Optimizing Language Models for Human Preferences is a Causal Inference Problem
2402.14979
0
0

Abstract
As large language models (LLMs) see greater use in academic and commercial settings, there is increasing interest in methods that allow language models to generate texts aligned with human preferences. In this paper, we present an initial exploration of language model optimization for human preferences from direct outcome datasets, where each sample consists of a text and an associated numerical outcome measuring the reader's response. We first propose that language model optimization should be viewed as a causal problem to ensure that the model correctly learns the relationship between the text and the outcome. We formalize this causal language optimization problem, and we develop a method--causal preference optimization (CPO)--that solves an unbiased surrogate objective for the problem. We further extend CPO with doubly robust CPO (DR-CPO), which reduces the variance of the surrogate objective while retaining provably strong guarantees on bias. Finally, we empirically demonstrate the effectiveness of (DR-)CPO in optimizing state-of-the-art LLMs for human preferences on direct outcome data, and we validate the robustness of DR-CPO under difficult confounding conditions.
Create account to get full access
Overview
- This paper argues that optimizing language models to align with human preferences is a causal inference problem.
- It explores different approaches to preference optimization, including direct preference optimization, hybrid preference optimization, and soft preference optimization.
- The paper discusses the challenges of language model optimization and aligning language models to human preferences.
Plain English Explanation
The paper examines the problem of training language models to behave in ways that align with human preferences. The key insight is that this is fundamentally a causal inference problem - we need to understand the causal relationships between the model's outputs and the humans' preferences in order to optimize the model effectively.
The paper explores several different approaches to preference optimization, each with its own strengths and limitations. Direct preference optimization, for example, tries to directly learn a mapping between the model's outputs and human preferences. Hybrid approaches combine direct optimization with other techniques. And soft preference optimization aims to shape the model's behavior more indirectly.
Ultimately, the core challenge is that human preferences can be complex, context-dependent, and hard to measure or observe directly. The paper argues that addressing this challenge through causal modeling is key to building language models that truly align with what humans want.
Technical Explanation
The paper frames the problem of optimizing language models for human preferences as a causal inference task. The key insight is that to align the model's outputs with human preferences, we need to understand the causal relationships between the model's behavior and the resulting preferences.
The paper surveys several approaches to preference optimization. Direct preference optimization tries to learn a direct mapping from the model's outputs to human preferences, but faces challenges with unobserved preference heterogeneity. Hybrid approaches combine direct optimization with other techniques like reward modeling. And soft preference optimization aims to shape the model's behavior more indirectly.
The paper also discusses the broader challenges of language model optimization and aligning language models to human preferences. These include the difficulty of measuring and observing human preferences, as well as the complex and contextual nature of preference formation.
Critical Analysis
The paper makes a compelling case that preference optimization for language models is fundamentally a causal inference problem. This framing highlights important challenges, such as unobserved preference heterogeneity, that may be overlooked in more straightforward optimization approaches.
However, the paper does not provide a complete solution to these challenges. The various preference optimization approaches discussed all have significant limitations, and the paper does not offer a clear path forward. More research is likely needed to develop robust causal models of human preferences and how they interact with language model outputs.
Additionally, the paper focuses primarily on the technical challenges of preference optimization, but does not delve deeply into the broader societal implications. As language models become more powerful and influential, it will be critical to consider the ethical implications of optimizing their behavior to align with human preferences, which may not always be benign or universally beneficial.
Conclusion
This paper makes an important contribution by framing the challenge of optimizing language models for human preferences as a causal inference problem. By highlighting the complexity of human preferences and the need to understand their causal relationships with model outputs, the paper points the way toward more principled and effective approaches to preference optimization.
