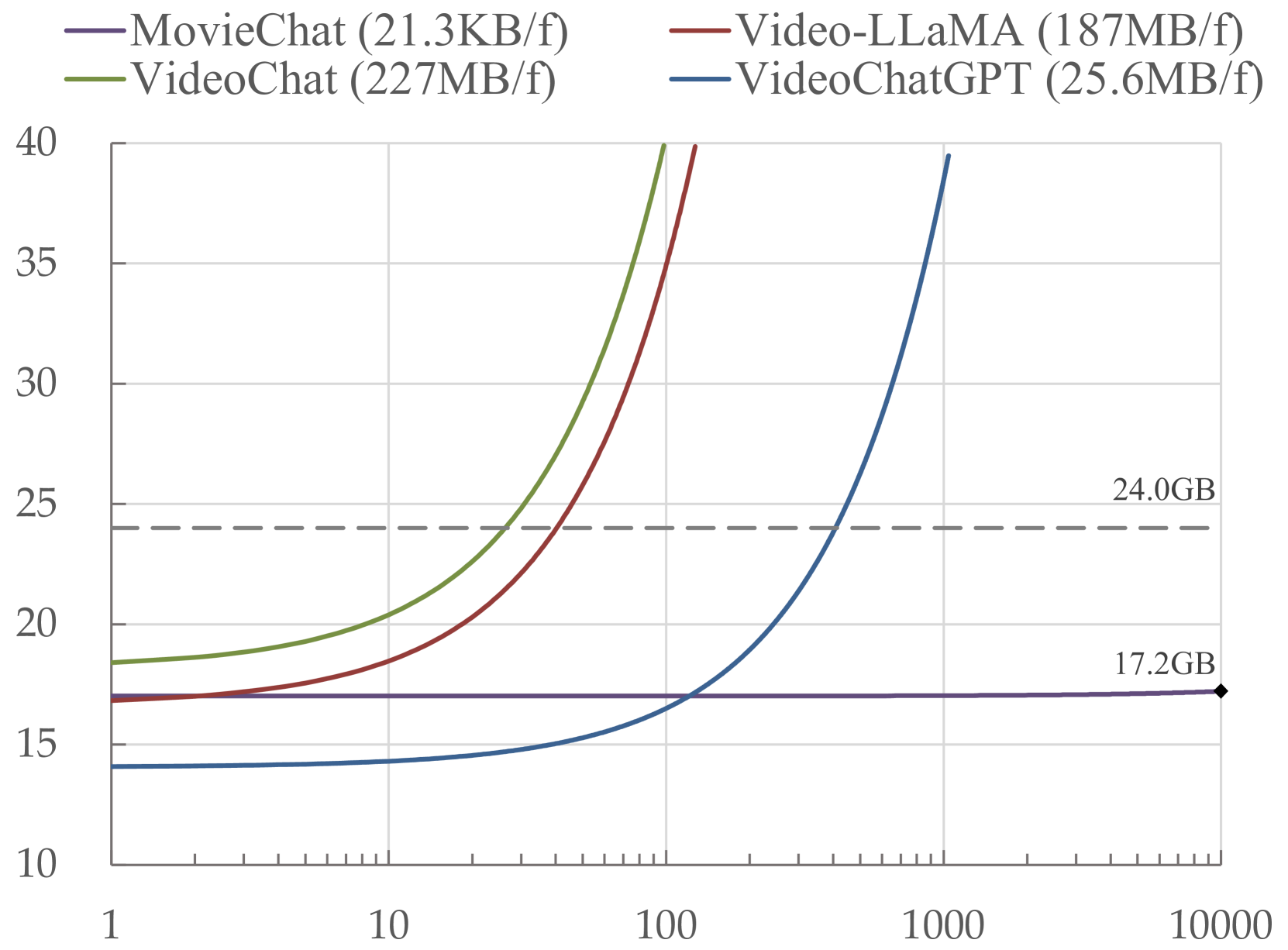
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
Read more4/29/2024

0
A Unified Hallucination Mitigation Framework for Large Vision-Language Models
Yue Chang, Liqiang Jing, Xiaopeng Zhang, Yue Zhang
Hallucination is a common problem for Large Vision-Language Models (LVLMs) with long generations which is difficult to eradicate. The generation with hallucinations is partially inconsistent with the image content. To mitigate hallucination, current studies either focus on the process of model inference or the results of model generation, but the solutions they design sometimes do not deal appropriately with various types of queries and the hallucinations of the generations about these queries. To accurately deal with various hallucinations, we present a unified framework, Dentist, for hallucination mitigation. The core step is to first classify the queries, then perform different processes of hallucination mitigation based on the classification result, just like a dentist first observes the teeth and then makes a plan. In a simple deployment, Dentist can classify queries as perception or reasoning and easily mitigate potential hallucinations in answers which has been demonstrated in our experiments. On MMbench, we achieve a 13.44%/10.2%/15.8% improvement in accuracy on Image Quality, a Coarse Perception visual question answering (VQA) task, over the baseline InstructBLIP/LLaVA/VisualGLM.
Read more9/26/2024