However, significant work remains to be done, both in developing the technical tools for causal modeling of preferences, and in considering the broader societal implications of this line of research. As language models grow more influential, it will be crucial to ensure that their optimization is guided by a deep understanding of human values and the potential consequences of aligning their behavior accordingly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multi-Reference Preference Optimization for Large Language Models
Hung Le, Quan Tran, Dung Nguyen, Kien Do, Saloni Mittal, Kelechi Ogueji, Svetha Venkatesh
0
0
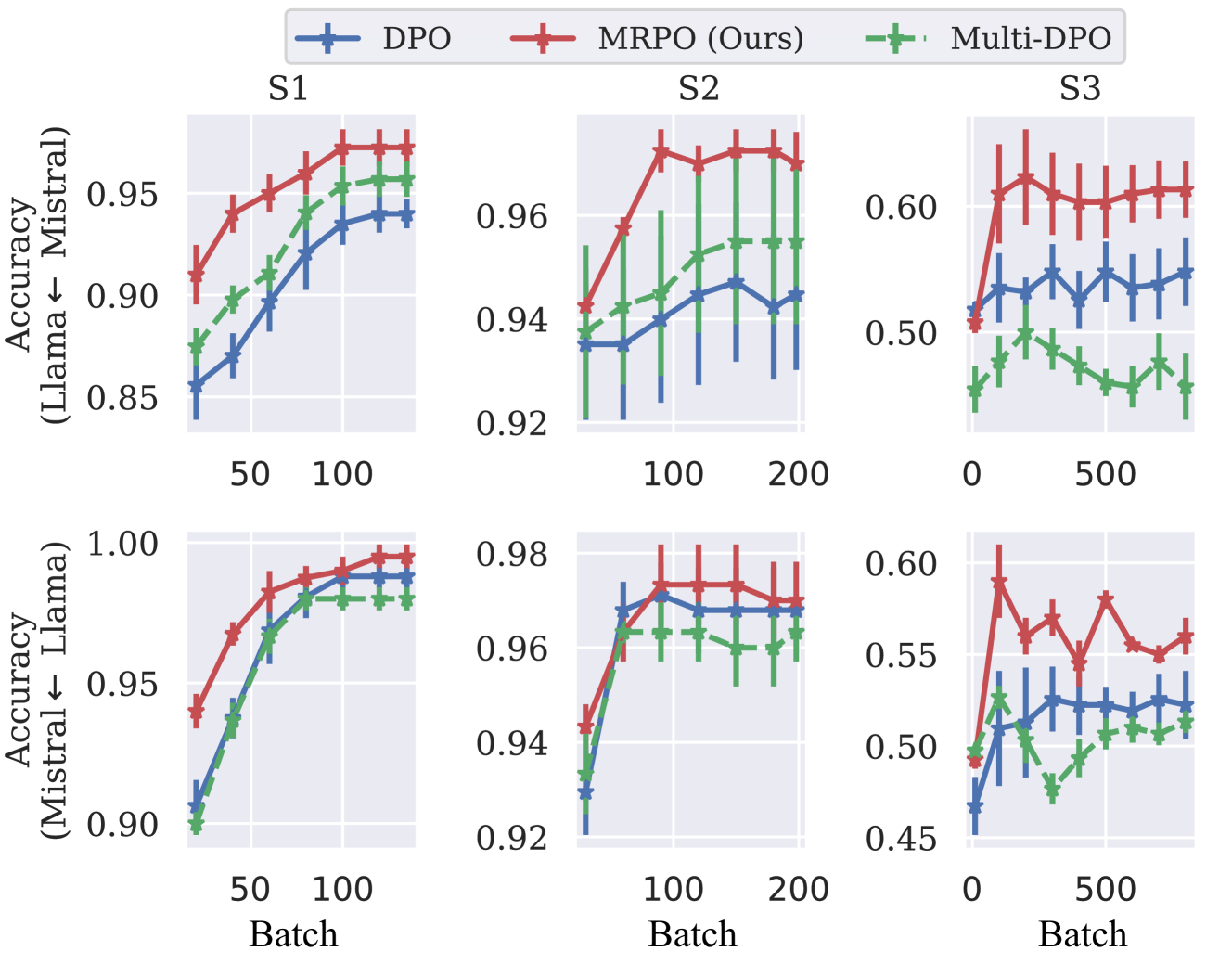
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
5/28/2024
Discovering Preference Optimization Algorithms with and for Large Language Models
Chris Lu, Samuel Holt, Claudio Fanconi, Alex J. Chan, Jakob Foerster, Mihaela van der Schaar, Robert Tjarko Lange
0
0
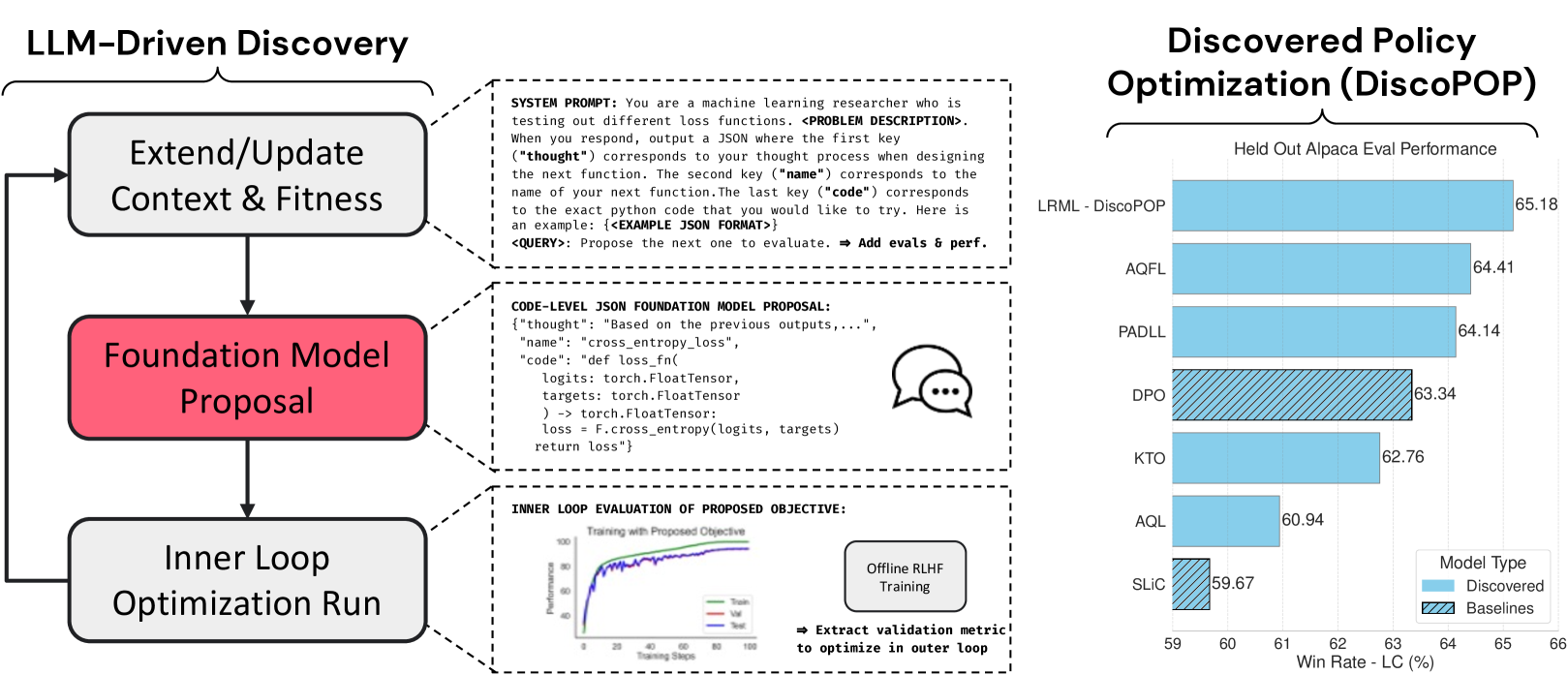
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually-crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under explored. We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
6/13/2024
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Arsalan Sharifnassab, Sina Ghiassian, Saber Salehkaleybar, Surya Kanoria, Dale Schuurmans
0
0
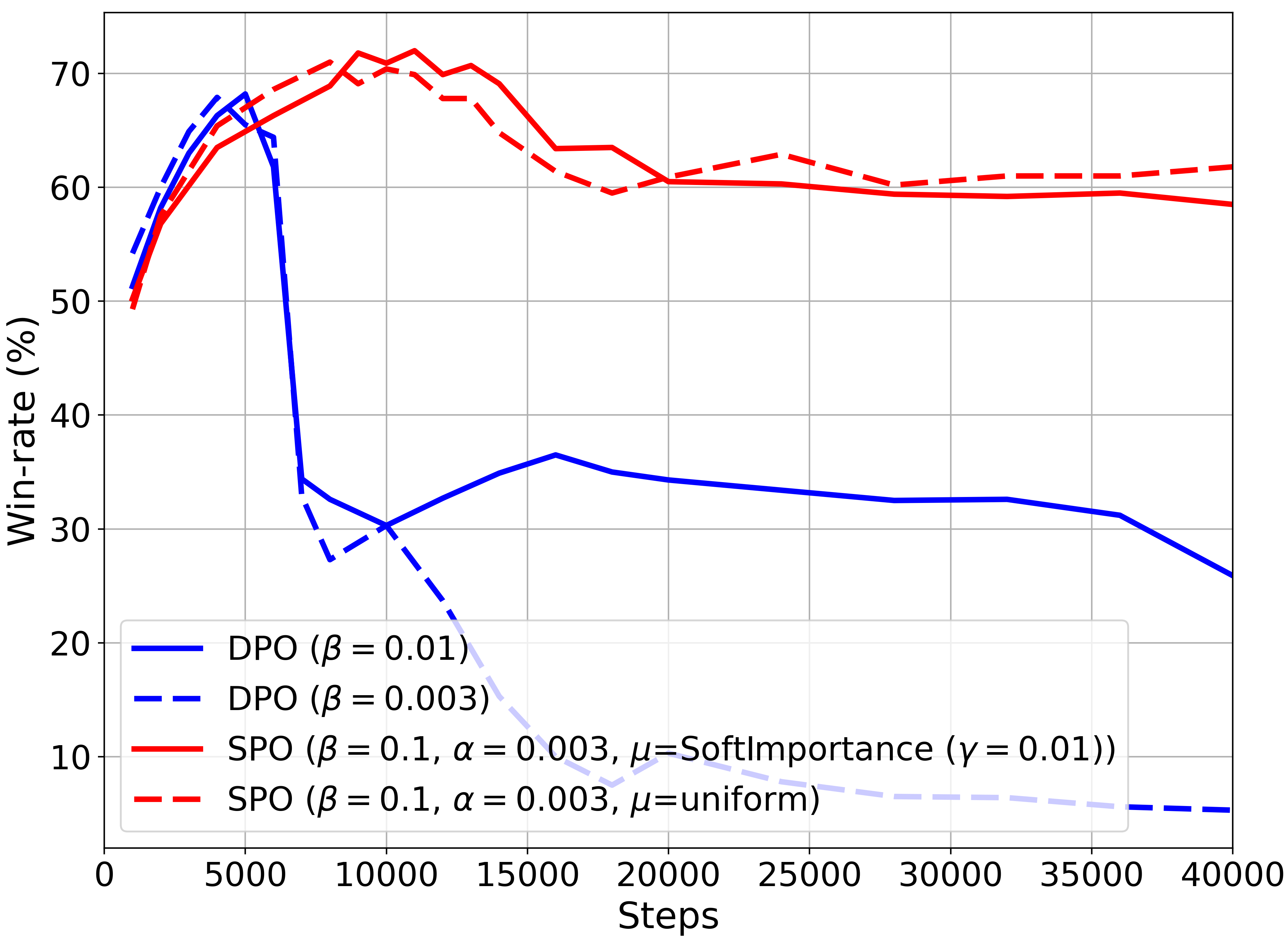
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's softness adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
5/29/2024